CUDA范例精解通用GPU架构-(2)其实写个矩阵相乘并不是那么难
2016-03-21 18:13
671 查看
http://www.cnblogs.com/yusenwu/p/5300956.html
程序代码及图解析: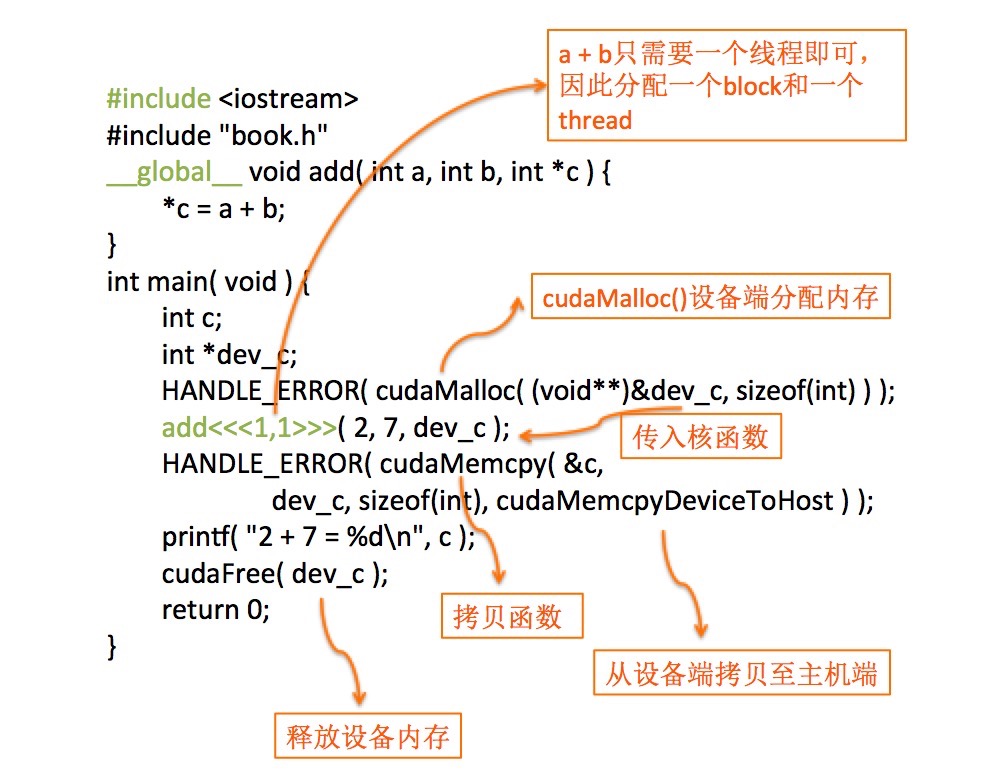
函数原型:__host__cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)
作用:在设备端和主机端拷贝数据。
参数:dst 目的地址 src 源地址 count 拷贝字节大小kind 传输的类型
返回值:
cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidDevicePointer, cudaErrorInvalidMemcpyDirection
说明:
从源地址拷贝设定数量的字节数至目的地址,kind类型有四种,分别为:
cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice,
通过指定方向进行拷贝。存储器区域不可重叠。如若产生未定义拷贝方向的行为,dst和src将不匹配。
正文
前面的图是最简单的一个CUDA程序,它引出了Grid Block Thread概念。很多threads组成1维,2维or3维的thread block. 为了标记thread在block中的位置(index),我们可以用上面讲的threadIdx。threadIdx是一个维度<=3的vector。还可以用thread index(一个标量)表示这个位置。thread的index与threadIdx的关系:
