机器学习调参-模型选择
2016-04-26 16:24
288 查看
本文主要介绍机器学习模型中超级参数(hyperparameter)的调优问题(下文简称为调参问题),主要的方法有手动调优、网格搜索、随机搜索以及基于贝叶斯的参数调优方法。因为模型通常由它的超级参数确定,所以从更高的角度看调参问题就转化为模型选择问题。
H={h1,h2,...,hN},则需要的计算次数为∏i=Ni=1|hi|,(i=1,2,...,N),|hi|表示超参hi的取值个数。
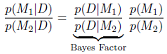
欠拟合,采取增加模型容量的方法,如将weight decay 设为0
模型有bug,将训练数据集减小,再次训练看训练误差是否能减小
不能很好解释的问题
对于非凸优化问题模型,当学习率较小时,随着迭代次数增加,损失函数停滞在较大的值上。
贝叶斯模型选择
1.Robert C P. Machine Learning, a Probabilistic Perspective[J]. Chance, 2014.
手动调优
需要较多专业背景知识。网格搜索
先固定一个超参,然后对其他各个超参依次进行穷举搜索,超参集合为H={h1,h2,...,hN},则需要的计算次数为∏i=Ni=1|hi|,(i=1,2,...,N),|hi|表示超参hi的取值个数。
随机搜索
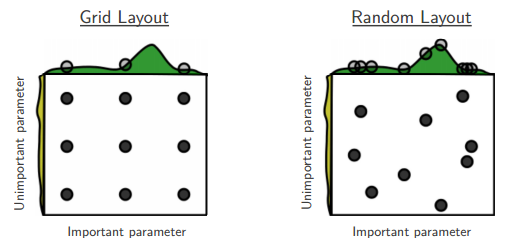
在N维参数空间按某种分布(如正态分布)随机取值,因为参数空间的各个维度的重要性是不等的,随机搜索方法可以在不重要的维度上取巧。如下图所示,按网格搜索的方式进行搜索时,由于在非重要维度上取值无效,因此相当于只取了3个有效点。随机取值相同的参数空间,则可能达到9个有效搜索点。贝叶斯方法
从模型选择的角度来,通过计算在已知数据的情况下,哪种模型的后验概率大即选择哪种模型,公式如下,这种方法偏向于选择简单的模型,详见MLAPP通用的分析方法
如果训练误差和验证误差都停滞在一个很大的值上,那么可能的原因和可以尝试的解决方案:欠拟合,采取增加模型容量的方法,如将weight decay 设为0
模型有bug,将训练数据集减小,再次训练看训练误差是否能减小
不能很好解释的问题
对于非凸优化问题模型,当学习率较小时,随着迭代次数增加,损失函数停滞在较大的值上。
参考
1.Bengio etc.2015,deep learning贝叶斯模型选择
1.Robert C P. Machine Learning, a Probabilistic Perspective[J]. Chance, 2014.

相关文章推荐
- 机器学习中关于正则化的理解
- 机器学习之模型选择(交叉验证)
- 学习理论之模型选择——Andrew Ng机器学习笔记(八)
- 规则化和模型选择(Regularization and model selection)
- 模型选择之交叉验证
- 模型选择之特征选择
- Caffe调参经验资料文章
- python 中bayes模型超参数并行网格搜索 程序分析
- 数据挖掘之从数据中学习
- [机器学习] Coursera笔记 - 机器学习应用的建议-Part1
- Prophet(预言者)facebook时序预测----论文总结以及调参思路
- 《Spark机器学习》笔记——Spark分类模型(线性回归、朴素贝叶斯、决策树、支持向量机)
- 超参数搜索之网格搜索与并行搜索
- Random Forest和Gradient Tree Boosting如何调参
- XGBoost参数调优完全指南(附Python代码)
- XGBoost-参数解释
- 用 Grid Search 对 SVM 进行调参
- Coursera | Andrew Ng (02-week3-3.2)—为超参数选择合适的范围
- Coursera | Andrew Ng (02-week-3-3.1)—调参处理
- Coursera | Andrew Ng (02-week-1-1.11)—神经网络的权重初始化