SPIR-V 研究:编译器基本原理
2016-05-19 18:29
531 查看
http://blog.csdn.net/qwertyu1234/article/details/50163847
前面转过两篇关于SPIR-V 中间语言的介绍;接下来笔者准备深入学习一下SPIR-V的标准。根据标准,SPIR-V是以一种二进制格式存在的,并且函数还是以控制流图CFG的形式存在;数据结构也保留了高级语言里的层级关系。(https://en.wikipedia.org/wiki/Standard_Portable_Intermediate_Representation)
这样做的目的是为了更好的在目标平台上进行优化;同时Khronos也放出了官方标准的开源编译器Glslang。 所以,为了更好的了解SPIR-V,我们有必要先温习一下编译器的基本原理,特别是前端的词法分析、语法分析、语义分析和中间语言生成。
下图是一个一般编译器的编译高级语言的过程。
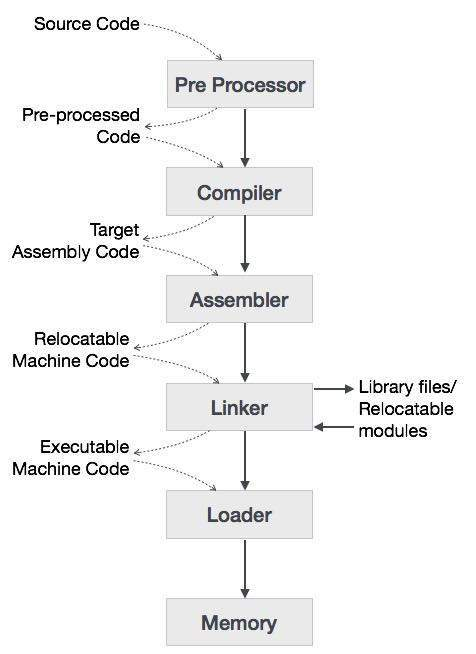
基本上就是预处理(比如C/C++里宏汇编),编译并汇编(每个源码文件都生成对应的.o文件,这时的代码是relocatable的),链接生成可执行文件(linker,把许多.o文件以及用到的库函数.lib文件合并并作全局优化),最后OS的加载器会加载可执行文件并运行之(Windows上是PE格式,Linux上市ELF格式)。具体细节可以参考Linkers
and Loaders 这本书。
下面我们重点看编译器的结构。
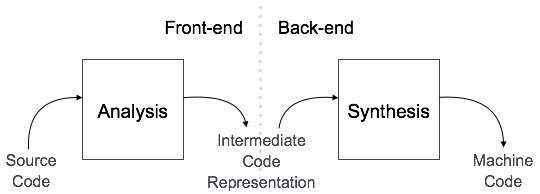
这是一般编译器的结构,主要分前端和后端,以中间语言生成为界限。前端主要是分析语法语义并生成代码的中间表示,这主要包括lexer 和 parser,以及语义分析;后端主要是生成目标机器代码,包括分析并优化,寄存器分配等。
下图是编译器的主要编译过程(phase)。
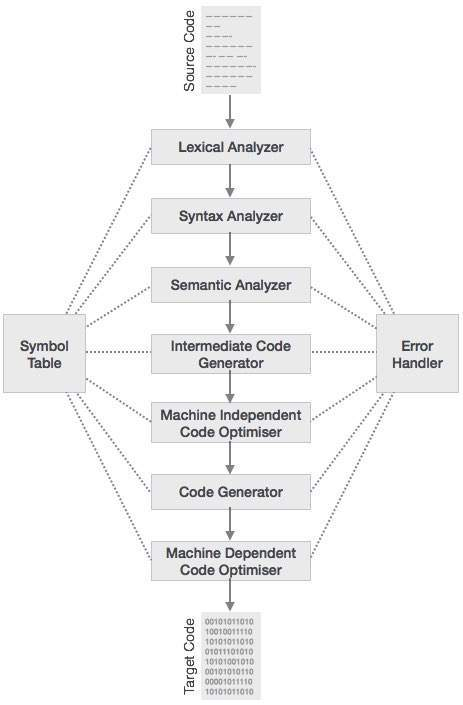
这里我们研究的目标SPIR-V就是一种标准化的中间语言表示。所以我们更关心的是前端的研究,这也是编译器里比较成熟,相对简单的部分。以前的OpenGL里,GLSL写成的Shader是高级语言(相当于C++),OpenGL的驱动会把它编译成显卡GPU对应的机器码。所以各家会有不同的中间表示;Vulkan会统一标准用SPIR-V了。
计算机科学里的语言可以看作是一个字母表(alphabet )上的某些有限长字符串的集合;这一般可以包含无限多个字符串,也就是无限集合(Infinite Sets)。这里有限长字符串就是“sentences”;sentences是word(或token)组成,它有一定的结构;token则是letter由一定规则组成;letter个数是有限的,它们全部取自字母表(alphabet )。
这是个有层次的定义。
语言是有一定的语法规则的(grammar)。而grammar是一组有限的规则的集合;计算机语言里的grammar是不同于一般自然语言的语法,它可以构造出所有可能的sentences。所以这是一个利用有限规则来产生无限的合法语句的问题。
而grammar又可以用正则表达式来定义;比如GLSL的语法glslang.y。
标签(空格分隔): SPIR-V Vulkan Grammar
上一篇说过语法分为四类;这一篇来介绍Chomsky Hierarchy。首先,我们简单看看type-0和type-1的语法。
这是一种没有任何限制的语法,理论上可以描述任何图林机可以接受的语言。它的一般形式如下图:

