Java面试总结(二)
2016-05-08 19:39
519 查看
集合类介绍
java.util包下集合类以及java.util.concurrent包下集合类介绍
主要介绍集合有
ArrayList
CopyOnWriteArrayList
LinkedList
Queue
PriorityQueue
LinkedHashMap
Stack
HashMap
HashTable
ConcurrentHashMap
TreeMap
Set
HashSet
ConcurrentSkipListSet
ArrayList:
transient Object[] elementData; //源码里就一个数组存储
很简单
Java集合基本都有动态扩容处理,以后的集合不会贴代码了
ensureCapacityInternal(size + 1); //很明显判断size是否过长了,过长就扩容然后通过Array.copy 复制老元素到新数组里。(size <= Integer.MAX_VALUE)
add O(1)操作在数组尾部加1元素
remove在Java面试(一)中详细介绍了不说了O(n)的操作,必须找到元素覆盖删除
查找必须遍历整个数组才行O(n)操作
CopyOnWriteArrayList前不久看我同学在用的,然后自己看了看源码
然后我借鉴了http://www.cnblogs.com/dolphin0520/p/3938914.html上说的
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
终于明白add操作的意义所在。
分析ArrayList与CopyOnWriteArrayList
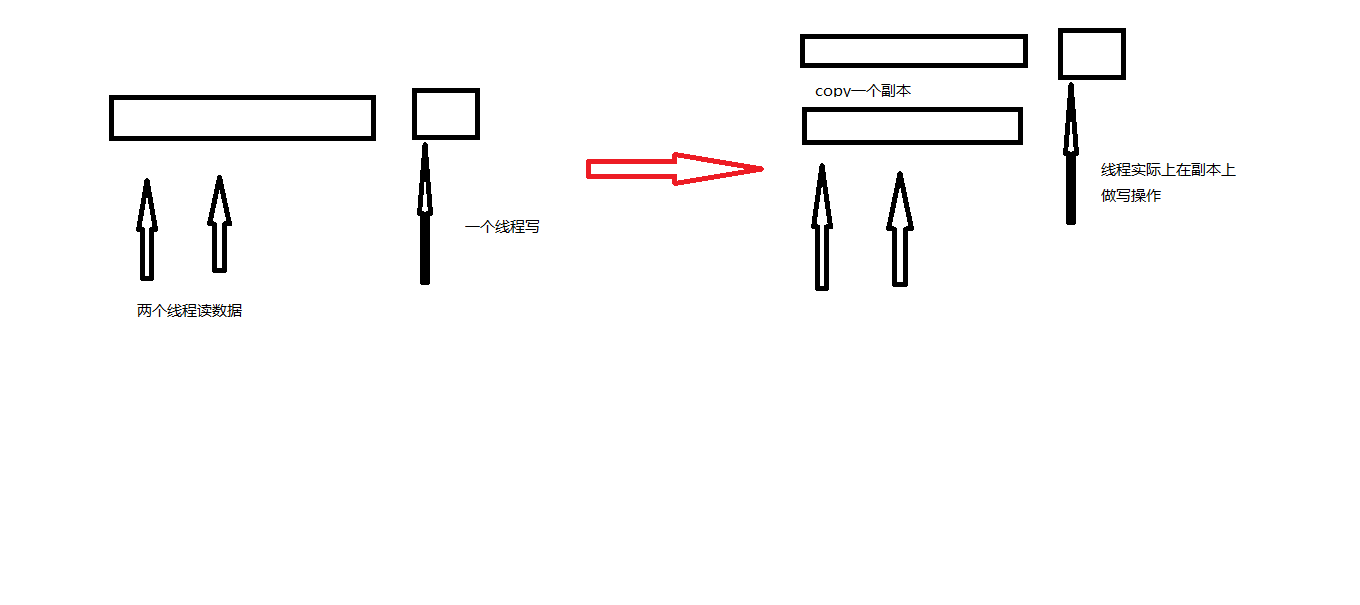
源码:通过源码很清晰的看到每一次add加锁 –>做一次副本 –> 添加
优点:大量读数据不关心写操作,写加锁操作也不影响读
缺点也很明显:大量复制,我还是引用博客的把,毕竟jvm的书还没看完,也说不清gc回收操作
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
LinkedList:
链表:
transient Node first;
transient Node last;
记录了头尾指针
public boolean add(E e) {
linkLast(e);
return true;
}
O(1)操作直接尾插
记得刚进公司时就被问了这个,就是看了源码所以好尴尬,不过也正常这个是从链表remove一个元素,所以先要search再delete
Delete操作总是O(1)的,而search一次链表是O(n)
这个是LikedList内部类Node的remove操作unlink()把元素从链表中删除
Queue:
Array,Link都能模拟Queue
只要维护从头进从尾删就行
Front , last两个指正轻松解决先进先出
可以实现FIFO(First Input First Output)
PriorityQueue(优先队列):
维护一个最小堆就行add,delete都是O(logn)操作,log是以2为底
限于篇幅
看算法导论 最小堆,里面介绍很详细
可以实现Lfu
LinkedHashMap:
不知道你们有没有看过Lru(近期最少使用)实现
Mybatis的Lru算法就是依据LinkedHashMap实现的
图解:

