hadoop高可用集群环境详解
2016-04-29 11:20
691 查看
YD~随风
原理简解
hadoop
组成:HDFS, MapReduce
hdfs 分布式文件系统
流式数据访问 hdfs的构建思路是 一次写入、多次读取是最高效的访问模式
hdfs同样也有快(block)的概念,但是大的多,默认为64MB。与单一磁盘上的文件系统相似,hdfs上的文件也被划分为块大小的多个分块
作为独立的存储单元。但与其他文件系统不同的是,hdfs中小于一个块大小的文件不会占据整个块的空间
hdfs中的块为何如此之大:hdfs的块比磁盘的块大,其目的是为了最小化寻址开销,如果块设置得足够大,从磁盘传输数据的时间会明显
大于定位整个块开始位置所需的时间,因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率
namenode 和 datanode
hdfs集群有两类节点以管理者-工作者模式运行,即一个namenode(管理者)和多个datanode(工作者)。namenode管理文件系统的命名空间。
它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。namenode也
记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时由数据节点重建
基于后面的两个,之后在研究
其实说白了,hdfs里面有namenode 和 datanode ,namenode为命名空间,也是master,下发任务,datenode为数据节点,专门干活,执行任务存数据
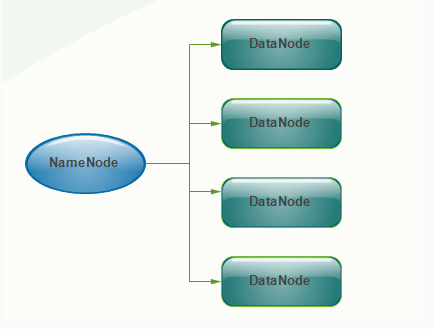
不过这样看,有单点问题,
hadoop中的namenode好比人的心脏,绝对不可以停止工作,在hadoop2.0中新的namenode不再是一个,可以有多个(目前只支持2个)
每一个都有相同的职能,一个是active状态的,一个是standby状态的,当集群运行时,只有active状态的namenode是正常工作的,standby
状态的namenode是处于待命状态的,时刻同步active状态namenode的数据。一旦active状态的namenode不能工作,通过手工或者自动切换,
standby状态的namenode就可以转变为active状态的,就可以继续工作了,
hadoop2.0中,两个namenode的数据其实是实时共享的,新hdfs采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者
NFS进行共享,nfs是操作系统层面的,journalnode是hadoop层面的我们这里使用journalnode集群

两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,
会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己
的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失
数据,或者产生错误的结果。为了保证这点,这就需要利用使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,
当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态
我这里是做了4台 。 这里我说一下,这个journalnode最少三台,也就是最起码是奇数,数据节点也弄三台吧
namenode datanode zookeeper year journalnode
192.168.10.36 hadoop-master-01 是 否 是 否 否
192.168.10.39 hadoop-master-03 是 是 是 是 是
192.168.10.37 hadoop-slave-01 否 是 是 否 是
192.168.10.38 hadoop-slave-02 否 是 否 否 是
前期的环境都弄好,我这里系统是centos7,我将自带的java卸了,自己装了一个
jdk-8u72-linux-x64.rpm