这是一个从u生成v的过程;其中u,v是任意字符组合(包括最终字符和中间符号,或空字符),当然u至少包含一个中间符号。数学表达式为:
虽然,type-0很强大,但是用它来检验语句是否符合语法规则,也就是写一个一般性通用的Parser,是非常困难的事。这也就引出了后面几种语法;其想法是通过加强限制条件,我们可以得到更简单更容易使用的语法。
这是一种上下文有关的语法规则;左侧和右侧被替换的字符前后都有可能有别的字符,也就是有上下文的;只有在这一组字符一起出现才能应用这个规则。并且,左侧的字符数要小于等于右侧。如下图

其一般形式:

其中α,β可以是空字符,也就是没有;γ是任意字符。
这里A被替换为γ 有个前提条件,就是当且仅当A被α,β包裹;这也就是上下文相关。
CSG的生成过程可以用一张图来表示,比如:

这种CSG的生成图比较复杂,可能会含有某种环;而我们后面将要看到的CFG和正则语法图就简单的多了。
Kleene star
这里有几个描述符号我们会经常碰到:*,+,?,|;它们也广泛用于正则表达式。
* Kleene star/克莱尼星号(或者克莱尼闭包)是一个针对集合或字符的单目运算符。一个集合的克莱尼闭包定义为:
加号运算符+:
? : 0个或一个元素。
| : 或运算。U : 集合的并集。
CFG是这样一种语法规则,左边(LHS)只有一个中间字符,而右边(RHS)是任意字符。
这样的规则替换的时候是和上下文无关的;只是简单的把某个中间表示替换成一组字符,然后继续。这样的过程可以用一颗生成树来表示,比如:

CFG的一个问题是右边有可能有多于一个的中间表示;这样当某个中间表示被替换时,我们必须记住旁边还有另一个中间表示也要被替换;也就是说CFG可能需要在生成树上往上回溯。我们希望有个更简单的规则,它可以一路向下不断替换最终结束,而不用回溯。这就是Regular Grammar。

