机器学习中关于正则化的理解
2014-08-18 09:47
393 查看
正则化的目的:避免出现过拟合(over-fitting)
经验风险最小化 + 正则化项 = 结构风险最小化
经验风险最小化(ERM),是为了让拟合的误差足够小,即:对训练数据的预测误差很小。
但是,我们学习得到的模型,当然是希望对未知数据有很好的预测能力(泛化能力),这样才更有意义。
当拟合的误差足够小的时候,可能是模型参数较多,模型比较复杂,此时模型的泛化能力一般(过拟合)。于是,我
们增加一个正则化项,它是一个正的常数乘以模型复杂度的函数,aJ(f),a>=0
用于调整ERM与模型复杂度的关系。
结构风险最小化(SRM),相当于是要求拟合的误差足够小,同时模型不要太复杂(正则化项的极小化),这样得到
的模型具有较强的泛化能力。
奥卡姆剃刀原理(Occam's
razor)与正则化实际上是一个道理。
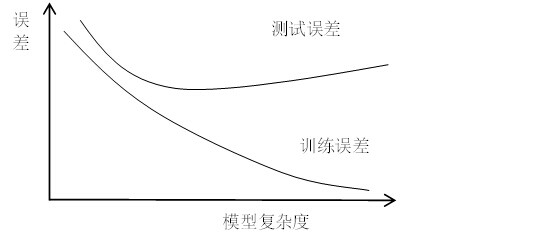
给出一个机器学习中经典的图,模型越复杂,训练误差越小,但是测试误差先变小后变大,继而出现过拟合。
以决策树的剪枝(pruning)为例:
通过ID3或C4.5算法生成决策树往往会发生过拟合,因为它是对结点通过特征选取来选择特征并生成一棵决策
树,这将导致树因枝叶过多(IF-THEN过多)。树的剪枝过程是通过从已生成的树上剪掉一些子树或叶节点,从而对
树进行简化。
决策树的剪枝通过极小化决策树整体的损失函数来实现,这等价于正则化的极大似然估计:
&space;=&space;C%5Cleft(&space;T&space;%5Cright)&space;+&space;%5Calpha&space;%5Cleft%7C&space;T&space;%5Cright%7C$)
其中,C(T)表示模型对训练数据的拟合程度,

为正则化项,这里用树T的叶结点个数表示树的复杂度。
参考资料《统计学习方法》李航
经验风险最小化 + 正则化项 = 结构风险最小化
经验风险最小化(ERM),是为了让拟合的误差足够小,即:对训练数据的预测误差很小。
但是,我们学习得到的模型,当然是希望对未知数据有很好的预测能力(泛化能力),这样才更有意义。
当拟合的误差足够小的时候,可能是模型参数较多,模型比较复杂,此时模型的泛化能力一般(过拟合)。于是,我
们增加一个正则化项,它是一个正的常数乘以模型复杂度的函数,aJ(f),a>=0
用于调整ERM与模型复杂度的关系。
结构风险最小化(SRM),相当于是要求拟合的误差足够小,同时模型不要太复杂(正则化项的极小化),这样得到
的模型具有较强的泛化能力。
奥卡姆剃刀原理(Occam's
razor)与正则化实际上是一个道理。
给出一个机器学习中经典的图,模型越复杂,训练误差越小,但是测试误差先变小后变大,继而出现过拟合。
以决策树的剪枝(pruning)为例:
通过ID3或C4.5算法生成决策树往往会发生过拟合,因为它是对结点通过特征选取来选择特征并生成一棵决策
树,这将导致树因枝叶过多(IF-THEN过多)。树的剪枝过程是通过从已生成的树上剪掉一些子树或叶节点,从而对
树进行简化。
决策树的剪枝通过极小化决策树整体的损失函数来实现,这等价于正则化的极大似然估计:
其中,C(T)表示模型对训练数据的拟合程度,
为正则化项,这里用树T的叶结点个数表示树的复杂度。
参考资料《统计学习方法》李航

相关文章推荐
- 关于正则化话的理解
- 关于机器学习中Precision和Recall的概念的理解
- 机器学习中正则化项L1和L2的直观理解
- 机器学习中正则化项L1和L2的直观理解
- 机器学习中正则化的理解
- 关于协方差矩阵在机器学习中的理解
- 关于正则化到底是什么,及cnnmatlab代码中 'L2Regularization',1e-4,...的理解
- 关于机器学习中比较深奥的熵的理解
- 【机器学习】关于CNN中1×1卷积核和Network in Network的理解
- 关于机器学习的定义的理解
- 关于机器学习神经网络的基本理解
- 机器学习中正则化项L1和L2的直观理解
- 机器学习关于过拟合和正则化的笔记
- 关于正则化抽象定义的通俗理解
- 机器学习中正则化项L1和L2的直观理解
- 机器学习中正则化项L1和L2的直观理解
- 关于正则化的理解
- 机器学习中正则化项L1和L2的直观理解
- 转载 机器学习--正则化理解
- 机器学习中正则化的理解