进程和线程--重磅推出--知识点梳理
2016-04-18 15:39
295 查看
【参考书籍】:《现代操作系统》
ps:堆栈由于历史的原因,有几个地方叫做堆栈,名称比较混乱:硬件中有一组寄存器称为堆栈,用来在中断发生的时候自动保存当前程序的状态信息(该操作由硬件自动完成);函数中有一个堆栈,也就是我们常提到的栈空间(函数中的变量)和堆空间(malloc,new)
【进程的三种状态】:就绪,运行,阻塞;运行表示正在run,就绪表示可以run,等待调度程序选中该进程,阻塞表示由于等待某个条件触发,暂时不能run;
【操作系统维护的进程表】:进程表存储了每个进程的相关信息,每个进程对应一个进程表项(说白了就是一个结构体),根据这些信息可以用来进行进程调度;下面是一个进程表项的大致介绍:
进程管理:寄存器、程序计数器(pc)、程序状态字寄存器、堆栈指针(?这个指的是哪个)、进程状态、优先级、调度参数、进程ID、父进程、进程组、信号、进程开始时间、使用cpu的时间(这里我们可以看到每个进程实际使用了多长的cpu时间)、子进程的cpu时间、下次报警的时间;
存储管理:正文段指针、数据段指针、堆栈段指针;(ps:?这个数据段指针、堆栈段指针,是否指的是进程的地址空间中对应的数据和堆栈的指针,不清楚,书中没有描述清楚)
文件管理:根目录、工作目录、文件描述符、用户ID、组ID;
【进程调度具体是如何做的】:下面讲述了进程调度发生的过程,首先说明进程调度的发生都是由于中断的触发(有可能是固定的定时中断,有可能是外部中断等等),当中断发生后,按照如下的步骤完成进程的调度:
1、硬件自动完成:将程序计数器pc、程序状态字寄存器、寄存器压入堆栈;
2、进入中断向量控制器;(ps:简单点说就是中断程序的入口地址);
3、中断程序开始是一段汇编程序,将刚才由硬件压入堆栈的数据copy到对应的进程表项中,删除堆栈中的数据;
4、运行由c语言写的中断服务程序(典型的读和缓冲输入);
5、运行进程调度程序,选择下一个要运行的进程;
6、交给汇编程序,将选中进程对应的进程表项中的程序计数器pc、程序状态字寄存器、寄存器等压入堆栈;
7、交给硬件,从堆栈中恢复选中进程的相关状态,继续执行,此时就换了一个进程;over!!!
【共享只读内存】:操作系统在实现的时候,为了节约资源,对于只读的内存,比如一段程序,多个进程是可以共享的,不过我们一般不需要关注这些;
【进程与线程设计的目的】:设计出进程的目的是为了提高cpu的利用率和响应速度,设计出线程的目的是为了提高进程的效率和响应速度,如出一辙啊;
【进程与线程的对比】:
1、用户空间中存储内容对比:当然如果线程都是在内核中调度,那么备份信息在内核的内存中,不在用户空间的内存中;
一个进程对应一个地址空间,地址空间存储的有:地址空间,全局变量,打开文件,子进程,即将发生的报警,信号与信号处理程序,账户信息;
一个进程中的多个线程,存在与该进程中的同一个地址空间,每个线程中自己存储的数据有:程序的堆栈,备份信息(程序状态字寄存器,程序计数器,寄存器)
2、切换速度对比:线程的切换速度快,在目前的多核处理器中有硬件支持线程切换,ns级可以完成;进程的切换要陷入到内核,是通过中断来完成的;
3、创建速度对比:线程的创建速度比进程快10-100倍,可以想象出来,创建线程的时候,不需要新的地址空间,操作系统中不需要新的进程表项;(当然这里比较的对象是用户空间线程,内核级线程不是这样的)