Regular Grammar: 限制右边只能是一组最终字符或一组最终字符加一个中间表示。
这样,生成树变成了一个链条。

下表是四种类型语法描述汇总表格;其中:
T or ∑ = set of alphabet/Character/terminals = ( a, b,c,…., +,-,*, …. )
V = Set of non-terminals or variables =( A,B,C, …., )
(∑ U V) = combination of variables and terminals
标签(空格分隔): SPIR-V Graphics Vulkan
上一篇介绍了计算机语言的基本知识,这一篇主要讲讲语法。语法是一组能生成对应语言语句的规则,这一般是一个有限集合,也就是只有有限多个规则。所以,根据给定语法和字母表,我们可以生成所有符合规则的语句。比如下图:

L可以包含有限个数的语句;最小的语言不包含任何语句。
L还可以包含无限多个语句;比如一般编程语言就是如此。
由于一个句子可以属于或不属于某一语言,所以需要一种规则或方法还检验给定语句是不是属于特定语言。这种规则就是语法;检验的过程就是Parse的过程。
首先是一个字母表Σ,它包含所有的**有限个的**terminal symbols;terminal symbols,顾名思义就是最终的字符,不是中间的表示符号。因为语法基本上是一个递归替换的符号的过程;当所有符号都是最终字符时,替换过程结束,这时得到的就是这种语法生成的一个语句。比如:
其次是一个包含有限个中间字符的集合N(nonterminal symbols).
中间字符是特殊的,可以把它们想象成wildcards;最终会被替换成其他符号。比如:
再次是必须有一个中间符号最为起始符号S;它是所有可能的替换生成过程的开始。比如:
最后我们要有一组生成规则P(production rules);这是有限集合,定义了怎么样来组建语句。比如:
一个Formal Grammar就可以表示为以上四个集合的元组(tuple)。
正式的数学语言描述为:

具体也可参见wikiFormal_grammar.
数学大牛Noam Chomsky很早就研究了语言和语法,并对语法提出了分类。也就是所谓的Type-0,Type-1, Type-2和Type-3语法。其中最有用的是Context-free grammars (Type 2) and Regular grammars (Type 3).
它们之间是包含关系,Type-0是没有任何限制的语法,可以描述最多的语言;其他的都是一步步加上各种限制后得出的语法,它们能描述的语言也就越来越少;然而它们却更简单更有用。事实上很多编程语言的语法都是正则表达式来描述的,也就是type-3。

