【机器学习】SVM分类器
2016-06-08 21:43
225 查看
(最近在看机器学习,好多东西看着看着就忘记了,写下来应该会好一点,也便于整理思路。不对之处还望批评指正,共同学习)
支持向量机(support vector machine,SVM)
几个定义:
支持向量:距离分割超平面最近的向量,这些向量决定了分割超平面,而其他向量并没有做贡献。所以叫做支持向量。
间距:分割超平面与支持向量之间的距离。
SVM的目的
首先来解释一下支持向量机的目的和含义。
支持向量机的目的是找到一个最优超平面(超平面的含义,可以理解为n维空间下的一个n-1维平面),其不仅能够把两类向量分割,而且是最优的。那么什么情况下是最优的呢?定义分割超平面与距离超平面最近的向量之间的距离为间距,最优的意思就是令间距最大。
超平面的一般形式是w·x-b=0,w是超平面的法向量,x是超平面上的点,引入b的目的是避免一定要经过原点。找到与超平面平行的两个平面:w·x-b=1和w·x-b=-1,(不一定取1和-1,任意两个互为相反数都可以),待分割的所有向量都位于这两个平面两侧,那么就有w·xi-b>=1或w·xi-b<=-1。不要忘记,还有一个约束条件是最优超平面,把最优超平面的目标转化为令两个平面距离最大,两个平面距离为2/|w|,因此问题就转化为
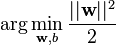
,满足

其中

。(公式摘抄自维基百科)
SVM的发展历程
SVM最初是为二类的分类问题设计的,后来出现了多类问题,人们就想,能不能用SVM解决呢?然后就有了好多办法。
Vapnik在1998年提出了one-versus-the rest方法,假设有K个类,构造K-1个分类器,第i个分类器将空间分成两部分,一部分是i类,另一部分不是i类(i=1,...,k-1)这个思想很简单,但却有一个问题(inconsistent result),这些分类器相互独立,有可能将空间分的乱七八糟,有交叉重合,也有遗漏的区域。另外还有一个问题,训练这样的分类器时,正负样本不均衡,比如有10个类,则正样本只有10%,负样本却有90%,这样原始问题的对称性就消失了(不太能理解,对一个单独的分类器而言,样本就是不均衡的啊).Lee在2001年提出了修正方案,将正样本目标值设为+1,负样本目标值设为-1/(K-1)。
另一种方法是对所有K个类训练K(K-1)/2个分类器,也就是任意两个类之间都有一个分类器,这样对于一个测试样本,可以得到K(K-1)/2个分类结果,统计哪个类出现次数最多(most ‘vote’)则样本就属于哪个类。这种方法有两个问题:1、存在模糊区域,例如三个类,得出的判别结果是c1>c2,c2>c3,c3>c1,就没法判断了;2、时间复杂度太高。Platt在2000年提出DAGSVM方法,把分类时间复杂度降到O(n),方法是构造一个直连无环图。
支持向量机(support vector machine,SVM)
几个定义:
支持向量:距离分割超平面最近的向量,这些向量决定了分割超平面,而其他向量并没有做贡献。所以叫做支持向量。
间距:分割超平面与支持向量之间的距离。
SVM的目的
首先来解释一下支持向量机的目的和含义。
支持向量机的目的是找到一个最优超平面(超平面的含义,可以理解为n维空间下的一个n-1维平面),其不仅能够把两类向量分割,而且是最优的。那么什么情况下是最优的呢?定义分割超平面与距离超平面最近的向量之间的距离为间距,最优的意思就是令间距最大。
超平面的一般形式是w·x-b=0,w是超平面的法向量,x是超平面上的点,引入b的目的是避免一定要经过原点。找到与超平面平行的两个平面:w·x-b=1和w·x-b=-1,(不一定取1和-1,任意两个互为相反数都可以),待分割的所有向量都位于这两个平面两侧,那么就有w·xi-b>=1或w·xi-b<=-1。不要忘记,还有一个约束条件是最优超平面,把最优超平面的目标转化为令两个平面距离最大,两个平面距离为2/|w|,因此问题就转化为
,满足
其中
。(公式摘抄自维基百科)
SVM的发展历程
SVM最初是为二类的分类问题设计的,后来出现了多类问题,人们就想,能不能用SVM解决呢?然后就有了好多办法。
Vapnik在1998年提出了one-versus-the rest方法,假设有K个类,构造K-1个分类器,第i个分类器将空间分成两部分,一部分是i类,另一部分不是i类(i=1,...,k-1)这个思想很简单,但却有一个问题(inconsistent result),这些分类器相互独立,有可能将空间分的乱七八糟,有交叉重合,也有遗漏的区域。另外还有一个问题,训练这样的分类器时,正负样本不均衡,比如有10个类,则正样本只有10%,负样本却有90%,这样原始问题的对称性就消失了(不太能理解,对一个单独的分类器而言,样本就是不均衡的啊).Lee在2001年提出了修正方案,将正样本目标值设为+1,负样本目标值设为-1/(K-1)。
另一种方法是对所有K个类训练K(K-1)/2个分类器,也就是任意两个类之间都有一个分类器,这样对于一个测试样本,可以得到K(K-1)/2个分类结果,统计哪个类出现次数最多(most ‘vote’)则样本就属于哪个类。这种方法有两个问题:1、存在模糊区域,例如三个类,得出的判别结果是c1>c2,c2>c3,c3>c1,就没法判断了;2、时间复杂度太高。Platt在2000年提出DAGSVM方法,把分类时间复杂度降到O(n),方法是构造一个直连无环图。

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- 反向传播(Backpropagation)算法的数学原理
- 关于SVM的那点破事
- 也谈 机器学习到底有没有用 ?
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- LSI SVM 挑战IBM SVC
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