链表(这里是双向的)我们知道,不像arraylist需要在内存中一块连续地址,只要把地址连接起来就OK,所以用hashMap弥补了link遍历的不足。
具体的还是看源码,我有机会再详细介绍,毕竟缓存FIFO,LFU,LRU东西有点多。
Set:
这个比较简单:内部引用一个
ConcurrentSkipListSet:
内部实现跳跃表(Skip List),具体看算法导论的视频,比我BB有意思多了
http://open.163.com/movie/2010/12/7/S/M6UTT5U0I_M6V2TTJ7S.html
这个个人感觉和CopyOnWirteArrayList相似,因为Skip List也会做很多次副本List, 优化查询到O(logn)做二分操作划分。具体还是看视频把,比较好。
HashMap:
Hash索引位置链表解决冲突。判断一个元素是否相同 hash && equals
ConcurrentHashMap:
这篇IBM技术论坛上讲的很好,小伙伴门你们结合下源码很容易理解的,相信你们
https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/
TreeMap:
红黑树实现:
你可能会问为什么不是二叉树,那我问你一个问题,如果二叉树是单偏的

这样的,那边性能可想而知。所以需要一种平衡树去维护。
具体算法导论红黑树
对了,记得把算法导论上的那个B-tree看了,写的很好。面试会有很好的帮助的,只能说面试加油啊。
这次我太饿了,写不下去了,我要回家。。。
903e
java.util包下集合类以及java.util.concurrent包下集合类介绍
主要介绍集合有
ArrayList
CopyOnWriteArrayList
LinkedList
Queue
PriorityQueue
LinkedHashMap
Stack
HashMap
HashTable
ConcurrentHashMap
TreeMap
Set
HashSet
ConcurrentSkipListSet
ArrayList:
transient Object[] elementData; //源码里就一个数组存储
很简单
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}Java集合基本都有动态扩容处理,以后的集合不会贴代码了
ensureCapacityInternal(size + 1); //很明显判断size是否过长了,过长就扩容然后通过Array.copy 复制老元素到新数组里。(size <= Integer.MAX_VALUE)
add O(1)操作在数组尾部加1元素
remove在Java面试(一)中详细介绍了不说了O(n)的操作,必须找到元素覆盖删除
查找必须遍历整个数组才行O(n)操作
CopyOnWriteArrayList前不久看我同学在用的,然后自己看了看源码
然后我借鉴了http://www.cnblogs.com/dolphin0520/p/3938914.html上说的
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
终于明白add操作的意义所在。
分析ArrayList与CopyOnWriteArrayList
源码:通过源码很清晰的看到每一次add加锁 –>做一次副本 –> 添加
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}优点:大量读数据不关心写操作,写加锁操作也不影响读
缺点也很明显:大量复制,我还是引用博客的把,毕竟jvm的书还没看完,也说不清gc回收操作
内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。之前我们系统中使用了一个服务由于每晚使用CopyOnWrite机制更新大对象,造成了每晚15秒的Full GC,应用响应时间也随之变长。
针对内存占用问题,可以通过压缩容器中的元素的方法来减少大对象的内存消耗,比如,如果元素全是10进制的数字,可以考虑把它压缩成36进制或64进制。或者不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
LinkedList:
链表:
transient Node first;
transient Node last;
记录了头尾指针
public boolean add(E e) {
linkLast(e);
return true;
}
O(1)操作直接尾插
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}记得刚进公司时就被问了这个,就是看了源码所以好尴尬,不过也正常这个是从链表remove一个元素,所以先要search再delete
Delete操作总是O(1)的,而search一次链表是O(n)
这个是LikedList内部类Node的remove操作unlink()把元素从链表中删除
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}Queue:
Array,Link都能模拟Queue
只要维护从头进从尾删就行
Front , last两个指正轻松解决先进先出
可以实现FIFO(First Input First Output)
PriorityQueue(优先队列):
维护一个最小堆就行add,delete都是O(logn)操作,log是以2为底
限于篇幅
看算法导论 最小堆,里面介绍很详细
可以实现Lfu
LinkedHashMap:
不知道你们有没有看过Lru(近期最少使用)实现
Mybatis的Lru算法就是依据LinkedHashMap实现的
图解:
链表(这里是双向的)我们知道,不像arraylist需要在内存中一块连续地址,只要把地址连接起来就OK,所以用hashMap弥补了link遍历的不足。
具体的还是看源码,我有机会再详细介绍,毕竟缓存FIFO,LFU,LRU东西有点多。
Set:
这个比较简单:内部引用一个
private transient HashMap <E,Object> map;
ConcurrentSkipListSet:
内部实现跳跃表(Skip List),具体看算法导论的视频,比我BB有意思多了
http://open.163.com/movie/2010/12/7/S/M6UTT5U0I_M6V2TTJ7S.html
这个个人感觉和CopyOnWirteArrayList相似,因为Skip List也会做很多次副本List, 优化查询到O(logn)做二分操作划分。具体还是看视频把,比较好。
HashMap:
Hash索引位置链表解决冲突。判断一个元素是否相同 hash && equals
ConcurrentHashMap:
这篇IBM技术论坛上讲的很好,小伙伴门你们结合下源码很容易理解的,相信你们
https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/
TreeMap:
红黑树实现:
你可能会问为什么不是二叉树,那我问你一个问题,如果二叉树是单偏的
这样的,那边性能可想而知。所以需要一种平衡树去维护。
具体算法导论红黑树
对了,记得把算法导论上的那个B-tree看了,写的很好。面试会有很好的帮助的,只能说面试加油啊。
这次我太饿了,写不下去了,我要回家。。。
903e

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树