Visual Genome数据集介绍
2016-04-25 16:05
239 查看
Visual Genome数据集
Visual Genome数据集,是由斯坦福大学人工智能实验室主任李菲菲与几位同事合作开发的。数据集及论文网址:http://visualgenome.org/
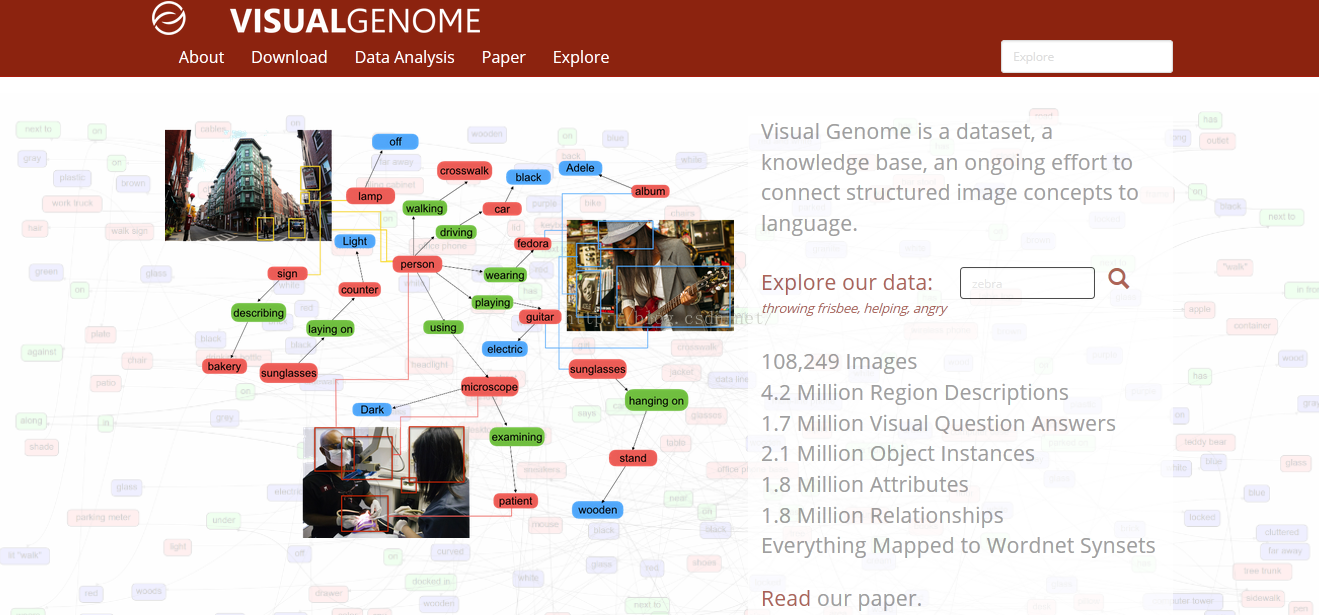
一、作者的初衷是什么?为什么要设计出这样一个数据集?
1.作者在视觉领域研究了多年,一直致力于寻求最好的算法,来达到更好的效果。但是受人类对于世界的认识过程的启发,作者认为,教计算机理解图片,其实和教儿童认识世界的过程是类似的。儿童的眼睛就类似一对生物相机,3岁时他已经浏览过数亿张真实世界的图像,这是一个非常庞大的训练数据集。由此作者认为,不去一味的寻找算法,转而考虑如何构建一个丰富的数据集,或许可以有更好的效果。
2.计算机视觉的行程,最初是感知任务,例如图像分类等,能够达到给图像贴上标签的效果。要让计算机更加智能,就要过渡到认知来实现。认知不仅仅识别出图像,还要理解图片。
目前多数数据集是针对感知任务,并没有针对认知任务做出更多拓展。缺乏一个数据集。
3.一张图片有丰富的场景,但很难用一个句子完全描述。现在的数据库例如 Flickr 30K 和 MS-COCO 专注于对图像进行高层次的描述。
对图像进行认知,作者倾向于,对图像区域化分割,不同区域进行详细描述,对于 Visual Genome 数据集里的每一张图片,收集了图片中不同区域的 42 种描述,提供了更加密集和完全的图像描述。这样,一张图像上就会存在丰富的注释描述。因此,提出了一个自己设计的新的数据集。
二、数据集的设计思想
为了更彻底的理解图像,论文提到三个关键元素,需要添加到数据集中。整体来看,这三个关键点的实现如下:1、将视觉概念落实到语义层面
这个落实grounding在文中反复提到,包括其他几篇论文也多次提到。从文章来看,grounding就是对图片中的每一个关键部分,都要对应有详细的描述。每一个对象,关系,属性,都要在图片中用边界框标定出来,得到对应的坐标,边界框和文字是一一对应。2、基于多区域图片的更加完整描述和问答
更加完整的描述和问答,在论文主要提到的是,采用crowdsource策略,大量人工密集注释。并通过投票策略等,对这些描述问答做筛选,保证准确性。因此,可以说Visual Genome是首个提供物体的交互和属性的详细标签,将视觉概念落实到语义层面的数据集。3、对图片各个组成的形式化表示
形式化表示,在论文中具体表现在,通过将注释词汇映射到wordnet中规范化;对每个区域构建一个组织关系图的形式;将一张图片上的所有区域图,联结起来,构成一个完整的场景图。三、Visual Genome数据集有什么构成?
