ES-Hadoop学习笔记-初识
2016-06-27 00:30
639 查看
ES-Hadoop是连接快速查询和大数据分析的桥梁,它能够无间隙的在Hadoop和ElasticSearch上移动数据。ES Hadoop索引Hadoop数据到Elasticsearch,充分利用其查询速度,大量聚合能力来使它比以往更快,同时可以使用HDFS作为Elasticsearch长期存档。ES-Hadoop可以本地集成Hadoop生态系统上的很多流行组件,比如Spark、Hive、Pig、Storm、MapReduce等。官方有张图可以很好说明
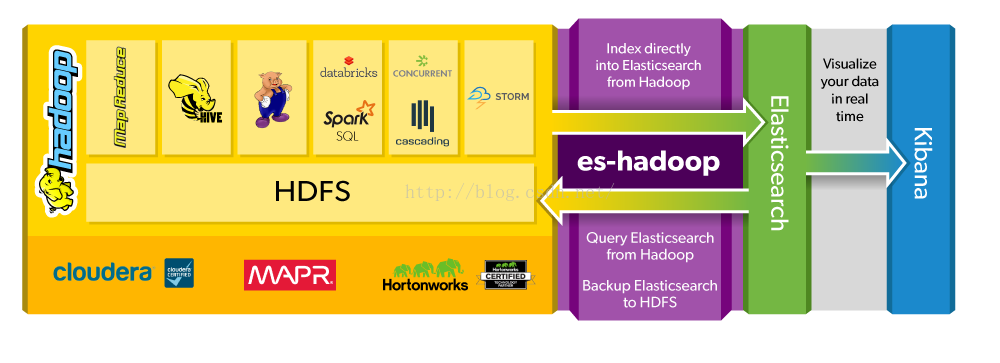
下面直接看一个简单的ES与Hadoop之间数据移动的实例
项目依赖的jar包如下
ElasticSearch到Hadoop最简单的实例
hadoop jar eshadoop.jar E2HJob01 /user/data/es/job/
从hadoop上的数据文件可以看到第一列是ES的doc id,第二列是doc data
也可以添加ES查询条件,实例如下
下面这个实例是每行直接以json格式存储在hadoop上
接下来的实例是将hadoop上的数据移动到ElasticSearch上索引,这里直接用上面存储的JSON数据试验
执行hadoop jar eshadoop.jar H2EJob
/user/data/es/job后,可以在ES上看到数据已经索引过来。
下面直接看一个简单的ES与Hadoop之间数据移动的实例
项目依赖的jar包如下
<dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-hadoop</artifactId> <version>2.3.2</version> </dependency>
ElasticSearch到Hadoop最简单的实例
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.elasticsearch.hadoop.mr.LinkedMapWritable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class E2HJob01 {
private static Logger LOG = LoggerFactory.getLogger(E2HJob01.class);
public static void main(String args[]) {
try {
Configuration conf = new Configuration();
conf.setBoolean("mapreduce.map.speculative", false);
conf.setBoolean("mapreduce.reduce.speculative", false);
//ElasticSearch节点
conf.set("es.nodes", "centos.host1:9200");
//ElaticSearch Index/Type
conf.set("es.resource", "job/51/");
String[] oArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (oArgs.length != 1) {
LOG.error("error");
System.exit(2);
}
Job job = Job.getInstance(conf, "51JOBE2H01");
job.setJarByClass(E2HJob01.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(E2HMapper01.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LinkedMapWritable.class);
FileOutputFormat.setOutputPath(job, new Path(oArgs[0]));
System.out.println(job.waitForCompletion(true));
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
}
}
class E2HMapper01 extends Mapper<Text, LinkedMapWritable, Text, LinkedMapWritable> {
private static final Logger LOG = LoggerFactory.getLogger(E2HMapper01.class);
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
@Override
protected void map(Text key, LinkedMapWritable value, Context context)
throws IOException, InterruptedException {
LOG.info("key {} value {}", key, value);
context.write(key, value);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}hadoop jar eshadoop.jar E2HJob01 /user/data/es/job/
从hadoop上的数据文件可以看到第一列是ES的doc id,第二列是doc data
也可以添加ES查询条件,实例如下
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.elasticsearch.hadoop.mr.LinkedMapWritable;
import org.platform.eshadoop.modules.examples.writable.JobWritable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class E2HJob02 {
private static Logger LOG = LoggerFactory.getLogger(E2HJob02.class);
public static void main(String args[]) {
try {
Configuration conf = new Configuration();
conf.setBoolean("mapreduce.map.speculative", false);
conf.setBoolean("mapreduce.reduce.speculative", false);
conf.set("es.nodes", "centos.host1:9200");
conf.set("es.resource", "job/51/");
conf.set("es.query", "?q=高*");
String[] oArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (oArgs.length != 1) {
LOG.error("error");
System.exit(2);
}
Job job = Job.getInstance(conf, "51JOBE2H02");
job.setJarByClass(E2HJob02.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(E2HMapper02.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(JobWritable.class);
FileOutputFormat.setOutputPath(job, new Path(oArgs[0]));
System.out.println(job.waitForCompletion(true));
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
}
}
class E2HMapper02 extends Mapper<Text, LinkedMapWritable, NullWritable, JobWritable> {
private static final Logger LOG = LoggerFactory.getLogger(E2HMapper02.class);
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
@Override
protected void map(Text key, LinkedMapWritable value, Context context)
throws IOException, InterruptedException {
JobWritable writable = new JobWritable();
writable.setId(key);
Map<String, String> map = new HashMap<String, String>();
for (Entry<Writable, Writable> entry : value.entrySet()) {
LOG.info("key {} value {}", entry.getKey(), entry.getValue());
map.put(entry.getKey().toString(), entry.getValue().toString());
}
String jobName = map.get("jobName");
if (StringUtils.isNotBlank(jobName)) {