| Thread index | |
| 1 | T |
| 2 | T.x + T.y * Dx |
| 3 | T.x+T.y*Dx+z*Dx*Dy |
因为一个block内的所有threads会在同一处理器内核上共享内存资源,所以block内有多少threads是有限制的。目前GPU限制每个 block最多有1024个threads。但是一个kernel可以在多个相同shape的block上执行,效果等效于在一个有N*#thread per block个thread的block上执行。
Block又被组织成grid。同样,grid中block也可以被组织成1维,2维or3维。一个grid中的block数量由系统中处理器个数或待处理的数据量决定。(来自这里)
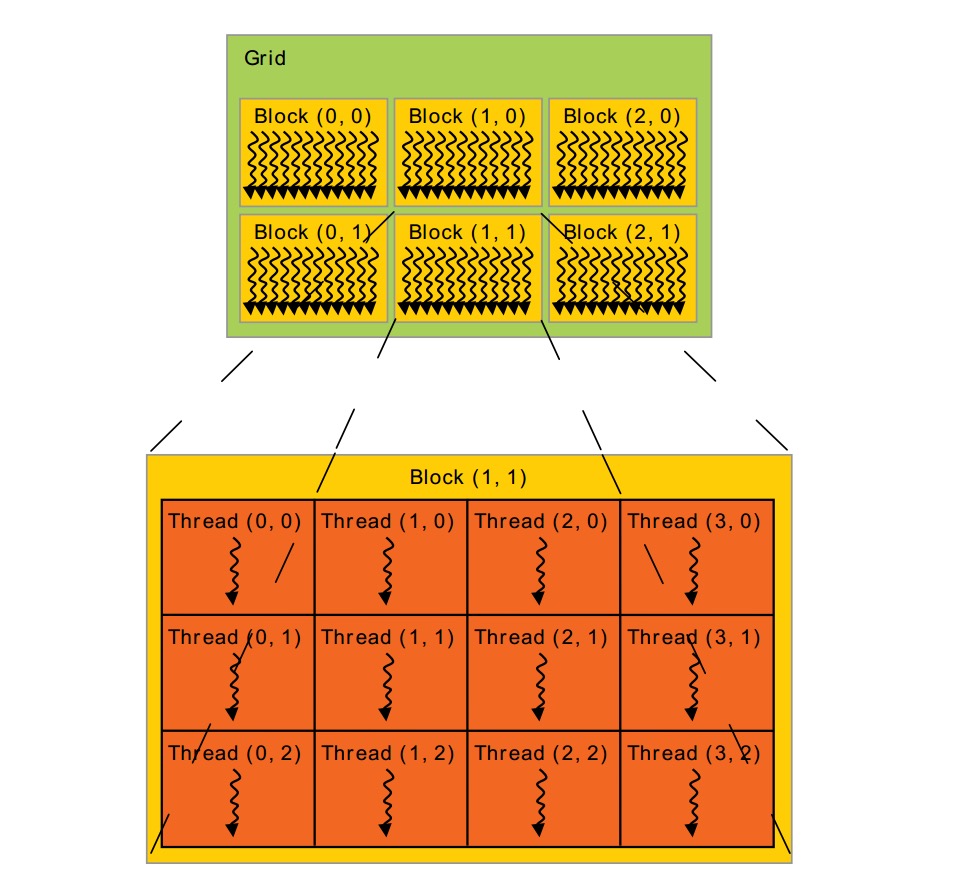
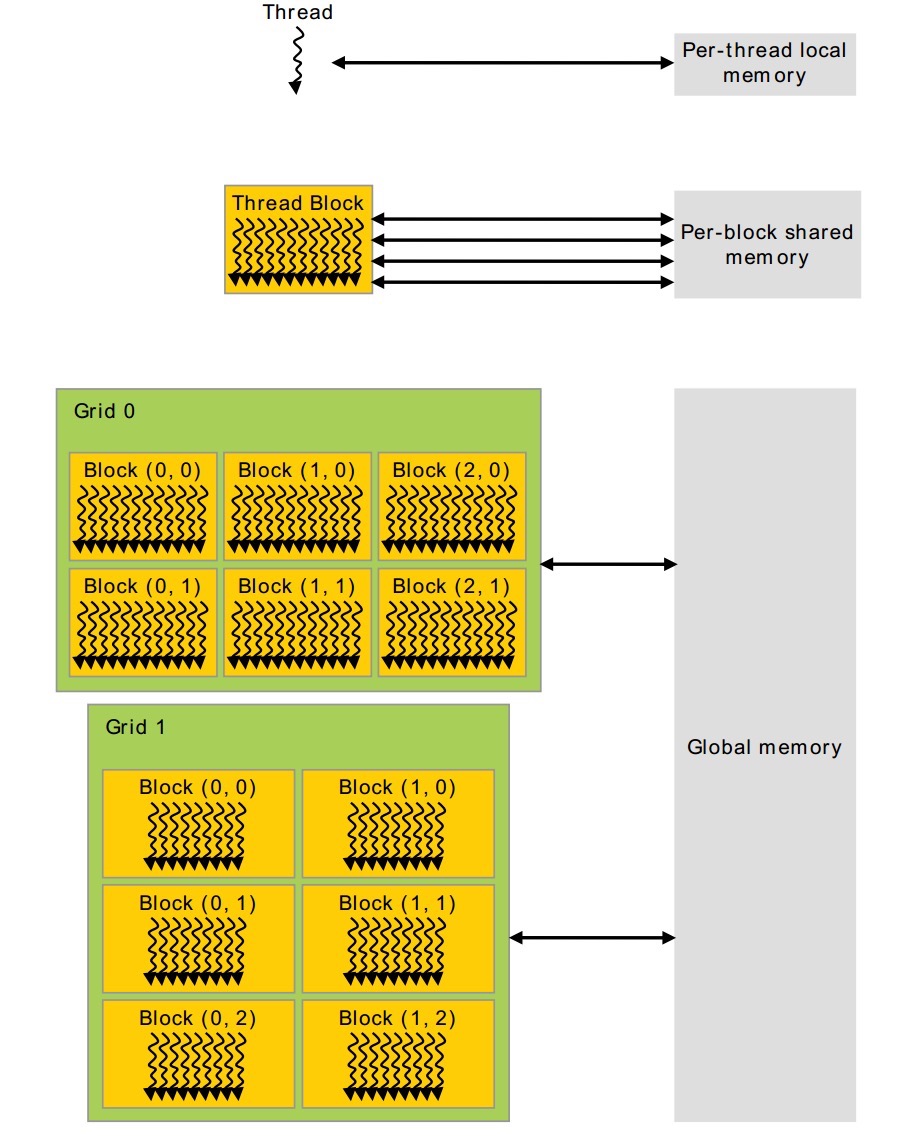
下图中描述了Thread、Block、Grid内存的访问机制。
每个thread有自己的local-memory。每一个block有自己的共享内存、grid和grid之间可以同时访问全局内存。这里要注意:block和block之间不能访问同一个共享内存,他们只能访问自己的共享内存。