前面转过两篇关于SPIR-V 中间语言的介绍;接下来笔者准备深入学习一下SPIR-V的标准。根据标准,SPIR-V是以一种二进制格式存在的,并且函数还是以控制流图CFG的形式存在;数据结构也保留了高级语言里的层级关系。(https://en.wikipedia.org/wiki/Standard_Portable_Intermediate_Representation)
这样做的目的是为了更好的在目标平台上进行优化;同时Khronos也放出了官方标准的开源编译器Glslang。 所以,为了更好的了解SPIR-V,我们有必要先温习一下编译器的基本原理,特别是前端的词法分析、语法分析、语义分析和中间语言生成。
编译器基本结构
下图是一个一般编译器的编译高级语言的过程。 基本上就是预处理(比如C/C++里宏汇编),编译并汇编(每个源码文件都生成对应的.o文件,这时的代码是relocatable的),链接生成可执行文件(linker,把许多.o文件以及用到的库函数.lib文件合并并作全局优化),最后OS的加载器会加载可执行文件并运行之(Windows上是PE格式,Linux上市ELF格式)。具体细节可以参考Linkers
and Loaders 这本书。
下面我们重点看编译器的结构。
这是一般编译器的结构,主要分前端和后端,以中间语言生成为界限。前端主要是分析语法语义并生成代码的中间表示,这主要包括lexer 和 parser,以及语义分析;后端主要是生成目标机器代码,包括分析并优化,寄存器分配等。
下图是编译器的主要编译过程(phase)。
这里我们研究的目标SPIR-V就是一种标准化的中间语言表示。所以我们更关心的是前端的研究,这也是编译器里比较成熟,相对简单的部分。以前的OpenGL里,GLSL写成的Shader是高级语言(相当于C++),OpenGL的驱动会把它编译成显卡GPU对应的机器码。所以各家会有不同的中间表示;Vulkan会统一标准用SPIR-V了。
计算机语言
计算机科学里的语言可以看作是一个字母表(alphabet )上的某些有限长字符串的集合;这一般可以包含无限多个字符串,也就是无限集合(Infinite Sets)。这里有限长字符串就是“sentences”;sentences是word(或token)组成,它有一定的结构;token则是letter由一定规则组成;letter个数是有限的,它们全部取自字母表(alphabet )。 这是个有层次的定义。
| Layer | 分析对象 | 组成元素 |
|---|---|---|
| 词法(Lexical structure ) | token | letter |
| 语法(Syntactic structure) | sentences | token |
| 语义(Semantics) | 语法树 |
而grammar又可以用正则表达式来定义;比如GLSL的语法glslang.y。
SPIR-V 研究:编译器基本原理(三) - Chomsky文法分类
标签(空格分隔): SPIR-V Vulkan Grammar上一篇说过语法分为四类;这一篇来介绍Chomsky Hierarchy。首先,我们简单看看type-0和type-1的语法。
Type-0 - Unrestricted grammar
这是一种没有任何限制的语法,理论上可以描述任何图林机可以接受的语言。它的一般形式如下图: 这是一个从u生成v的过程;其中u,v是任意字符组合(包括最终字符和中间符号,或空字符),当然u至少包含一个中间符号。数学表达式为:
(Σ ⋃ N)* N (Σ ⋃ N)* --> (Σ ⋃ N)*
虽然,type-0很强大,但是用它来检验语句是否符合语法规则,也就是写一个一般性通用的Parser,是非常困难的事。这也就引出了后面几种语法;其想法是通过加强限制条件,我们可以得到更简单更容易使用的语法。
Type-1- Context-sensitive grammar (CSG)
这是一种上下文有关的语法规则;左侧和右侧被替换的字符前后都有可能有别的字符,也就是有上下文的;只有在这一组字符一起出现才能应用这个规则。并且,左侧的字符数要小于等于右侧。如下图 其一般形式:
其中α,β可以是空字符,也就是没有;γ是任意字符。
这里A被替换为γ 有个前提条件,就是当且仅当A被α,β包裹;这也就是上下文相关。
CSG的生成过程可以用一张图来表示,比如:
这种CSG的生成图比较复杂,可能会含有某种环;而我们后面将要看到的CFG和正则语法图就简单的多了。
Kleene star
这里有几个描述符号我们会经常碰到:*,+,?,|;它们也广泛用于正则表达式。
* Kleene star/克莱尼星号(或者克莱尼闭包)是一个针对集合或字符的单目运算符。一个集合的克莱尼闭包定义为:
L* = {ε} ∪ L ∪ LL ∪ LLL ∪ ..., 即L的0到正无穷次幂的并集。对于语言L*=
{'a'},我们有:L*={ε, 'a', 'aa', 'aaa', ...}。 加号运算符+:
L+ = LL* = L*L,对L = {'a'},我们有:L+={'a', 'aa', 'aaa', ...}。 ? : 0个或一个元素。
| : 或运算。U : 集合的并集。
Type-2 Context Free Grammar
CFG是这样一种语法规则,左边(LHS)只有一个中间字符,而右边(RHS)是任意字符。 α --> (N U Σ)* ; α属于N
这样的规则替换的时候是和上下文无关的;只是简单的把某个中间表示替换成一组字符,然后继续。这样的过程可以用一颗生成树来表示,比如:
Type-3 Regular grammar
CFG的一个问题是右边有可能有多于一个的中间表示;这样当某个中间表示被替换时,我们必须记住旁边还有另一个中间表示也要被替换;也就是说CFG可能需要在生成树上往上回溯。我们希望有个更简单的规则,它可以一路向下不断替换最终结束,而不用回溯。这就是Regular Grammar。 Regular Grammar: 限制右边只能是一组最终字符或一组最终字符加一个中间表示。
1. B → a - where B is a non-terminal in N and a is a terminal in Σ 2. B → aC - where B and C are non-terminals in N and a is in Σ 3. B → ε - where B is in N and ε denotes the empty string, i.e. the string of length 0.
