理解GBDT算法(三)——基于梯度的版本
2016-05-02 22:08
190 查看
理解GBDT算法(三)——基于梯度的版本
时间:2015-03-31 18:15:53 阅读:301 评论:0 收藏:0 [点我收藏+]标签:gbdt 梯度 残差 代价函数 回归树
上一篇中我们讲到了GBDT算法的第一个版本,是基于残差的学习思路。今天来说第二个版本,可以说这个版本的比较复杂,涉及到一些推导和矩阵论知识。但是,我们今天可以看到,两个版本之间的联系,这个是学习算法的一个重要步骤。
这篇博文主要从下面这几个方面来说基于梯度的GBDT算法:
(1)算法的基本步骤;
(2)其中的学数学推导;
(3)基于梯度的版本和基于残差的版本之间的联系;
在讲解算法的详细步骤之前,我们可以先明确一个思路,就是梯度版本的GBDT是用多类分类Multi-class classification 的思想来实现的,或者可以说GBDT的这个版本融入到多类分类中可以更好的掌握。
1. 算法的基本步骤
首先网上很多讲解博客都会出现下面这个图:
那么也就是说梯度版的GBDT的算法主要有8个步骤。
(0)初始化所有样本在K个类别上的估计值。
F_k(x)是一个矩阵,我们可以初始化为全0,也可以随机设定。如下:
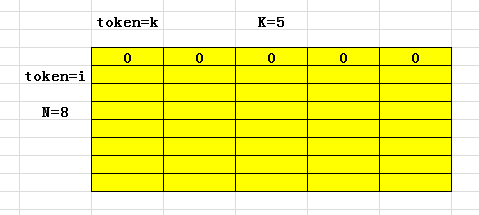
上面的矩阵中,我们假设有N=8个样本,每个样本可能会属于K=5个类别中的一个,其中估计值矩阵F初始化为0.
除此之外,这8个训练样本都是带着类别标签的,例如:

说明第i=1个样本是属于第3类的。
(1)循环下面的学习更新过程M次;
(2)对没有样本的函数估计值做logistic变换。
我们在前面介绍Logistic回归的时候提到,Logistic函数一个重要的特性就是可以转换为0~1之间的概率值,我们通过下面的变换公式就可以把样本的估计值转换为该样本属于某一类的概率是多少:
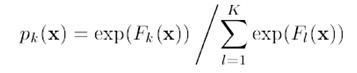
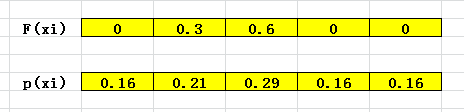
可以看到样本初始的时候每个类别的估计值都是0,属于类别的概率也是相等的,不过,随着后面的不断更新,其估计值不一样了,概率自然也就差别开来。
比如下面:
(3)遍历所有样本的每个类别的概率
这一步需要注意,遍历的是每个类别,而不是所有样本。如下:
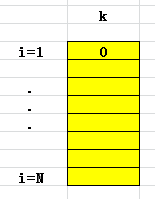
为什么这里是按照类别逐个学习呢?因为后面需要给每个类别k学习出一个回归树。
(4)求每个样本在第k类上概率梯度
上面一步中,我们有了许多个样本属于某个类别k的概率,以及它们是否真正属于类别k的概率(这些样本都是训练样本,所以它们是否属于某个类别都是已知的,概率为0/1)。那么这个就是一个典型的回归问题。我们当然可以用回归树的算法来求解(注,这里就是多类分类问题和GBDT联系的关键)。
我们通过常见的建立代价函数,并求导的梯度下降法来学习。代价函数是对数似然函数的形式为:
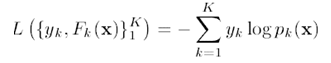
对这个代价函数的求导,我们可以得到:
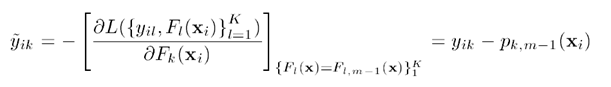
(详细的推导过程下一节给出)
有没有发现这里的求导得到的梯度形式居然是残差的形式:第i个样本属于第k个类别的残差 = 真实的概率 - 估计的概率。
这一步也是残差版本和梯度版本的联系。
这些的梯度也是下面我们构建回归树的学习方向。
(5)沿着梯度方法学习到J个叶子结点的回归树
学习的伪代码:
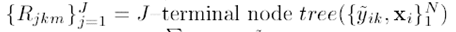
我们输入所有样本xi, i = 1~N, 以及每个样本在第k个类别上概率的残差作为更新方向,我们学习到有J个叶子的回归树。学习的基本过程和回归树类似:遍历样本的特征维数,选择一个特征作为分割点,需要满足最小均方差的原则,或者满足【左子树样本目标值(残差)和的平方均值+右子树样本目标值(残差)和的平方均值-父结点所有样本目标值(残差)和的平方均值】最大的准则,一旦学习到J个叶子结点,我们就停止学习。结果是该回归树中每个叶子上都会有许多个样本分布在上面。
记住:每个叶子上的样本,既有自己属于类别k的估计概率,也有真实概率,因为后面求增益需要用到它们。
(6)求每个叶子结点的增益
每个结点的增益计算公式为:
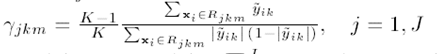
注意后标,每个叶子结点j都有一个增益值(不是向量,是值)。计算的时候需要用到该叶子结点上的所有样本的梯度。
换句话说,每个叶子结点都可以计算出一个增益值,记住是值啊!
(7)更新所有样本在第k类下的估计值
上一步中求得的增益是基于梯度计算得到的,而且前面说到的梯度和残差有一定的关联,我们可以利用这个增益更新样本的估计值。
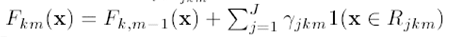
第m次迭代中的第k类下,所有样本的估计值F可以通过上次迭代m-1中,这些样本的估计值+增益向量求得。注意,这个增益向量需要把所有的J个叶子结点的增益值求和,然后和向量1相乘,而得。
也就是我们上面讲的,第k类的所有样本的估计值是一列:
也就是按列更新,前面有对类别数k的循环,所以每一类(每一列)的估计值都可以更新。一定记住是按列更新,每一类(每一列)都建立一个回归树来更新下去,最后原始的K类的N个样本的估计值矩阵都更新了一遍,带着这个新的估计值矩阵,我们进入下次m+1次的迭代学习。
如此,迭代学习M次之后,我们可以得到最终的所有样本在所有类别下的估计值矩阵,基于这个估计值矩阵,我们可以实现多类分类。
这样,基于梯度版本的GBDT算法的所有详细步骤我们都说完了。
2. 公式推导
上面建立的代价函数是对数似然函数的形式:对这个代价函数的求导,我们可以得到:
那么其中的详细推导过程是什么呢?