【Pthread提供的线程调用】:ieee定义的线程包
1、Pthread_create:线程创建
2、Pthread_exit::线程退出
3、Pthread_join :线程等待特定的线程退出
4、Pthread_yield :释放CPu运行另一个线程
5、Pthread_attr_init :创建并舒适化一个线程属性结构
6、Pthread_attr_destory:删除一个线程的属性结构
【线程的实现方式】:
1、用户空间中实现线程:优点:线程的切换速度非常快,几个指令就可以;缺点:对于会产生系统阻塞的线程(比如等待io,页面故障),会阻塞整个进程;
2、内核中实现线程:优点:可以很方便的使用系统调用,阻塞的问题解决了;缺点:内核中要维护线程表(里面存储上面我们说的线程的状态信息,包括pc,程序状态字寄存器、寄存器),内核中删除和创建线程的开销较大,线程调度的开销比用户空间中的线程实现相比大得多;
3、混合实现:每个内核级线程有一个对应的可以轮流调度执行的用户级线程集合;
【进程间通信】:
竞争条件:两个或者多个进程读写某些共享数据,程序的运行结果,取决于进程运行的精确时序,称为竞争条件;(比如多个进程共享内核数据结构,共享文件,共享某个标志位等);
应对竞争条件的一些低级方法,都或多或少有些毛病,不是特别好:but后面的信号量、互斥量都是在这些方法的基础上稍加改进得到的;
1、屏蔽中断:只能针对单cpu,多核CPU无效;
2、锁变量:需要硬件支持,这个其实与4是一样的;
3、严格轮换法:有忙等待的问题,效率低下;
4、TSL或XCHG指令:也是忙等待的问题,实际上是硬件通过原子操作实现了锁变量;使得以前需要两步的比较和写入,现在变成了一条指令交换数据,不会发生竞争;
(忙等待还可能产生优先级反转问题,进入死循环,其实我觉得也是一种死锁)
生产者消费者问题:对竞争条件的一个形象化的问题描述,直接使用一个普通的count会发生竞争条件,使得陷入无穷的等待;
信号量:>=0,信号量有down和up操作,这两个操作分别是原子操作不可分割,信号量的原子操作中有三步:信号量的检查、修改、可能发生的睡眠,这三步是不可分割的;信号量的实现主要是两点,一是使用TSL或XCHG锁定总线防止其他CPU访问,二是屏蔽当前CPU的中断免除不必要的调度切换;
信号量的作用:对于多个进程共享的变量,可以很方便的实现互斥;建立在互斥的基础上,可以实现进程间的同步;比如解决消费者生产者问题,如果要实现互斥,实现睡眠,需要3个信号量配合;
信号量的存储区域:信号量可以存储在系统内核中,通过系统调用访问;现代操作系统提供了进程间共享空间,信号量可以放在这里;在最坏的情况下可以共享文件;
互斥量:也就是借助XCHG的简单实现,能够实现对某个变量的互斥访问;互斥量在用户空间线程包中非常有用,实现简单非常高效;由于线程是一个人开发的,所以在互斥量保护的临界区中,使用Pthread_yeild可以方便跳转到其他线程;用互斥量解决消费者生产者问题,如果要使用睡眠而不只是忙等待,需要借助条件变量,也就是在互斥量保护的临界区中,用条件变量实现原子操作(睡眠和解锁互斥量),但是要注意,在一对多和多对多的情况下,条件变量睡眠解锁互斥量后该线程被阻塞,唤醒时必须退回到临界区之外,重新申请锁定互斥量,不然就会发生竞争条件;
互斥量的存储区域:存在进程的地址空间中,供多个线程共享,是很方便高效的;
管程:需要语言支持,即语言自动识别管程,自动加入互斥操作,面临的问题与互斥量是一样的,缺点是很多语言包括c语言,压根就不支持;
