python之路之正则表达式
2016-05-05 08:01
363 查看
匹配格式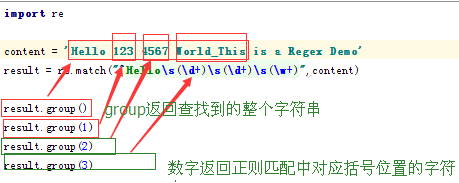

 二、search:在字符串的任意位置查找,返回一个匹配值
二、search:在字符串的任意位置查找,返回一个匹配值
其它链接:http://blog.csdn.net/whycadi/article/details/2011046
^ 匹配字符串的开头
$ 匹配字符串的结尾
. 除了换行符外的所有字符
[...] 用来表示一组字符,,单独列出:[amk]匹配'a','m'或'k'
[^..] 不在[]中的字符:[^abc]匹配除了a,b,c之外的字符
* 匹配0个或多个
+ 匹配1个或多个
? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
{n,} 精确匹配n个前面的表达式
{n,m} 匹配n到m次由前面的正则表达式定义的片段,贪婪方式
a|b 匹配a或b
() 匹配括号内的表达式,也表示一个组
\w 匹配字母数字
\W 匹配非字母数字
\s 匹配任意空白符
\S 匹配任意非空白符
\d 匹配任意数字
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果存在换行,只匹配换行前的结束字符串
\z 匹配字符串结束
\G 匹配最后匹配完成的位置
\b 匹配一个单词的边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界,'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'
\n 匹配一个换行符
\t 匹配一个制表符
\1..\9 匹配第n个分组的子表达式
正则表达式常用5种操作:
re.match(pattern,string) #从字符串的开头开始匹配,匹配必须与字符串的开头一致,返回一个匹配值
re.search(pattern,string) #从字符串的任意位置匹配,返回一个匹配值
re.split() #按匹配分隔字符串,默认为空格
re.findall(pattern,string) #找到所有的匹配,返回列表
re.sub(pattern,repl,string,count) #找到所有匹配,并替换掉
一:match的使用方法:从字符串的开头开始匹配贪婪匹配:.* 使自己尽量获取最多的值 与非贪婪匹配:.*? 使大家都可以获取最多的值
匹配模式: S可以使.匹配新行,即使.可以匹配任意字符
import re
content = """Hello 1234567 World_This
is a Regex Demo"""
result = re.match("^He.*?(\d+).*?Demo$",content,re.S)
print(result.group())
print(result.group(1))
结果:
vHello 1234567 World_This
is a Regex Demo
1234567match的缺点:从字符串的开头匹配,开头必须一致二、search:在字符串的任意位置查找,返回一个匹配值import re
content = """Extra strings Hello 1234567 World_This is a Regex Demo Exit"""
result = re.search("He.*?(\d+).*?Demo",content)
print(result.group())
print(result.group(1))
结果:
Hello 1234567 World_This is a Regex Demo
1234567三、sub:查找并替换
其它链接:http://blog.csdn.net/whycadi/article/details/2011046

相关文章推荐
- 模块间的调用
- python2.7.x的字符串编码到底什么鬼?(中文和英文的处理)
- python 大小写转换函数
- 【Python】【辅助程序】练手小程序:记录外网动态IP地址
- Python 迭代器和生成器
- 关于python的for语句
- libpython2.7.so.1.0 cannot open的解决方法
- 使用Python判断质数(素数)的简单方法讲解
- Python环境下搭建属于自己的pip源的教程
- Python使用Paramiko模块编写脚本进行远程服务器操作
- Python中内建函数的简单用法说明
- Python核心编程-第五章
- python 错误、异常
- python 测试与调试(test)
- Python爬虫: 抓取One网页上的每日一话和图
- python的json模块,针对decimal类型直接dumps报错
- Python文件读写基础
- Python 类与元类的深度挖掘 II
- Python-量化分析之路
- python(二)拾遗