充分统计量
2016-05-11 09:20
253 查看
充分统计量
标签: 模式分类@author lancelot-vim
定义
我们把任何关于样本集D的函数都称为一个统计量,一个充分统计量就是一个关于样本集D的函数s(允许是向量形式的函数),其中包含了能有助于估计某种参数θ的全部相关信息,就是说我们希望充分统计量的定义能够有这样的约束条件:p(θ|s,D)=p(θ|s)举个例子说:对于高斯分布,期望和协方差矩阵就是它的充分统计量,因为如果这两个参数已知,就可以唯一确定一个高斯分布,而对于高斯分布的其他统计量,例如振幅,高阶矩等在这种时候都是多余的。
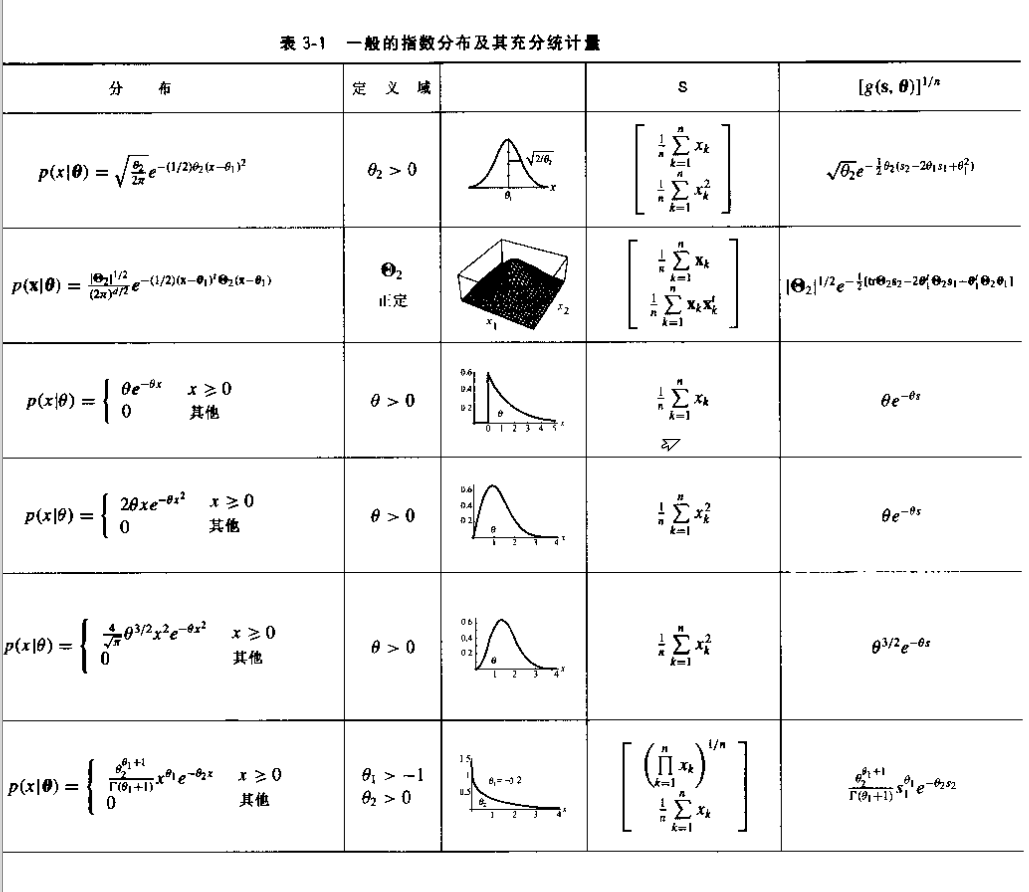
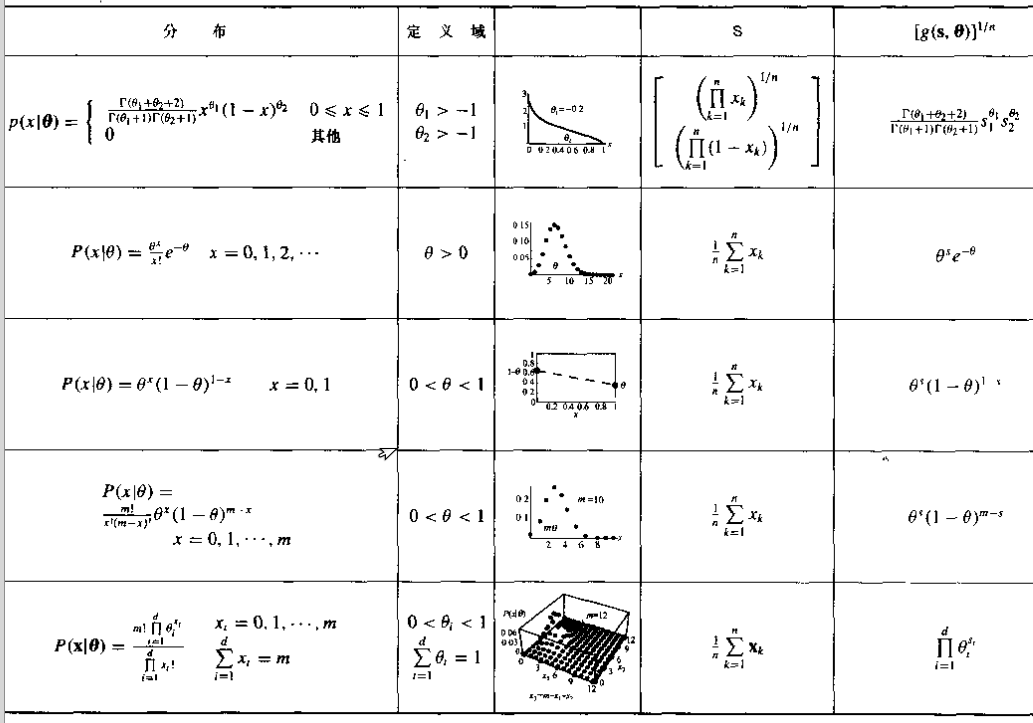
因式分解定理
充分统计量的最基本定义是因式分解定理,即如果S是θ的充分统计量,那么p(D|θ)可以写成一个只依赖于s和θ的函数和一个只与样本有关的函数的乘积,用数学的语言描述如下:s是θ的充分统计量,当且仅当P(D|θ)=g(s,θ)h(D)
充分统计量和指数族
假如s是θ的充分统计量,将P(D|θ)=g(s,θ)h(D)代入贝叶斯一般理论公式p(θ|D)=p(D|θ)p(θ)∫p(D|θ)p(θ)dθ可得:p(θ|D)=g(s,θ)p(θ)∫g(s,θ)p(θ)dθ,假如我们对θ很不确定,那么可以选择一个近似与均匀分布的p(θ),在这种情况下,实际上p(D|θ)就几乎等于核函数g¯(s,θ)=g(s,θ)∫g(s,θ)dθ一个正态分布的示例
对于一个协方差已知,期望未知的正态分布,假设p(x⃗ |θ⃗ )∼N(θ⃗ ,Σ)有:p(D|θ⃗ )=∏k=1n1(2π)d2|Σ|12exp[−12(x⃗ k−θ⃗ )TΣ−1(x⃗ k−θ⃗ )] =exp[n2θ⃗ TΣ−1θ⃗ +θ⃗ TΣ−1x⃗ k(∑x⃗ k)]=g(u⃗ ^n,θ⃗ )×h(D)