VisualGenome 数据集包括 7 个主要部分:l 区域描述
l 对象
l 属性
l 关系
l 区域图
l 场景图
l 问答对
要对图像进行理解的研究,论文从收集描述和问答对开始。文本没有任何长度和词汇的限制。然后从描述中提取对象、属性和关系。这些对象、属性和关系一起构造了场景图
2.1 多区域和对它们的描述
在真实世界中,一个简单的总结,往往不足以描述图片的所有内容和交互。相反,一个自然的扩展方法是,对图像的不同区域进行分别描述。在 Visual Genome 中,收集了对图像不同区域的描述,每一个区域都由边框进行坐标限定。不同的区域之间,允许有高度的重复,而描述会有所不同。数据集中平均对每一张图片有 42 种区域描述。每一个描述都是一个短语包含着从 1 到 16 个单词长度,以描述这个区域。2.2 多个物体与它们的边框
在数据集中,平均每张图片包含21个物体,每个物体周围有一个边框。不仅如此,每个物体在WordNet中都有一个规范化的ID。举例来说,man和person,会被映射到man.n.03。相似的,person被映射到person.n.01。随后,由于存在上位词man.n.03,这两个概念就可以加入person.n.01中了。这是一个重要的标准化步骤,以此避免同一个物体有多个名字(比如,man,person,human),也能在不同图片间,实现信息互联
词汇标准化的好处,不同图片间可实现互联。至于为何要实行按互联?
我觉得在人类真实认知过程中,我们总会不自觉的,对不同场景进行相互关联,以利于更好的学习理解。作者这样设计,就是完全模拟人类的认知。如何利用互联,更好的学习?
2.3 属性
VisualGenome中,平均每张图片有16个属性。一个物体可以有0个或是更多的属性。属性可以是颜色(比如yellow),状态(比如standing),等等。提取这些物体自身的属性。从短语“yellow fire hydrant”里,可提取到了“fire hydrant”有“yellow”属性。和物体一样,将属性在WordNet中规范化;比如,yellow被映射到yellow.s.01。2.4 一组关系
“关系”将两个物体关联到一起。例如,从区域描述“man jumping over fire hydrant”中,可提取到物体man和物体fire hydrant之间的关系是jumping over。这些关系是从一个物体(也叫主体)指向另一个物体(也叫客体)的。在这个例子里,主体是man,他正在对客体fire hydrant表现出jumping over的关系。每个关系也在WordNet中有规范化的synset ID:jumping被映射到jump.a.1。数据集中的每张图片平均包含18个关系。
2.5 一组区域图
将从区域描述中提取的物体、属性、以及关系结合在一起,每42个区域创造一幅有向图表征。每幅区域图都是对于图片的一部分所做的结构化表征。区域图中的节点代表物体、属性、以及关系。物体与它们各自的属性相连,而关系则从一个物体指向另一个物体。连接两个物体的箭头,从主体物体指向关系,再从关系指向其他物体。2.6 全景图
区域图是一张图片某一区域的表征,而将它们融合在一起,就得到一幅能表征整张图片的全景图。全景图是所有区域图的拼合,包括每个区域描述中所有的物体、属性、以及关系。通过这个方式,能够以更连贯的方式,连结起多个层次的全景信息。例如,某幅图中,左边的区域是“fire hydrantis yellow”,而中间的区域描述是“man is jumping over thefire hydrant”。这样就可以将它们拼合在一起,得到的是“man is jumping over a yellow firehydrant”。
2.7 问答
数据集中,每张图片都有两类问答:基于整张图片的随意问答(freeform QAs),以及基于选定区域的区域问答(region-based QAs)。每张图片收集有6个不同类型的问题:what,where,how,when,who,以及why。每张图片的问题都包含了这6个类型,每个类型至少有1个问题。区域问答,是通过区域描述来收集的。例如,我们通过“黄色消防栓”的描述收集到了这个区域问答:
“问:消防栓是什么颜色的?;答:黄色”。
区域问答对能够独立地研究如何优先运用NLP和视觉来回答问题。

相关文章推荐
- 时尚集团与深铁、港铁共探地铁商业运营经验
- 详述canvas(一)
- linux 命令积累
- Crosswalk/XwalkView研究
- UML类图几种关系的总结
- PHP 正则表达式 数组
- 宏解析
- HoloLens开发手记 - 使用配件 Working with accessories
- [转]C#程序员容易犯的10个错误
- JQuery Marquee插件(无缝滚动效果)- marquee.js
- opencv3 采集摄像头的画面canny化,或者读取视频
- 信息无障碍产品研究举例
- 《啊哈算法》第三章 暴力枚举
- Cocoa框架是
- APP 图标修改问题
- k3cloud 开发类
- 阶段冲刺5
- 编程珠玑 旋转字符串
- 数据存储之文件存储
- Javadoc转换chm帮助文档的两种方法总结