writable.setJobName(new Text(jobName));
}
String jobUrl = map.get("jobUrl");
if (StringUtils.isNotBlank(jobUrl)) {
writable.setJobUrl(new Text(jobUrl));
}
String companyName = map.get("companyName");
if (StringUtils.isNotBlank(companyName)) {
writable.setCompanyName(new Text(companyName));
}
String companyUrl = map.get("companyUrl");
if (StringUtils.isNotBlank(companyUrl)) {
writable.setCompanyUrl(new Text(companyUrl));
}
String salary = map.get("salary");
if (StringUtils.isNotBlank(salary)) {
writable.setSalary(new Text(salary));
}
String workPlace = map.get("workPlace");
if (StringUtils.isNotBlank(workPlace)) {
writable.setWorkPlace(new Text(workPlace));
}
String contact = map.get("contact");
if (StringUtils.isNotBlank(contact)) {
writable.setContact(new Text(contact));
}
String welfare = map.get("welfare");
if (StringUtils.isNotBlank(welfare)) {
writable.setWelfare(new Text(welfare));
}
context.write(NullWritable.get(), writable);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
public class JobWritable implements Writable, Cloneable {
private Text id = null;
private Text jobName = null;
private Text jobUrl = null;
private Text companyName = null;
private Text companyUrl = null;
private Text salary = null;
private Text workPlace = null;
private Text contact = null;
private Text welfare = null;
public JobWritable() {
id = new Text();
jobName = new Text();
jobUrl = new Text();
companyName = new Text();
companyUrl = new Text();
salary = new Text();
workPlace = new Text();
contact = new Text();
welfare = new Text();
}
public void readFields(DataInput dataInput) throws IOException {
id.readFields(dataInput);
jobName.readFields(dataInput);
jobUrl.readFields(dataInput);
companyName.readFields(dataInput);
companyUrl.readFields(dataInput);
salary.readFields(dataInput);
workPlace.readFields(dataInput);
contact.readFields(dataInput);
welfare.readFields(dataInput);
}
public void write(DataOutput dataOutput) throws IOException {
id.write(dataOutput);
jobName.write(dataOutput);
jobUrl.write(dataOutput);
companyName.write(dataOutput);
companyUrl.write(dataOutput);
salary.write(dataOutput);
workPlace.write(dataOutput);
contact.write(dataOutput);
welfare.write(dataOutput);
}
public Text getId() {
return id;
}
public void setId(Text id) {
this.id = id;
}
public Text getJobName() {
return jobName;
}
public void setJobName(Text jobName) {
this.jobName = jobName;
}
public Text getJobUrl() {
return jobUrl;
}
public void setJobUrl(Text jobUrl) {
this.jobUrl = jobUrl;
}
public Text getCompanyName() {
return companyName;
}
public void setCompanyName(Text companyName) {
this.companyName = companyName;
}
public Text getCompanyUrl() {
return companyUrl;
}
public void setCompanyUrl(Text companyUrl) {
this.companyUrl = companyUrl;
}
public Text getSalary() {
return salary;
}
public void setSalary(Text salary) {
this.salary = salary;
}
public Text getWorkPlace() {
return workPlace;
}
public void setWorkPlace(Text workPlace) {
this.workPlace = workPlace;
}
public Text getContact() {
return contact;
}
public void setContact(Text contact) {
this.contact = contact;
}
public Text getWelfare() {
return welfare;
}
public void setWelfare(Text welfare) {
this.welfare = welfare;
}
@Override
public String toString() {
return id + ":" + jobName + ":" + jobUrl + ":" + companyName + ":" + companyUrl +
":" + salary + ":" + workPlace + ":" + contact + ":" + welfare;
}
}下面这个实例是每行直接以json格式存储在hadoop上
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.elasticsearch.hadoop.mr.LinkedMapWritable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.gson.Gson;
public class E2HJob03 {
private static Logger LOG = LoggerFactory.getLogger(E2HJob03.class);
public static void main(String args[]) {
try {
Configuration conf = new Configuration();
conf.setBoolean("mapreduce.map.speculative", false);
conf.setBoolean("mapreduce.reduce.speculative", false);
conf.set("es.nodes", "centos.host1:9200");
conf.set("es.resource", "job/51/");
String[] oArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (oArgs.length != 1) {
LOG.error("error");
System.exit(2);
}
Job job = Job.getInstance(conf, "51JOBE2H03");
job.setJarByClass(E2HJob03.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(E2HMapper03.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(oArgs[0]));
System.out.println(job.waitForCompletion(true));
