TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
2016-04-24 18:06
1376 查看
这几天空余时间玩了2天的单机游戏。 黑暗之魂,手柄玩起来挺爽, 这一章节我们讲一下 循环神经网络,RNN 是一种非常通用的神经网络,无论是图像识别 还是 声音识别 文字识别 NLP 时间系列的数据 周期的数据 等等都是通用适合的.
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关.比如 图片 如果28x28像素 如果我们把每一行像素跟上一行的像素 看做时间系列处理的话,也就是 在传统的神经网络WX+B 引入了t 每一个时间系列 t范围内,下一次的w 通过上一个t-1 的wx+b得到 w 所以 图像如果使用RNN处理适合 图像理解 效果很好,NLP 效果也很好。
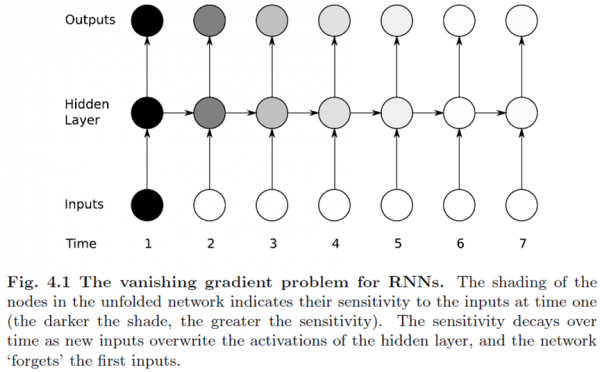

详细的介绍 可以看这个http://www.360doc.com/content/16/0328/15/1317564_545892642.shtml
下面看看RNN输入, 首先seq/step 时间系列 ,如果28x28的图像 RNN处理的话,其实就是每一个seq/step=28长度 28的输入,所以 对于tensorflow 来说输入维度
下面 我们看看 输入的X为【size_batches,input] 要转换成上面的格式 所以需要reshape 重新维度
xdata.reshape((batch_size, n_steps, n_input)) 转换成 [batch,28,28] 其实28个t 上下文计算 最后的t得到输出的w b 用于全连接。也就说28步 step
所以下面我们来看看tensorflow定义 对于RNN 来说我们需要的是一个 step=28的 的(batchsize,n_input) 一层一层上下文计算。对于每一个step得到相应的state 状态 以及 output下一层连接层的输入,得到最后一个上下文来进入连接层的输入。

下面介绍介个函数tensorflow 中 用于颠倒交换维度的
上面 对于3维的X 默认是 0 1 2 系数 ,我们把它置换成1 0 2 也就是 第一维 第二维进行交换
比如 (batch_size, n_steps, n_input) 交换后就是 (nsteps,batch_size,n_input) 这正好就是我们上面需要的28步step的
(batch_size,n_input)的输入。但是这是三维的数组 所以需要降维重新展开reshape
tf.reshape(_X, [-1, n_input]) 这里我讲一下 reshape 就是重新展开 定义维度。-1 表示站位,比如 一个多维的数组,[2 ,2 ,3] 的维度的3维数组,reshape(【-1,3】) 表示要变成 后面维度为3 那么前面的-1 表示全部展开后,除掉 3 那么其实就是shape(4,3) 的维度 二维数组。
所以上面的我们只需要reshape([-1, n_input]) 那么 此时将会的到一个(n_steps*batch_size, n_input)
下面的就遵循矩阵运算 WX+B一步一步即可 最后每一个28step 的每一个step得到一个outpput 根据上下文 上文计算下文的w 所以 最后的输出 就是最后一个元素得到的w 将会最后进行全连接连接层wx+b。
下面看看官方案例的一个例子 。 此时 把图像 从 28x28 当做一个 28 step的 28 input的 RNN ,就好像记忆一样,我们现在所有的决定 都是过去的经验经历 记忆所影响的。 后面有一个RNN上 的变体,LSTM 长短期记忆网络 解决了RNN的缺点 ,对RNN隐藏层 进行改进
这里我们把RNN/LSTM 放在一起 ,是因为他本质是一样的 。
LSTM 就是把RNN的单元 换了更好的单元 就是加上了记忆。所以LSTM 长短期记忆网络
长期是通过遗忘门进行调节。 短期是通过记忆门进行调节。
LSTM引入了Cell 与其说LSTM是一种RNN结构,倒不如说LSTM是RNN的一个魔改组件,把上面看到的网络中的小圆圈换成下面的LSTM的结构

下面我们来运行测试。
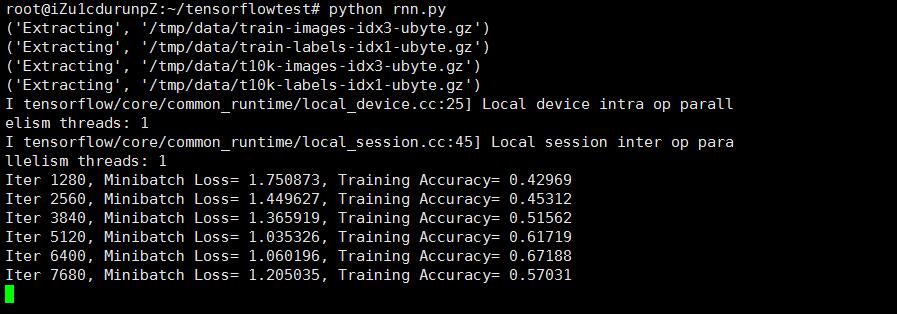
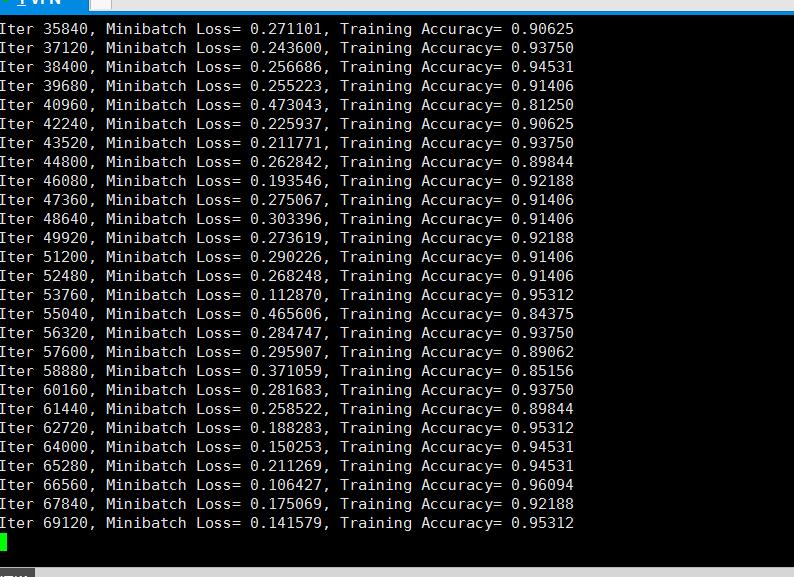
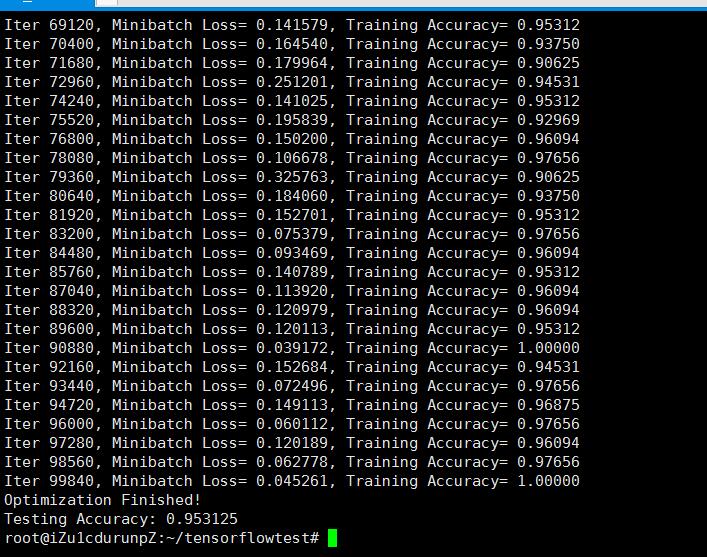
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关.比如 图片 如果28x28像素 如果我们把每一行像素跟上一行的像素 看做时间系列处理的话,也就是 在传统的神经网络WX+B 引入了t 每一个时间系列 t范围内,下一次的w 通过上一个t-1 的wx+b得到 w 所以 图像如果使用RNN处理适合 图像理解 效果很好,NLP 效果也很好。