环境变量配好
export JAVA_HOME=/usr/java/jdk1.8.0_72
export CLASSPATH=.:$JAVA_HOME/jreb/rt.jar:$JAVA_HOMEb/dt.jar:$JAVA_HOMEb/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
好了,准备好,那就开始zookeeper。
我们看看配置文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.4.6/data
clientPort=2181
dataLogDir=/tmp/zookeeper/log
server.1=hadoop-master-01:2888:3888
server.2=hadoop-master-03:2888:3888
server.3=hadoop-slave-01:2888:3888
后面别忘了创建那个小文件
好了,zk完了,
开始hadoop。
wget http://apache.fayea.com/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
hadoop-2.7.2.tar.gz 最新版本
对了,ssh免密码登陆,这个别忘,因为Hadoop需要通过SSH登录到各个节点进行操作
(1)CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置,
#RSAAuthentication yes
#PubkeyAuthentication yes
(2)输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh文件夹,
然后将公钥拷贝到其他机器上生成authorized_keys
测试一下
好了,解包hadoop
创建几个数据目录在/home/hadoop data name temp
我们开始看配置
这里要涉及到的配置文件有7个:
~/hadoop-2.7.2/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_72 我直接在这个文件里修改了一下环境变量
~/hadoop-2.7.2/etc/hadoop/yarn-env.sh 这个也是环境的一些配置
~/hadoop-2.7.2/etc/hadoop/slaves 这个里面是很明显,都是slave,datanode,
~/hadoop-2.7.2/etc/hadoop/core-site.xml 这里是namenode的配置文件
~/hadoop-2.7.2/etc/hadoop/hdfs-site.xml hdfs的配置文件
~/hadoop-2.7.2/etc/hadoop/mapred-site.xml mapreduce
~/hadoop-2.7.2/etc/hadoop/yarn-site.xml yarn的配置
/usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value> 这里定义namenode,他的数据目录
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/temp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>ha.zookeeper.quorum</name> 以及注册与zk的配置
<value>hadoop-master-01:2181,hadoop-master-03:2181,hadoop-slave-01:2181</value>
</property>
</configuration>
~
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop-master-01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop-master-01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop-master-03:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop-master-03:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-master-03:8485;hadoop-slave-01:8485;hadoop-slave-02:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
这里的配置就是允许它用户连接
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
/usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master-03</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi /usr/local/hadoop/etc/hadoop/slaves
hadoop-master-03
hadoop-slave-01
hadoop-slave-02
然后将本机的 hadoop 直接拷贝到其他机器。什么防火墙啊。。。主机名啊都改好
192.168.10.36 hadoop-master-01
192.168.10.37 hadoop-slave-01
192.168.10.38 hadoop-slave-02
192.168.10.39 hadoop-master-03
开始启动。
在master1上
启动journalnode集群
sbin/hadoop-daemons.sh start journalnode
bin/hadoop-daemons.sh start journalnode
执行jps命令,可以查看到JournalNode的java进程pid
格式化zkfc,让在zookeeper中生成ha节点
在master1上
hdfs zkfc –formatZK
[zk: localhost:
2181
(CONNECTED)
1
] ls /hadoop-ha
[ns]
在master1上 因为有两个namnode。这台格式化后,将数据同步到另一台上,手动考培,或者执行命令
格式化hdfs
hadoop namenode –format
用命令同步,得先把目前这台启动起来
sbin/hadoop-daemon.sh start namenode
然后来到第二台namenode master-03 执行
hdfs namenode -bootstrapStandby 同步
然后开启 sbin/hadoop-daemon.sh start namenode
然后继续启动datanode 在master1
sbin/hadoop-daemons.sh start datenode
然后启动yarn 在你所配置yarn的那台机器上启动,
sbin/start-yarn.sh
最后启动zkfc
sbin/hadoop-daemons.sh start zkfc
ok,我们最后看jps




