第八周 进程的切换和系统的一般执行过程
2016-04-13 21:40
246 查看
一.进程切换的关键代码switch_to分析
进程的调度时机与进程的切换:
操作系统中的进程调度算法是从运行队列中选择一个新进程,选择的过程中运用了不同的策略


进程调度的时机:
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule()
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度
进程的切换:
为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换
挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行
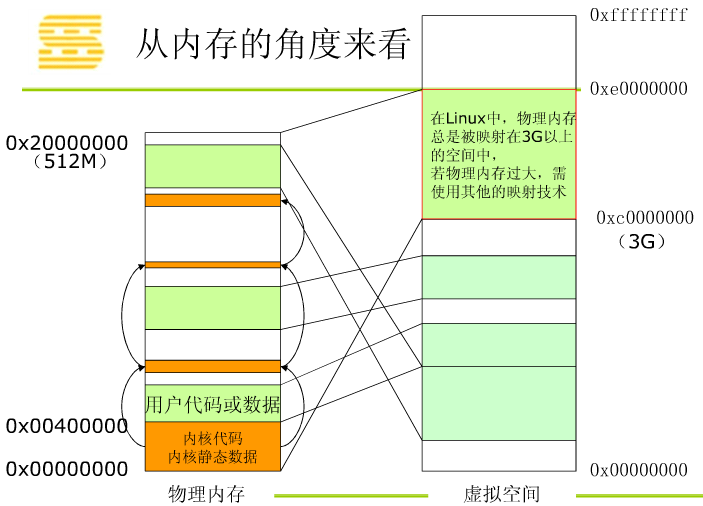
进程上下文包含了进程执行需要的所有信息
用户地址空间: 包括程序代码,数据,用户堆栈等
控制信息 :进程描述符,内核堆栈等
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换

二.Linux系统的一般执行过程
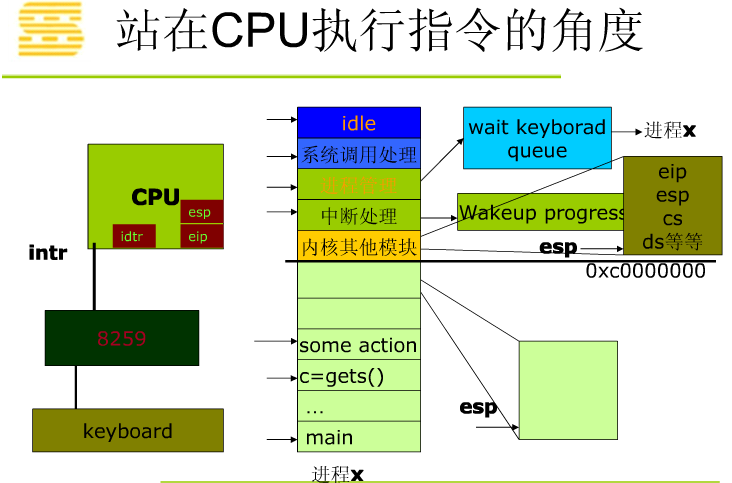
Linux系统的一般执行过程最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
正在运行的用户态进程X
发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
SAVE_ALL //保存现场
中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
restore_all//恢复现场
iret - pop cs:eip/ss:esp/eflags from kernel stack
继续运行用户态进程Y
几种特殊情况:
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
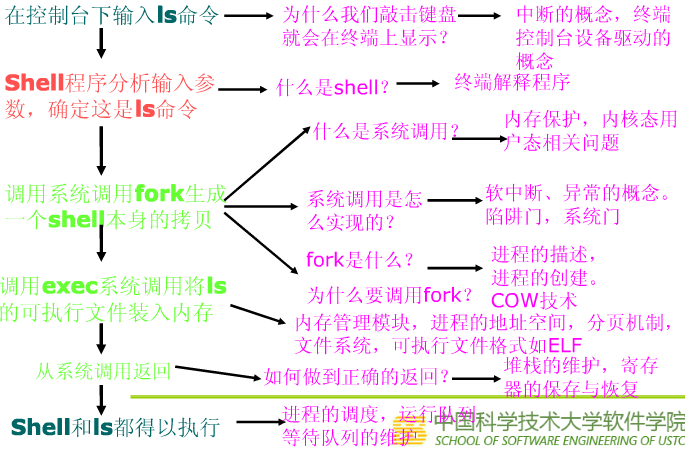
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
三.实验:使用gdb跟踪分析一个schedule()函数 ,验证对Linux系统进程调度与进程切换过程的理解
终端输入qemu –kernel linux-3.18.6/arch/x86/boot/bzImage –initrd rootfs.img –S –s
然后打开另一个终端输入
进行调试跟踪schedule的执行过程