ps:信号量比较低级,一方面麻烦,程序员极容易发生错误,另一方面无法支持分布式系统不共享内存的情况;管程也类似;
消息传递:消息传递不是采用上面的共享内存的方式,比如两个进程间传递消息,采用两个缓冲区或者说两个信箱,这样并没有互斥操作,也就不会产生竞争条件,也没有死锁发生,并且支持分布式系统,而且支持阻塞不用忙等待;阻塞后由os的调度程序,决定是否满足条件唤醒;要解决的问题就是如何提高消息传递的效率,在同一台PC上的时候,效率相比信号量必然是低一些的;
屏障:进程组的同步机制,当进程组中所有进程都就绪准备进入下一个阶段的时候,才允许进入下一个阶段;
【进程调度】:没有绝对的好与坏,与系统的环境和需求有关系;
批处理系统调度:常关心的指标:吞吐量、周转时间、CPU利用率;一些非常简单拙劣的方法:
1、非抢占式的先来先服务;
2、最短时间优先;(适用条件是预知进程的运行时间)
3、最短剩余时间优先(2的抢占式版本);(适用条件是预知进程的运行时间)
交互式系统调度:常关心的指标:响应时间、均衡性;ps:实际中是下面几种调度的结合,我觉得
1、轮转调度:即划分时间片,根据时间片来调度,是最广泛,最简单公平的调度算法;一般时间片设置在20~50ms比较合适;
2、优先级调度:优先级高的先执行;可以结合优先级调度和轮转调度,同一优先级的进程使用轮转调度,做好低优先级的进程的调整工作防止饥饿现象;
3、最短进程调度:;也就是前面的最短时间优先,进程的时间根据历史信息估计,使用学习率alpha更新;
4、保证调度:保证每个进程或者每个用户常用cpu的时间比率;
5、彩票调度:给进程发彩票,选择中彩票的进程运行,我感觉与优先级调度是一个道理,但是灵活与跳跃性更好;
6、公平分享调度:不只是关注进程本身,关注进程的用户,保证每个用户使用cpu的占比,我感觉与保证调度中保证用户相似;
实时系统调度:常关心的指标:或多或少必须满足截止时间;截止时间:硬实时和软实时,调度程序的任务就是满足截止时间的要求调度进程;
策略和机制:将调度机制和调度策略分离,即将调度机制写成算法,算法中的参数由进程输入,这样父进程可以很好地控制子进程的调度策略;
【线程调度】:
用户级线程调度:内核看不到,仍然与前面调度进程的时候一样;在某个进程中运行线程调度程序,选择某个线程,在该线程运行完之前,该进程中的其他线程无法运行;优点是线程调度的切换速度快,硬件支持下ns级别;缺点是缺乏一个时间中断,将运行时间过长的线程切换;还有一个优点就是用户空间线程的调度可以程序员定制化;
内核级线程调度:内核级线程在内核中有一个线程表,内核像对待进程一样调度;优点:能够时间中断,不会某个线程运行时间过长;缺点:两个不同进程的线程之间切换的时候,与进程的切换开销相似,比较慢我估计在ms级别;but,内核调度的时候可以优先选择同一个进程下的不同线程,这样线程切换的开销就比进程切换的开销小不少,因为不需要修改内存映像和高速缓存,只需要保存线程运行的状态信息;所以这是一种好的折中;
【进程切换为什么花时间】:进程切换,首先要存储当前进程的状态信息(PC、PSW、寄存器)到内核中的进程表项,在许多系统中内存映像(例如页表内的内存访问位)也必须要保存,然后需要运行调度程序,选好下一个进程后需要拷贝该进程的内存映像到MMU,然后拷贝其状态信息,然后开始运行;同时切换进程会使得高速缓存失效,所以会发生两次高速缓存到内存的读写操作,一次是原进程离开,高速缓存写入内存,一次是新进程加载,内存进入高速缓存;因此进程切换非常花时间;比如这个时间开销是1ms;