详细的介绍 可以看这个http://www.360doc.com/content/16/0328/15/1317564_545892642.shtml
下面看看RNN输入, 首先seq/step 时间系列 ,如果28x28的图像 RNN处理的话,其实就是每一个seq/step=28长度 28的输入,所以 对于tensorflow 来说输入维度
[size_batches, seq_length, rnn_size]
下面 我们看看 输入的X为【size_batches,input] 要转换成上面的格式 所以需要reshape 重新维度
xdata.reshape((batch_size, n_steps, n_input)) 转换成 [batch,28,28] 其实28个t 上下文计算 最后的t得到输出的w b 用于全连接。也就说28步 step
所以下面我们来看看tensorflow定义 对于RNN 来说我们需要的是一个 step=28的 的(batchsize,n_input) 一层一层上下文计算。对于每一个step得到相应的state 状态 以及 output下一层连接层的输入,得到最后一个上下文来进入连接层的输入。
下面介绍介个函数tensorflow 中 用于颠倒交换维度的
_X = tf.transpose(_X, [1, 0, 2])
上面 对于3维的X 默认是 0 1 2 系数 ,我们把它置换成1 0 2 也就是 第一维 第二维进行交换
比如 (batch_size, n_steps, n_input) 交换后就是 (nsteps,batch_size,n_input) 这正好就是我们上面需要的28步step的
(batch_size,n_input)的输入。但是这是三维的数组 所以需要降维重新展开reshape
tf.reshape(_X, [-1, n_input]) 这里我讲一下 reshape 就是重新展开 定义维度。-1 表示站位,比如 一个多维的数组,[2 ,2 ,3] 的维度的3维数组,reshape(【-1,3】) 表示要变成 后面维度为3 那么前面的-1 表示全部展开后,除掉 3 那么其实就是shape(4,3) 的维度 二维数组。
所以上面的我们只需要reshape([-1, n_input]) 那么 此时将会的到一个(n_steps*batch_size, n_input)
下面的就遵循矩阵运算 WX+B一步一步即可 最后每一个28step 的每一个step得到一个outpput 根据上下文 上文计算下文的w 所以 最后的输出 就是最后一个元素得到的w 将会最后进行全连接连接层wx+b。
下面看看官方案例的一个例子 。 此时 把图像 从 28x28 当做一个 28 step的 28 input的 RNN ,就好像记忆一样,我们现在所有的决定 都是过去的经验经历 记忆所影响的。 后面有一个RNN上 的变体,LSTM 长短期记忆网络 解决了RNN的缺点 ,对RNN隐藏层 进行改进
这里我们把RNN/LSTM 放在一起 ,是因为他本质是一样的 。
LSTM 就是把RNN的单元 换了更好的单元 就是加上了记忆。所以LSTM 长短期记忆网络
长期是通过遗忘门进行调节。 短期是通过记忆门进行调节。
LSTM引入了Cell 与其说LSTM是一种RNN结构,倒不如说LSTM是RNN的一个魔改组件,把上面看到的网络中的小圆圈换成下面的LSTM的结构
import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
import tensorflow as tf
from tensorflow.models.rnn import rnn, rnn_cell
import numpy as np
'''
To classify images using a reccurent neural network, we consider every image row as a sequence of pixels.
Because MNIST image shape is 28*28px, we will then handle 28 sequences of 28 steps for every sample.
'''
# Parameters
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10
# Network Parameters
n_input = 28 # MNIST data input (img shape: 28*28)
n_steps = 28 # timesteps