其中涉及到对数函数的求导,主要是最后一步,yi是样本属于第k类的真实概率,故yi就是0/1数,而且K个类别中只可能属于一个类别,也就是说只有一个yi是1,其余全是0,所以有最后一步推导结果。
3. 两个版本之间的联系
前面我们提到的一些联系,这儿再总结一下:基于残差的版本四把残差作为全局方向,偏向于回归的应用。而基于梯度的版本是把代价函数的梯度方向作为更新的方向,适用范围更广。
如果使用Logistic函数作为代价函数,那么其梯度形式和残差的形式类似,这个就说明两个版本之间是紧密联系的,虽然实现的思路不同,但是总体的目的是一样的。或者说残差版本是梯度版本的一个特例,当代价函数换成其余的函数,梯度的版本仍是适用的。
参考:
http://blog.csdn.net/w28971023/article/details/43704775
http://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/1976562.html
http://blog.csdn.net/kunlong0909/article/details/17587101
http://blog.csdn.net/puqutogether/article/details/44752611

相关文章推荐
- 深入理解:overflow:hidden——溢出,坍塌,清除浮动
- 面向对象
- [转载]50个Demo展示HTML5无穷的魅力
- 菜逼的Unity学习笔记(二)
- 第6周 C语言及程序设计提高例程-22 用指针法访问数组元素
- 数据分析与挖掘 - R语言:K-means聚类算法
- 阿里云X-Forwarded-For 发现tomcat记录的日志全部来自于SLB转发的IP地址,不能获取到请求的真实IP。 - Draco - 博客频道 - CSDN.NET
- Linux系统服务
- 火车头采集器 截取字符串 正则表达式
- js ES3执行上下文
- atoi函数与scanf中%*c及%[^\n]的简单讲解
- IPerf网络测试工具
- HDU1085 Holding Bin-Laden Captive!
- iOS --Runtime机制
- 【Unity】11.8 关节
- 1012-L专题三
- 第十一周上机实践项目——项目2-存储班长信息的学生类
- BestCoder Round #82 ztr loves lucky numbers
- LightOJ 1331-Agent J【计算几何】
- 不更水题了。。。