【解答一些疑问】:
1、函数的堆数据是放在进程的地址空间中的么?答:函数的堆数据确实是在进程的地址空间中,对于多线程的进程,每一个线程都有自己的堆栈空间,保存函数过程信息;
2、进程的地址空间中存放了哪些信息?答:全局变量、打开的文件、即将发生的报警、信号与信号处理程序、账户信息等;再就是包含了线程存储的 堆栈,备份信息(pc,psw,寄存器);
3、一些其他问题:哲学家就餐问题,对IO访问互斥访问竞争建模;读者写者问题,对数据库的访问建模;
【unix系统中进程的一些知识】:
Unix把进程分成两大类:
一类是系统进程,另一类是用户进程。系统进程执行操作系统程序,提供系统功能,工作于核心态。用户进程执行用户程序,在操作系统的管理和控制下执行,工作于用户态。进程在不同的状态下执行时拥有不同的权力。
在Unix系统中进程由三部分组成,分别是进程控制块、正文段和数据段。Unix系统中把进程控制块分成proc结构和user结构两部分,proc存放的是系统经常要查询和修改的信息,需要快速访问,因此常将其装入内存
【进程线程间通信的方式】:
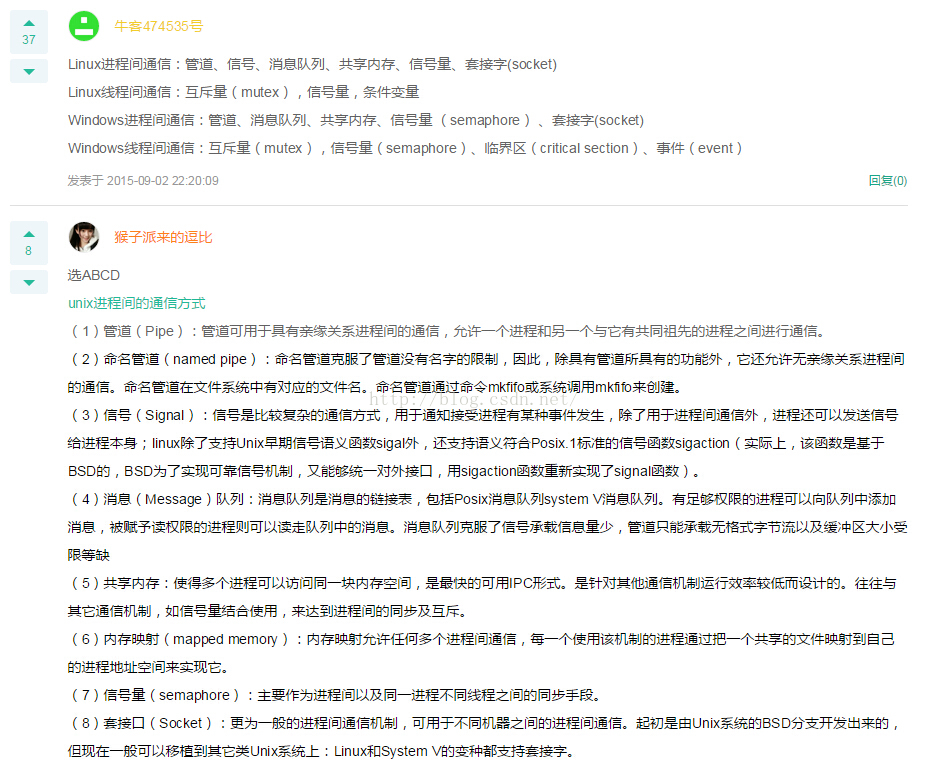
原创:香蕉麦乐迪
ps:堆栈由于历史的原因,有几个地方叫做堆栈,名称比较混乱:硬件中有一组寄存器称为堆栈,用来在中断发生的时候自动保存当前程序的状态信息(该操作由硬件自动完成);函数中有一个堆栈,也就是我们常提到的栈空间(函数中的变量)和堆空间(malloc,new)
【进程的三种状态】:就绪,运行,阻塞;运行表示正在run,就绪表示可以run,等待调度程序选中该进程,阻塞表示由于等待某个条件触发,暂时不能run;
【操作系统维护的进程表】:进程表存储了每个进程的相关信息,每个进程对应一个进程表项(说白了就是一个结构体),根据这些信息可以用来进行进程调度;下面是一个进程表项的大致介绍:
进程管理:寄存器、程序计数器(pc)、程序状态字寄存器、堆栈指针(?这个指的是哪个)、进程状态、优先级、调度参数、进程ID、父进程、进程组、信号、进程开始时间、使用cpu的时间(这里我们可以看到每个进程实际使用了多长的cpu时间)、子进程的cpu时间、下次报警的时间;
存储管理:正文段指针、数据段指针、堆栈段指针;(ps:?这个数据段指针、堆栈段指针,是否指的是进程的地址空间中对应的数据和堆栈的指针,不清楚,书中没有描述清楚)
文件管理:根目录、工作目录、文件描述符、用户ID、组ID;
【进程调度具体是如何做的】:下面讲述了进程调度发生的过程,首先说明进程调度的发生都是由于中断的触发(有可能是固定的定时中断,有可能是外部中断等等),当中断发生后,按照如下的步骤完成进程的调度:
1、硬件自动完成:将程序计数器pc、程序状态字寄存器、寄存器压入堆栈;
2、进入中断向量控制器;(ps:简单点说就是中断程序的入口地址);
3、中断程序开始是一段汇编程序,将刚才由硬件压入堆栈的数据copy到对应的进程表项中,删除堆栈中的数据;
4、运行由c语言写的中断服务程序(典型的读和缓冲输入);
5、运行进程调度程序,选择下一个要运行的进程;
6、交给汇编程序,将选中进程对应的进程表项中的程序计数器pc、程序状态字寄存器、寄存器等压入堆栈;
7、交给硬件,从堆栈中恢复选中进程的相关状态,继续执行,此时就换了一个进程;over!!!
