[04]tensorflow实现CNN
2016-07-12 10:21
253 查看
背景
softmax在MNIST数据集上的正确率只有91%,不是很好,在这里,我们用卷积神经网络(Convolutional Neural Network,CNN)来改善效果。这会达到大概99.2%的准确率。权重初始化
为了创建这个模型,我们需要创建大量的权重和偏置项。这个模型中的权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度。由于我们使用的是ReLU(线性纠正函数)神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。为了不在建立模型的时候反复做初始化操作,我们定义两个函数用于初始化。def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)
卷积和池化
TensorFlow在卷积和池化上有很强的灵活性。我们怎么处理边界?步长应该设多大?在这个实例里,我们会一直使用vanilla版本。我们的卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。我们的池化用简单传统的2x2大小的模板做max pooling。为了代码更简洁,我们把这部分抽象成一个函数。def conv2d(x,w): return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding = "SAME") def max_pool_2x2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1], strides=[1,2,2,1],padding = "SAME")
第一层卷积
现在我们可以开始实现第一层了。它由一个卷积接一个max pooling完成。卷积在每个5x5的patch中算出32个特征。卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于每一个输出通道都有一个对应的偏置量。W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32])
为了用这一层,我们把x变成一个4d向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3)。
x_image = tf.reshape(x, [-1,28,28,1])
我们把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1)
第二层卷积
为了构建一个更深的网络,我们会把几个类似的层堆叠起来。第二层中,每个5x5的patch会得到64个特征。W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2)
全连接层
现在,图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片。我们把池化层输出的张量reshape成一些向量,乘上权重矩阵,加上偏置,然后对其使用ReLU。W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
Dropout
为了减少过拟合,我们在输出层之前加入dropout。我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale。所以用dropout的时候可以不用考虑scale。keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)输出层
最后,我们添加一个softmax层,就像前面的单层softmax regression一样。W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
训练和评估模型
为了进行训练和评估,我们使用与之前简单的单层SoftMax神经网络模型几乎相同的一套代码,只是我们会用更加复杂的ADAM优化器来做梯度最速下降,在feed_dict中加入额外的参数keep_prob来控制dropout比例。然后每100次迭代输出一次日志。cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
with tf.device("/cpu:0"):
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})结果
迭代: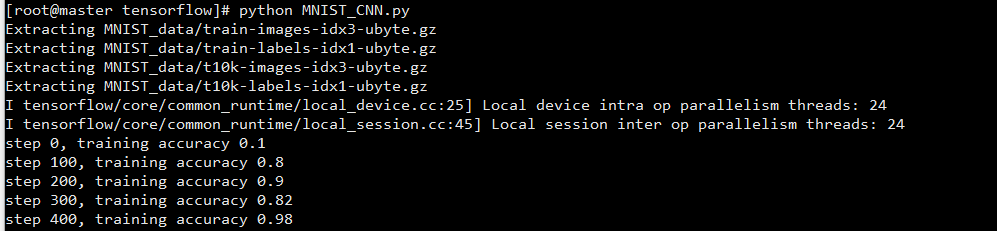
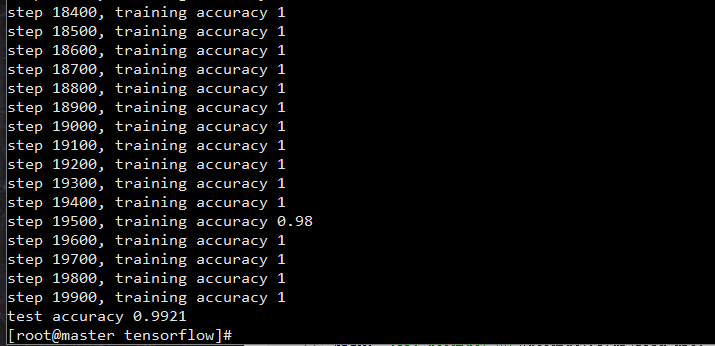
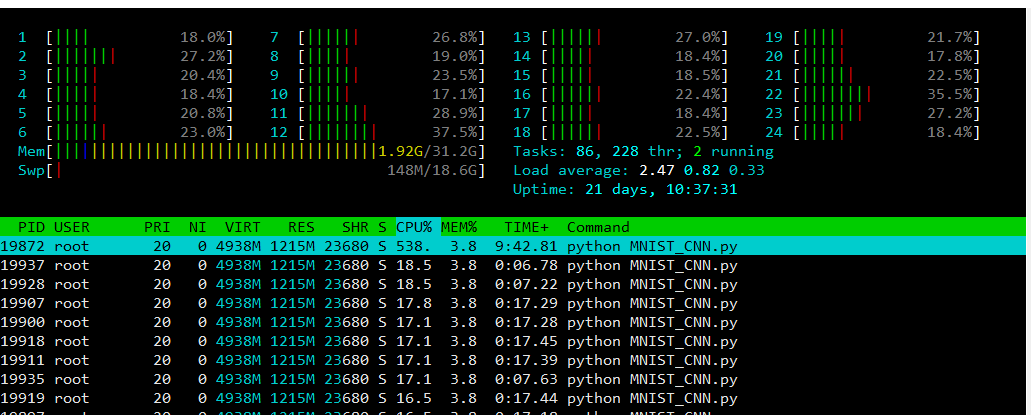
系统资源使用情况:

相关文章推荐
- TensorFlow 的简单例子
- CUDA搭建
- 卷积神经网络初探
- 深入理解CNN的细节
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能入门教程之十一 最强网络DLSTM 双向长短期记忆网络(阿里小AI实现)
- TensorFlow人工智能引擎入门教程之十二 Caffe转换tensorflow并 跨平台调用
- TensorFlow人工智能入门教程之十三 RCNN 区域卷积网络(视频侦测分析人脸侦测区域检测 )
- TensorFlow人工智能入门教程之十四 自动编码机AutoEncoder 网络
- TensorFlow人工智能引擎入门教程所有目录
- Tensorflow 问题
- Tensorflow 深度学习分布式实现方式
- tensorflow入门MNIST回归模型
- tensorflow入门简单卷积神经网络
- convolutional neural network
- UFLDL Exercise: Convolutional Neural Network
- 使用深度卷积网络和支撑向量机实现的商标检测与分类的例子
- httpclient