测试
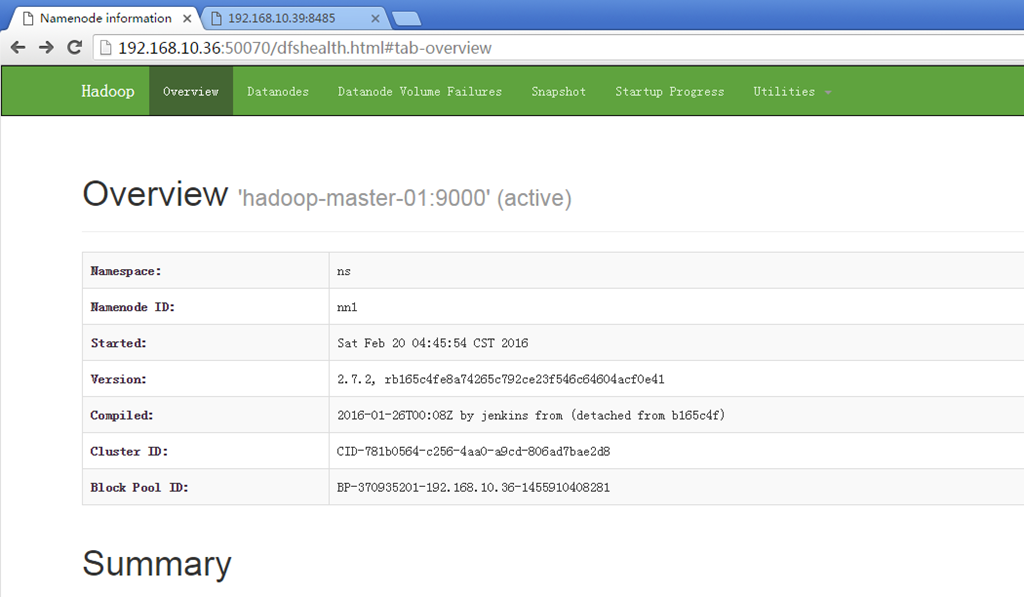
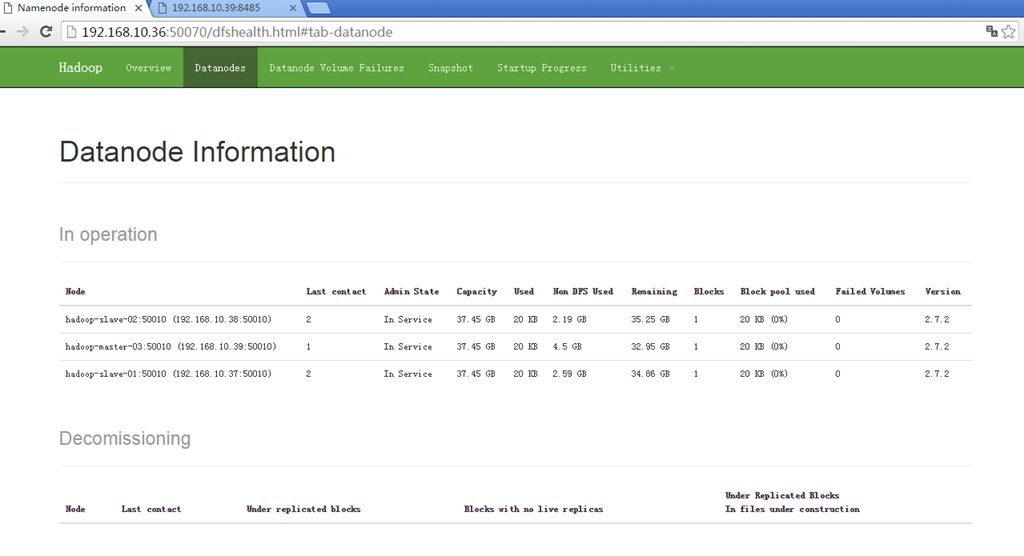
我创建了文件夹以及文件测试


好的,hadoop就算搭建完了,不过路还长!!!

相关文章推荐
- 如何让自己的网站获得过万流量
- 垂直应用架构
- iOS架构师之路:慎用继承
- 网站集成QQ登录功能
- 地方网站赚钱超容易!学会这个就行了
- 使用inotify和git pull 实现网站自动部署(附wordpress插件)
- Jekyll静态网站后台引擎使用教程
- mongo 分片Replica Sets+Sharding架构
- 详细分析SOA的十大设计原则
- 网站集成QQ登录功能
- 微服务架构只是个 “技术的浪潮 、流行” ?
- 电商网站架构设计
- 软件架构的典型组成部分-安全性
- 软件架构的典型组成部分-资源管理
- <<架构漫谈>>读后感
- Ed2k协议背景介绍及eMule协议的整体架构
- 《架构漫谈》有感
- 架构漫谈读后总结
- 当安卓官网打不开的时候可以试试这个网站
- 《架构漫谈阅读笔记》