【共享只读内存】:操作系统在实现的时候,为了节约资源,对于只读的内存,比如一段程序,多个进程是可以共享的,不过我们一般不需要关注这些;
【进程与线程设计的目的】:设计出进程的目的是为了提高cpu的利用率和响应速度,设计出线程的目的是为了提高进程的效率和响应速度,如出一辙啊;
【进程与线程的对比】:
1、用户空间中存储内容对比:当然如果线程都是在内核中调度,那么备份信息在内核的内存中,不在用户空间的内存中;
一个进程对应一个地址空间,地址空间存储的有:地址空间,全局变量,打开文件,子进程,即将发生的报警,信号与信号处理程序,账户信息;
一个进程中的多个线程,存在与该进程中的同一个地址空间,每个线程中自己存储的数据有:程序的堆栈,备份信息(程序状态字寄存器,程序计数器,寄存器)
2、切换速度对比:线程的切换速度快,在目前的多核处理器中有硬件支持线程切换,ns级可以完成;进程的切换要陷入到内核,是通过中断来完成的;
3、创建速度对比:线程的创建速度比进程快10-100倍,可以想象出来,创建线程的时候,不需要新的地址空间,操作系统中不需要新的进程表项;(当然这里比较的对象是用户空间线程,内核级线程不是这样的)
【Pthread提供的线程调用】:ieee定义的线程包
1、Pthread_create:线程创建
2、Pthread_exit::线程退出
3、Pthread_join :线程等待特定的线程退出
4、Pthread_yield :释放CPu运行另一个线程
5、Pthread_attr_init :创建并舒适化一个线程属性结构
6、Pthread_attr_destory:删除一个线程的属性结构
【线程的实现方式】:
1、用户空间中实现线程:优点:线程的切换速度非常快,几个指令就可以;缺点:对于会产生系统阻塞的线程(比如等待io,页面故障),会阻塞整个进程;
2、内核中实现线程:优点:可以很方便的使用系统调用,阻塞的问题解决了;缺点:内核中要维护线程表(里面存储上面我们说的线程的状态信息,包括pc,程序状态字寄存器、寄存器),内核中删除和创建线程的开销较大,线程调度的开销比用户空间中的线程实现相比大得多;
3、混合实现:每个内核级线程有一个对应的可以轮流调度执行的用户级线程集合;
【进程间通信】:
竞争条件:两个或者多个进程读写某些共享数据,程序的运行结果,取决于进程运行的精确时序,称为竞争条件;(比如多个进程共享内核数据结构,共享文件,共享某个标志位等);
应对竞争条件的一些低级方法,都或多或少有些毛病,不是特别好:but后面的信号量、互斥量都是在这些方法的基础上稍加改进得到的;
1、屏蔽中断:只能针对单cpu,多核CPU无效;
2、锁变量:需要硬件支持,这个其实与4是一样的;
3、严格轮换法:有忙等待的问题,效率低下;
4、TSL或XCHG指令:也是忙等待的问题,实际上是硬件通过原子操作实现了锁变量;使得以前需要两步的比较和写入,现在变成了一条指令交换数据,不会发生竞争;
(忙等待还可能产生优先级反转问题,进入死循环,其实我觉得也是一种死锁)
生产者消费者问题:对竞争条件的一个形象化的问题描述,直接使用一个普通的count会发生竞争条件,使得陷入无穷的等待;
信号量:>=0,信号量有down和up操作,这两个操作分别是原子操作不可分割,信号量的原子操作中有三步:信号量的检查、修改、可能发生的睡眠,这三步是不可分割的;信号量的实现主要是两点,一是使用TSL或XCHG锁定总线防止其他CPU访问,二是屏蔽当前CPU的中断免除不必要的调度切换;