n_hidden = 128 # hidden layer num of features
n_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
# Tensorflow LSTM cell requires 2x n_hidden length (state & cell)
istate = tf.placeholder("float", [None, 2*n_hidden])
y = tf.placeholder("float", [None, n_classes])
# Define weights
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
def RNN(_X, _istate, _weights, _biases):
_X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size
_X = tf.reshape(_X, [-1, n_input]) # (n_steps*batch_size, n_input)
_X = tf.matmul(_X, _weights['hidden']) + _biases['hidden']
lstm_cell = rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0)
_X = tf.split(0, n_steps, _X) # n_steps * (batch_size, n_hidden)
outputs, states = rnn.rnn(lstm_cell, _X, initial_state=_istate)
# Get inner loop last output
return tf.matmul(outputs[-1], _weights['out']) + _biases['out']
pred = RNN(x, istate, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # Softmax loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
batch_xs = batch_xs.reshape((batch_size, n_steps, n_input))
# Fit training using batch data
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2*n_hidden))})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2*n_hidden))})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2*n_hidden))})
print "Iter " + str(step*batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + \
", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
# Calculate accuracy for 256 mnist test images
test_len = 256
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label,
istate: np.zeros((test_len, 2*n_hidden))})下面我们来运行测试。

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- CUDA搭建
- 反向传播(Backpropagation)算法的数学原理
- 稀疏自动编码器 (Sparse Autoencoder)
- 白化(Whitening):PCA vs. ZCA
- softmax回归
- 卷积神经网络初探
- 关于SVM的那点破事
- 也谈 机器学习到底有没有用 ?
- AI和IA之随想
- [论文回顾] LSTM:A Search Space Odyssey
- TensorFlow人工智能引擎入门教程所有目录
- 人工智能冲击下,IT人员如何提前避免被淘汰?
- 你的车有了这样的车载操作系统,溜到飞起
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐
- 稀疏编码(Sparse Coding)的前世今生(一) 转自http://blog.csdn.net/marvin521/article/details/8980853