Python如何进行cross validation training
2016-04-01 10:32
543 查看
以4-fold validation training为例
(1) 给定数据集data和标签集label
样本个数为
(2) 将给定的所有examples分为10组
每个fold个数为
(3) 将给定的所有examples分为10组
参考scikit-learn的3.1节:Cross-validation
给定的数据集如下:


所有样本的指标集为:
每个iFold(共4个)的训练集和validation set的index分别为:
iFold = 0 (训练集中包含6个examples,validation set 中包含3个examples)
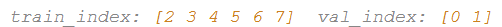
iFold = 1

iFold = 2
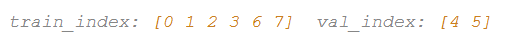
iFold = 3
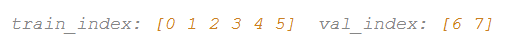
每个iFold的训练集和validation set分别为:
(1) 给定数据集data和标签集label
样本个数为
sampNum = len(data)
(2) 将给定的所有examples分为10组
每个fold个数为
foldNum = sampNum/10
(3) 将给定的所有examples分为10组
参考scikit-learn的3.1节:Cross-validation
1 import np 2 from sklearn import cross_validation 3 # dataset 4 5 data = np.array([[1,3],[2,4],[3.1,3],[4,5],[5.0,0.3],[4.1,3.1]]) 6 label = np.array([0,1,1,1,0,0]) 7 sampNum= len(data) 8 9 # 10-fold (9份为training,1份为validation) 10 kf = KFold(len(data), n_folds=4) 11 iFold = 0 12 for train_index, val_index in kf: 13 iFold = iFold+1 14 X_train, X_val, y_train, y_val = data[train_index], data[val_index], label[train_index], label[val_index] # 这里的X_train,y_train为第iFold个fold的训练集,X_val,y_val为validation set
给定的数据集如下:
所有样本的指标集为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
iFold = 0 (训练集中包含6个examples,validation set 中包含3个examples)
iFold = 1
iFold = 2
iFold = 3
每个iFold的训练集和validation set分别为:
X_train, X_val, y_train, y_val = data[train_index], data[val_index], label[train_index], label[val_index]

相关文章推荐
- Python常用函数
- Python如何读取指定文件夹下的所有图像
- python相关的工具
- 开始学习Python
- python pexpect
- Python脚本执行MySQL语句时停住
- [置顶] win10安装Python出现问题解决方法
- numpy.ndarray.flat/flatten 与 Spark 下的 flatMap
- Day3、Python
- python学习笔记(session)
- Python函数的各种参数(含星号参数)
- Python 基础 —— re:正则表达
- Python中遇到"UnicodeDecodeError: ‘gbk’ codec can’t decode bytes in position 2-3: illegal multibyte sequ
- python基于隐马尔可夫模型实现中文拼音输入
- Python 2.x vs Python 3.x(四)—— TypeError: unhashable type
- python3.5 + django1.9.1+mysql
- python中的条件语句,分支语句以及逻辑运算符和比较运算符
- 学python过程中遇到的一些问题及解决方法
- python爬虫(爬游民星空图片)_beautifulsoup爬虫模版
- python基于隐马尔可夫模型实现中文拼音输入