信号量的作用:对于多个进程共享的变量,可以很方便的实现互斥;建立在互斥的基础上,可以实现进程间的同步;比如解决消费者生产者问题,如果要实现互斥,实现睡眠,需要3个信号量配合;
信号量的存储区域:信号量可以存储在系统内核中,通过系统调用访问;现代操作系统提供了进程间共享空间,信号量可以放在这里;在最坏的情况下可以共享文件;
互斥量:也就是借助XCHG的简单实现,能够实现对某个变量的互斥访问;互斥量在用户空间线程包中非常有用,实现简单非常高效;由于线程是一个人开发的,所以在互斥量保护的临界区中,使用Pthread_yeild可以方便跳转到其他线程;用互斥量解决消费者生产者问题,如果要使用睡眠而不只是忙等待,需要借助条件变量,也就是在互斥量保护的临界区中,用条件变量实现原子操作(睡眠和解锁互斥量),但是要注意,在一对多和多对多的情况下,条件变量睡眠解锁互斥量后该线程被阻塞,唤醒时必须退回到临界区之外,重新申请锁定互斥量,不然就会发生竞争条件;
互斥量的存储区域:存在进程的地址空间中,供多个线程共享,是很方便高效的;
管程:需要语言支持,即语言自动识别管程,自动加入互斥操作,面临的问题与互斥量是一样的,缺点是很多语言包括c语言,压根就不支持;
ps:信号量比较低级,一方面麻烦,程序员极容易发生错误,另一方面无法支持分布式系统不共享内存的情况;管程也类似;
消息传递:消息传递不是采用上面的共享内存的方式,比如两个进程间传递消息,采用两个缓冲区或者说两个信箱,这样并没有互斥操作,也就不会产生竞争条件,也没有死锁发生,并且支持分布式系统,而且支持阻塞不用忙等待;阻塞后由os的调度程序,决定是否满足条件唤醒;要解决的问题就是如何提高消息传递的效率,在同一台PC上的时候,效率相比信号量必然是低一些的;
屏障:进程组的同步机制,当进程组中所有进程都就绪准备进入下一个阶段的时候,才允许进入下一个阶段;
【进程调度】:没有绝对的好与坏,与系统的环境和需求有关系;
批处理系统调度:常关心的指标:吞吐量、周转时间、CPU利用率;一些非常简单拙劣的方法:
1、非抢占式的先来先服务;
2、最短时间优先;(适用条件是预知进程的运行时间)
3、最短剩余时间优先(2的抢占式版本);(适用条件是预知进程的运行时间)
交互式系统调度:常关心的指标:响应时间、均衡性;ps:实际中是下面几种调度的结合,我觉得
1、轮转调度:即划分时间片,根据时间片来调度,是最广泛,最简单公平的调度算法;一般时间片设置在20~50ms比较合适;
2、优先级调度:优先级高的先执行;可以结合优先级调度和轮转调度,同一优先级的进程使用轮转调度,做好低优先级的进程的调整工作防止饥饿现象;
3、最短进程调度:;也就是前面的最短时间优先,进程的时间根据历史信息估计,使用学习率alpha更新;
4、保证调度:保证每个进程或者每个用户常用cpu的时间比率;
5、彩票调度:给进程发彩票,选择中彩票的进程运行,我感觉与优先级调度是一个道理,但是灵活与跳跃性更好;
6、公平分享调度:不只是关注进程本身,关注进程的用户,保证每个用户使用cpu的占比,我感觉与保证调度中保证用户相似;
实时系统调度:常关心的指标:或多或少必须满足截止时间;截止时间:硬实时和软实时,调度程序的任务就是满足截止时间的要求调度进程;
策略和机制:将调度机制和调度策略分离,即将调度机制写成算法,算法中的参数由进程输入,这样父进程可以很好地控制子进程的调度策略;
【线程调度】:
