Sparse Coding
2016-06-15 10:54
225 查看
Sparse Coding
这几天在看特征稀疏的问题,有一些资料指向了Sparse Coding。Sparse Coding与CNN一样也是深度学习的一种常见模式。借此机会复习一下Sparse Coding,因为没有实际编写过Sparse Coding的代码,如有理解不到位的地方,欢迎指出。本质思想
Sparse Coding是一种无监督学习方法,本质是找到原始输入的一个稀疏表达,也就是用一个稀疏的特征向量来表达原始输入数据。稀疏编码与自编码的结构很相似,看一下自编码网络:

通过enconde和decode两个过程,多次优化,找到原输入的一个编码表示(图中的code)。
稀疏编码也是如此,不过就是在自编码的基础上加了L1正则限制(约束向量的元素大部分为0)
代价函数
Auto Encoding的优化目标是Min|I−O|
这里,
I是输入,
O是编码后的输出。
O可以表示为:
O=a1φ1+a2φ2+a3φ3+...
φi是学习到的一组基向量,a是学习到的一组系数(可以看到这里需要学习两个东西,采用的是固定其一,学习另一的方法,后边详细介绍)。a就是最终的特征。
Sparse Coding需要对
a加L1限制:
Min|I−O|+u||a||1
这样,sparse coding的代价函数可以写为:
L(X;W)=||Wa−X||2+u||a||1
这里的
a是学习到的特征。
另外,值得说明的是,sparse coding学习到了一组基向量和一组系数(特征)。这组基向量是超完备的(基向量的个数比输入向量的个数大,也正因为此,特征中才会出现稀疏性(很多0)吧)。
关于
超完备向量,应用ufdl的一段话:
稀疏编码算法的目的就是找到一组基向量φ_i,使得我们能将输入向量x表示为这些基向量的线性组合:
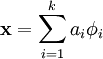
虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组“超完备”基向量来表示输入向量
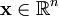
(也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 x 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题.
训练和测试
1.Training给定一系列的输入X_1_,X_2_,X_3_,…,X_n_需要学习到一组基向量φ1,φ2,φ3…
训练过程是一个重复迭代的过程,交替更新a和φ,使代价函数最小:
step1:固定φ,更新a,这是一个LASSO问题
step2:固定a,更新φ,这是一个QP问题
关于这两个问题,感兴趣可查资料搜索。
2.测试
训练已经完成,给定一个新的数据X,通过解一个LASSO问题即可得到稀疏向量a。
根据前面的的描述,稀疏编码是有一个明显的局限性的,这就是即使已经学习得到一组基向量,如果为了对新的数据样本进行“编码”,我们必须再次执行优化过程来得到所需的系数。这个显著的“实时”消耗意味着,即使是在测试中,实现稀疏编码也需要高昂的计算成本,尤其是与典型的前馈结构算法相比。

相关文章推荐
- CUDA搭建
- 稀疏自动编码器 (Sparse Autoencoder)
- 白化(Whitening):PCA vs. ZCA
- softmax回归
- 卷积神经网络初探
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能入门教程之十一 最强网络DLSTM 双向长短期记忆网络(阿里小AI实现)
- TensorFlow人工智能入门教程之十四 自动编码机AutoEncoder 网络
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 稀疏傅里叶变换(SFT)算法
- 安装caffe过程记录
- DIGITS的安装与使用记录
- 图像识别和图像搜索
- 卷积神经网络
- 深度学习札记
- ubuntu14.04安装 资料
- ImageNet classification with deep convolutional neural network