进程调度时,首先进入schedule()函数,将一个task_struct结构体的指针tsk赋值为当前进程
然后调用sched_submit_work(tsk)
我们进入这个函数,查看一下做了什么工作
我们在执行到sched_submit_work时,输入si进入函数

可以看到这个函数时检测tsk->state是否为0 (runnable)若为运行态时则返回
tsk_is_pi_blocked(tsk),检测tsk的死锁检测器是否为空,若非空的话就return

然后检测是否需要刷新plug队列,用来避免死锁
sched_submit_work主要是来避免死锁
然后我们进入__schedule()函数

__schedule()是切换进程的真正代码,我们来分析一下具体的关键代码
1.创建一些局部变量
2.关闭内核抢占,初始化一部分变量
3.选择next进程
4.完成进程的调度
这段代码中context_switch(rq,prev,next)完成了从prev到next的进程上下文的切换。我们进入这个函数查看
我们看到在context_switch中使用switch_to(prev,next,prev)来切换进程。我们查看一下switch_to的代码
switch_to是一个宏定义,完成进程从prev到next的切换,首先保存flags,然后保存当前进程的ebp,然后把当前进程的esp保存到prev->thread.sp中,然后把标号1:的地址保存到prev->thread.ip中
然后把next->thread.ip压入堆栈。这里,如果之前B也被switch_to出去过,那么next->thread.ip里存的就是下面这个1f的标号,但如果next进程刚刚被创建,之前没有被switch_to出去过,那么next->thread.ip里存的将是ret_ftom_fork__switch_canqry应该是现代操作系统防止栈溢出攻击的金丝雀技术
jmp __switch_to使用regparm call, 参数不是压入堆栈,而是使用寄存器传值,来调用__switch_to
eax存放prev,edx存放next。这里为什么不用call __switch_to而用jmp,因为call会导致自动把下面这句话的地址(也就是1:)压栈,然后__switch_to()就必然只能ret到这里,而无法根据需要ret到ret_from_fork
当一个进程再次被调度时,会从1:开始执行,把ebp弹出,然后把flags弹出。
5.开启抢占
到此,进程的切换过程就完成了
进程的调度时机与进程的切换:
操作系统中的进程调度算法是从运行队列中选择一个新进程,选择的过程中运用了不同的策略
进程调度的时机:
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule()
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度
进程的切换:
为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换
挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行
进程上下文包含了进程执行需要的所有信息
用户地址空间: 包括程序代码,数据,用户堆栈等
控制信息 :进程描述符,内核堆栈等
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
context_switch(rq, prev, next);//进程上下文切换
switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
二.Linux系统的一般执行过程
Linux系统的一般执行过程最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
正在运行的用户态进程X
发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
SAVE_ALL //保存现场
中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
restore_all//恢复现场
iret - pop cs:eip/ss:esp/eflags from kernel stack
继续运行用户态进程Y
几种特殊情况:
通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
加载一个新的可执行程序后返回到用户态的情况,如execve;
三.实验:使用gdb跟踪分析一个schedule()函数 ,验证对Linux系统进程调度与进程切换过程的理解
终端输入qemu –kernel linux-3.18.6/arch/x86/boot/bzImage –initrd rootfs.img –S –s
然后打开另一个终端输入
gdb (gdb)file linux-3.18.6/vmlinux (gdb)target remote:1234 (gdb)b schedule (gdb)c
进行调试跟踪schedule的执行过程
进程调度时,首先进入schedule()函数,将一个task_struct结构体的指针tsk赋值为当前进程
然后调用sched_submit_work(tsk)
我们进入这个函数,查看一下做了什么工作
我们在执行到sched_submit_work时,输入si进入函数
可以看到这个函数时检测tsk->state是否为0 (runnable)若为运行态时则返回
tsk_is_pi_blocked(tsk),检测tsk的死锁检测器是否为空,若非空的话就return