用户级线程调度:内核看不到,仍然与前面调度进程的时候一样;在某个进程中运行线程调度程序,选择某个线程,在该线程运行完之前,该进程中的其他线程无法运行;优点是线程调度的切换速度快,硬件支持下ns级别;缺点是缺乏一个时间中断,将运行时间过长的线程切换;还有一个优点就是用户空间线程的调度可以程序员定制化;
内核级线程调度:内核级线程在内核中有一个线程表,内核像对待进程一样调度;优点:能够时间中断,不会某个线程运行时间过长;缺点:两个不同进程的线程之间切换的时候,与进程的切换开销相似,比较慢我估计在ms级别;but,内核调度的时候可以优先选择同一个进程下的不同线程,这样线程切换的开销就比进程切换的开销小不少,因为不需要修改内存映像和高速缓存,只需要保存线程运行的状态信息;所以这是一种好的折中;
【进程切换为什么花时间】:进程切换,首先要存储当前进程的状态信息(PC、PSW、寄存器)到内核中的进程表项,在许多系统中内存映像(例如页表内的内存访问位)也必须要保存,然后需要运行调度程序,选好下一个进程后需要拷贝该进程的内存映像到MMU,然后拷贝其状态信息,然后开始运行;同时切换进程会使得高速缓存失效,所以会发生两次高速缓存到内存的读写操作,一次是原进程离开,高速缓存写入内存,一次是新进程加载,内存进入高速缓存;因此进程切换非常花时间;比如这个时间开销是1ms;
【解答一些疑问】:
1、函数的堆数据是放在进程的地址空间中的么?答:函数的堆数据确实是在进程的地址空间中,对于多线程的进程,每一个线程都有自己的堆栈空间,保存函数过程信息;
2、进程的地址空间中存放了哪些信息?答:全局变量、打开的文件、即将发生的报警、信号与信号处理程序、账户信息等;再就是包含了线程存储的 堆栈,备份信息(pc,psw,寄存器);
3、一些其他问题:哲学家就餐问题,对IO访问互斥访问竞争建模;读者写者问题,对数据库的访问建模;
【unix系统中进程的一些知识】:
Unix把进程分成两大类:
一类是系统进程,另一类是用户进程。系统进程执行操作系统程序,提供系统功能,工作于核心态。用户进程执行用户程序,在操作系统的管理和控制下执行,工作于用户态。进程在不同的状态下执行时拥有不同的权力。
在Unix系统中进程由三部分组成,分别是进程控制块、正文段和数据段。Unix系统中把进程控制块分成proc结构和user结构两部分,proc存放的是系统经常要查询和修改的信息,需要快速访问,因此常将其装入内存
【进程线程间通信的方式】:
原创:香蕉麦乐迪

相关文章推荐
- HTML控件事件一览表
- xampp httpd-vhosts.conf 配置
- Android瀑布流的实现
- Web前端概括
- superslide2插件
- linux下导入、导出mysql数据库命令
- 用SignalR实现的弹幕功能
- nginx lua 开发笔记
- linux 常用命令
- java中的匿名内部类
- 并发编程底层
- VC 宏定义使用
- LeetCode 3.5 Longest Palindromic Substring
- 正确使用Volatile关键字
- 地理信息检索
- dom4j读写xml
- 【ASP.NET】ASP.NET中gridview中点击某一行刷新后不会到顶部
- (13)处理静态资源(默认资源映射)【从零开始学Spring Boot】
- c++实现mysql数据库数据缓存
- xml绘制总结——shape,selector,layer-list