这样,生成树变成了一个链条。
下表是四种类型语法描述汇总表格;其中:
T or ∑ = set of alphabet/Character/terminals = ( a, b,c,…., +,-,*, …. )
V = Set of non-terminals or variables =( A,B,C, …., )
(∑ U V) = combination of variables and terminals
| CLASS | GRAMMAR | LANGUAGE | AUTOMATION | DEFINITION |
|---|---|---|---|---|
| Type 0 => | Unrestricted or Phase Structural Grammar | Recursive and Recursive Enumerable | Turing Machine | (∑ U V)* → (∑ U V)* At least one variable in LHS |
| Type 1 => | Context Sensitive grammar (CSG) | Context Sensitive language (CSL) | Linear bounded Automaton (LBA) | (∑ U V)* → (∑ U V)* Size of LHS ≤ RHS i.e. if x→y then│x│≤ │y│ and αAβ → αBβ where, α = left context, β = right context, A = a Variable, B = anything (∑UV)* |
| Type 2 => | Context- free (CFG) | Context- free language(CFL) | Push Down Automaton( PDA) | A → (∑ U V)* |
| Type 3 => | Regular Grammer | Regular language | Finite Automation (FA) | A → a , A → aB or A → a , A → Ba) |
SPIR-V 研究:编译器基本原理(二)- 语法
标签(空格分隔): SPIR-V Graphics Vulkan上一篇介绍了计算机语言的基本知识,这一篇主要讲讲语法。语法是一组能生成对应语言语句的规则,这一般是一个有限集合,也就是只有有限多个规则。所以,根据给定语法和字母表,我们可以生成所有符合规则的语句。比如下图:
Formal Language
这里所讲的语言其实就是形式语言(formal language),对应的语法就是formal grammar。语言L是一组长度有限的字符串(语句)。L可以包含有限个数的语句;最小的语言不包含任何语句。
L还可以包含无限多个语句;比如一般编程语言就是如此。
由于一个句子可以属于或不属于某一语言,所以需要一种规则或方法还检验给定语句是不是属于特定语言。这种规则就是语法;检验的过程就是Parse的过程。
Formal Grammar
语法有四种元素构成。可以参见这篇好文章:Formal Grammar。首先是一个字母表Σ,它包含所有的**有限个的**terminal symbols;terminal symbols,顾名思义就是最终的字符,不是中间的表示符号。因为语法基本上是一个递归替换的符号的过程;当所有符号都是最终字符时,替换过程结束,这时得到的就是这种语法生成的一个语句。比如:
Σ = { "a", "the", "dog", "cat", "barked", "napped"}其次是一个包含有限个中间字符的集合N(nonterminal symbols).
中间字符是特殊的,可以把它们想象成wildcards;最终会被替换成其他符号。比如:
N = { "<sentence>", "<noun>", "<verb>", "<article>" }再次是必须有一个中间符号最为起始符号S;它是所有可能的替换生成过程的开始。比如:
S = "<sentence>"
最后我们要有一组生成规则P(production rules);这是有限集合,定义了怎么样来组建语句。比如:
<code class="hljs bash has-numbering" style="display: block; padding: 0px; color: inherit; box-sizing: border-box; font-family: 'Source Code Pro', monospace;font-size:undefined; white-space: pre; border-radius: 0px; word-wrap: normal; background: transparent;">P = {
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<sentence>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<article><noun><verb>"</span>
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<article>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"a"</span>
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<article>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"the"</span>
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<noun>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"dog"</span>
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<noun>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"cat"</span>
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<verb>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"barked"</span>