其中u⃗ ^n=1n∑nk=1x⃗ k
根据核函数公式:g¯(s,θ)=g(s,θ)∫g(s,θ)dθ,可得:g¯(u⃗ ^n,θ⃗ )=1(2π)d2|1nΣ|12exp[−12(θ⃗ −u⃗ ^n)T(1nΣ)−1(θ⃗ −u⃗ ^n)]
指数族函数
对于可用p(x⃗ ,|θ⃗ )=α(x⃗ )exp(a(θ⃗ )+b(θ⃗ )Tc(x⃗ )来表示的函数叫做指数族函数,其几乎包括了常用的所有分布,对于这种函数,如果它作为某个事件的概率密度,那么总能使用核函数方法来估计分布s⃗ =1n∑nk=1c(x⃗ k)
g(s⃗ ,θ⃗ )=exp[na(θ⃗ +b(θ)Ts⃗ ]
h(D)=Πnk=1α(x⃗ k)

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark机器学习(一) -- Machine Learning Library (MLlib)
- 反向传播(Backpropagation)算法的数学原理
- 关于SVM的那点破事
- 也谈 机器学习到底有没有用 ?
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- TensorFlow人工智能引擎入门教程之十 最强网络 RSNN深度残差网络 平均准确率96-99%
- TensorFlow人工智能引擎入门教程所有目录
- 如何用70行代码实现深度神经网络算法
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习常见的算法面试题总结
- 机器学习书单