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
}
}
class E2HMapper03 extends Mapper<Text, LinkedMapWritable, NullWritable, Text> {
private static final Logger LOG = LoggerFactory.getLogger(E2HMapper02.class);
private Gson gson = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
gson = new Gson();
}
@Override
protected void map(Text key, LinkedMapWritable value, Context context)
throws IOException, InterruptedException {
JobInfo jobInfo = new JobInfo();
jobInfo.setId(key.toString());
Map<String, String> map = new HashMap<String, String>();
for (Entry<Writable, Writable> entry : value.entrySet()) {
LOG.info("key {} value {}", entry.getKey(), entry.getValue());
map.put(entry.getKey().toString(), entry.getValue().toString());
}
jobInfo.setJobName(map.get("jobName"));
jobInfo.setJobUrl(map.get("jobUrl"));
jobInfo.setCompanyName(map.get("companyName"));
jobInfo.setCompanyUrl(map.get("companyUrl"));
jobInfo.setSalary(map.get("salary"));
jobInfo.setWorkPlace(map.get("workPlace"));
jobInfo.setContact(map.get("contact"));
jobInfo.setWelfare(map.get("welfare"));
context.write(NullWritable.get(), new Text(gson.toJson(jobInfo)));
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}
class JobInfo {
private String id = null;
private String jobName = null;
private String jobUrl = null;
private String companyName = null;
private String companyUrl = null;
private String salary = null;
private String workPlace = null;
private String contact = null;
private String welfare = null;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getJobName() {
return jobName;
}
public void setJobName(String jobName) {
this.jobName = jobName;
}
public String getJobUrl() {
return jobUrl;
}
public void setJobUrl(String jobUrl) {
this.jobUrl = jobUrl;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getCompanyUrl() {
return companyUrl;
}
public void setCompanyUrl(String companyUrl) {
this.companyUrl = companyUrl;
}
public String getSalary() {
return salary;
}
public void setSalary(String salary) {
this.salary = salary;
}
public String getWorkPlace() {
return workPlace;
}
public void setWorkPlace(String workPlace) {
this.workPlace = workPlace;
}
public String getContact() {
return contact;
}
public void setContact(String contact) {
this.contact = contact;
}
public String getWelfare() {
return welfare;
}
public void setWelfare(String welfare) {
this.welfare = welfare;
}
}接下来的实例是将hadoop上的数据移动到ElasticSearch上索引,这里直接用上面存储的JSON数据试验
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.elasticsearch.hadoop.mr.EsOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class H2EJob {
private static Logger LOG = LoggerFactory.getLogger(H2EJob.class);
public static void main(String args[]) {
try {
Configuration conf = new Configuration();
conf.setBoolean("mapreduce.map.speculative", false);
conf.setBoolean("mapreduce.reduce.speculative", false);
conf.set("es.nodes", "centos.host1:9200");
conf.set("es.resource", "job1/51");
//Hadoop上的数据格式为JSON,可以直接导入
conf.set("es.input.json", "yes");
String[] oArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (oArgs.length != 1) {
LOG.error("error");
System.exit(2);
}
Job job = Job.getInstance(conf, "51JOBH2E");
job.setJarByClass(H2EJob.class);
job.setMapperClass(H2EMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputFormatClass(EsOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(oArgs[0]));
System.out.println(job.waitForCompletion(true));
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
}
}
class H2EMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
@Override
public void run(Context context) throws IOException, InterruptedException {
super.run(context);
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
@Override
protected void cleanup(Context context) throws IOException,InterruptedException {
super.cleanup(context);
}
}执行hadoop jar eshadoop.jar H2EJob
/user/data/es/job后,可以在ES上看到数据已经索引过来。

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 分享Hive的一份胶片资料
- Spark随谈——开发指南(译)
- 单机版搭建Hadoop环境图文教程详解
- Spark,一种快速数据分析替代方案
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
- 巧用mysql提示符prompt清晰管理数据库的方法
- hadoop常见错误以及处理方法详解
- 两大步骤教您开启MySQL 数据库远程登陆帐号的方法
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- phpmyadmin 4+ 访问慢的解决方法
- linux系统下实现mysql热备份详细步骤(mysql主从复制)
- CentOS 5.5下安装MySQL 5.5全过程分享
- MySQL复制的概述、安装、故障、技巧、工具(火丁分享)