<span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"<verb>"</span> → <span class="hljs-string" style="color: rgb(0, 136, 0); box-sizing: border-box;">"napped"</span>
}</code><ul class="pre-numbering" style="box-sizing: border-box; position: absolute; width: 50px; top: 0px; left: 0px; margin: 0px; padding: 6px 0px 40px; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(221, 221, 221); list-style: none; text-align: right; background-color: rgb(238, 238, 238);"><li style="box-sizing: border-box; padding: 0px 5px;">1</li><li style="box-sizing: border-box; padding: 0px 5px;">2</li><li style="box-sizing: border-box; padding: 0px 5px;">3</li><li style="box-sizing: border-box; padding: 0px 5px;">4</li><li style="box-sizing: border-box; padding: 0px 5px;">5</li><li style="box-sizing: border-box; padding: 0px 5px;">6</li><li style="box-sizing: border-box; padding: 0px 5px;">7</li><li style="box-sizing: border-box; padding: 0px 5px;">8</li><li style="box-sizing: border-box; padding: 0px 5px;">9</li></ul><ul class="pre-numbering" style="box-sizing: border-box; position: absolute; width: 50px; top: 0px; left: 0px; margin: 0px; padding: 6px 0px 40px; border-right-width: 1px; border-right-style: solid; border-right-color: rgb(221, 221, 221); list-style: none; text-align: right; background-color: rgb(238, 238, 238);"><li style="box-sizing: border-box; padding: 0px 5px;">1</li><li style="box-sizing: border-box; padding: 0px 5px;">2</li><li style="box-sizing: border-box; padding: 0px 5px;">3</li><li style="box-sizing: border-box; padding: 0px 5px;">4</li><li style="box-sizing: border-box; padding: 0px 5px;">5</li><li style="box-sizing: border-box; padding: 0px 5px;">6</li><li style="box-sizing: border-box; padding: 0px 5px;">7</li><li style="box-sizing: border-box; padding: 0px 5px;">8</li><li style="box-sizing: border-box; padding: 0px 5px;">9</li></ul>一个Formal Grammar就可以表示为以上四个集合的元组(tuple)。
G = { N, Σ, P, S }正式的数学语言描述为:
具体也可参见wikiFormal_grammar.
The Chomsky hierarchy
数学大牛Noam Chomsky很早就研究了语言和语法,并对语法提出了分类。也就是所谓的Type-0,Type-1, Type-2和Type-3语法。其中最有用的是Context-free grammars (Type 2) and Regular grammars (Type 3). 它们之间是包含关系,Type-0是没有任何限制的语法,可以描述最多的语言;其他的都是一步步加上各种限制后得出的语法,它们能描述的语言也就越来越少;然而它们却更简单更有用。事实上很多编程语言的语法都是正则表达式来描述的,也就是type-3。

相关文章推荐
- 1014. Waiting in Line (30)
- 通过ADB启动手机端APK
- Oracle 数据库及Oracle SQL Developer安装注意的地方
- 一个简单的HbaseHelper类
- Android Context原理与使用的总结
- 安装了多个eclipse导致快捷键失效解决办法
- 函数指针
- Android平台免Root无侵入AOP框架Dexposed使用详解
- 加/解密系列(三)-前端加密JS库--CryptoJS
- 加/解密系列(二)-前端加密md5实现--CryptoJS v3.1.2+
- VS2015 异常 :遇到异常。这可能是由某个扩展导致的
- 你该知道的 TValue
- javaoop涉及到登录者 和登录日志的编写
- Uva1605——Building for UN
- SharedPreferences工具类
- 确定位置的经纬度LocationUtil
- FileDialog 使用方法---JAVA
- HTTP Status 500 - Internal Server Error
- HDU2845-Beans
- <JS>显示和基本操作