然后检测是否需要刷新plug队列,用来避免死锁
sched_submit_work主要是来避免死锁
然后我们进入__schedule()函数
__schedule()是切换进程的真正代码,我们来分析一下具体的关键代码
1.创建一些局部变量
struct task_struct *prev, *next;//当前进程和一下个进程的进程结构体 unsigned long *switch_count;//进程切换次数 struct rq *rq;//就绪队列 int cpu;
2.关闭内核抢占,初始化一部分变量
need_resched: preempt_disable();//关闭内核抢占 cpu = smp_processor_id(); rq = cpu_rq(cpu);//与CPU相关的runqueue保存在rq中 rcu_note_context_switch(cpu); prev = rq->curr;//将runqueue当前的值赋给prev
3.选择next进程
next = pick_next_task(rq, prev);//挑选一个优先级最高的任务排进队列 clear_tsk_need_resched(prev);//清除prev的TIF_NEED_RESCHED标志。 clear_preempt_need_resched();
4.完成进程的调度
if (likely(prev != next)) {//如果prev和next是不同进程
rq->nr_switches++;//队列切换次数更新
rq->curr = next;
++*switch_count;//进程切换次数更新
context_switch(rq, prev, next); /* unlocks the rq *///进程上下文的切换
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else//如果是同一个进程不需要切换
raw_spin_unlock_irq(&rq->lock);这段代码中context_switch(rq,prev,next)完成了从prev到next的进程上下文的切换。我们进入这个函数查看
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;//初始化进程地址管理结构体mm和oldmm
prepare_task_switch(rq, prev, next);//完成进程切换的准备工作
mm = next->mm;
oldmm = prev->active_mm;
/*完成mm_struct的切换*/
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
switch_to(prev, next, prev);//进程切换的核心代码
barrier();
finish_task_switch(this_rq(), prev);
}我们看到在context_switch中使用switch_to(prev,next,prev)来切换进程。我们查看一下switch_to的代码
switch_to是一个宏定义,完成进程从prev到next的切换,首先保存flags,然后保存当前进程的ebp,然后把当前进程的esp保存到prev->thread.sp中,然后把标号1:的地址保存到prev->thread.ip中
然后把next->thread.ip压入堆栈。这里,如果之前B也被switch_to出去过,那么next->thread.ip里存的就是下面这个1f的标号,但如果next进程刚刚被创建,之前没有被switch_to出去过,那么next->thread.ip里存的将是ret_ftom_fork__switch_canqry应该是现代操作系统防止栈溢出攻击的金丝雀技术
jmp __switch_to使用regparm call, 参数不是压入堆栈,而是使用寄存器传值,来调用__switch_to
eax存放prev,edx存放next。这里为什么不用call __switch_to而用jmp,因为call会导致自动把下面这句话的地址(也就是1:)压栈,然后__switch_to()就必然只能ret到这里,而无法根据需要ret到ret_from_fork
当一个进程再次被调度时,会从1:开始执行,把ebp弹出,然后把flags弹出。
5.开启抢占
sched_preempt_enable_no_resched(); if (need_resched()) goto need_resched;
到此,进程的切换过程就完成了

相关文章推荐
- Linux内核设计与实现 第四章
- 指向结构体变量的指针引用结构体变量的成员
- zzulioj--10465--最长匹配子串(栈模拟)
- 第三次C++作业
- Android 5.0 Intercept HomeKey
- 离散数学 Resolution 消解算法
- 【c语言】用选择法对10个整数排序
- 招商银行信用卡中心(信息技术部)暑期实习笔试题
- Hibernate的一级和二级缓存
- 【c语言】输入一个4位数字,要求输出这4个数字字符,但每两个数字间空一个空格。如:1990->1 9 9 0
- 使用Sass优雅并高效的实现CSS中的垂直水平居中(附带Flex布局,CSS3+SASS完美版)
- LINUX+Vmware+SVN的配置和安装
- Yaml学习笔录
- 《Linux内核分析》第八周:进程的切换和系统的一般执行过程
- 西普实验吧-ctf-web-1
- 20135220谈愈敏Blog8_进程的切换和系统的一般执行过程
- 读《杀人之门》
- PHP_CodeSniffer的下载和使用
- 操作系统
- GDB的基本使用