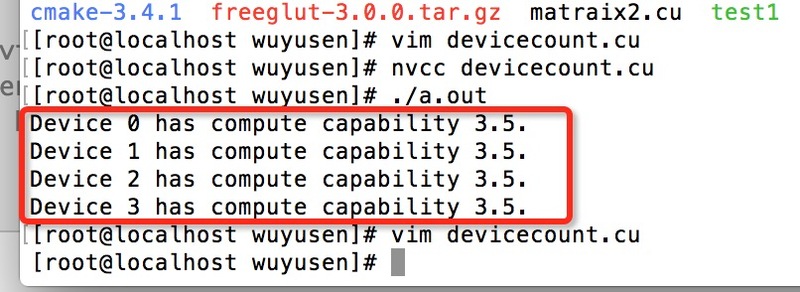
cudaGetDeviceCount( &count )查询服务器的CUDA信息.
代码:
+
View Code
小结
第一个执行时间: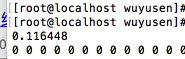
share memory执行时间:

注意,核函数内不是所有线程一起进去执行,这个概念模糊不清。我们需要理解成,所有的线程并行执行核函数里面的程序,即每一个线程都会执行该函数,所有线程执行完,即结束。这个简单的概念,我一开始想了很久。

相关文章推荐
- 使用Java开发高性能网站需要关注的那些事儿
- 大型网站技术架构
- 大型网站技术架构
- 大型网站系统架构的演化
- 3.5.Android控件架构与自定义控件详解之自定义View(一)
- 大型网站开发技术书籍汇总
- 3.4.Android控件架构与自定义控件详解之ViewGroup的测量与绘制
- 大型网站技术架构学习笔记
- PHP编写学校网站上新生注册登陆程序的实例分享
- iOS应用架构谈 本地持久化方案及动态部署
- 3.3.Android控件架构与自定义控件详解之View的绘制
- 记录网站诞生过程-使用hexo+github pages
- 跟我快速理解Dubbo:-2 架构设计详解
- 架构设计:生产者/消费者模式 第6页:环形缓冲区的实现
- 架构设计:生产者/消费者模式 第5页:环形缓冲区
- 架构设计--消息队列
- 架构设计:生产者/消费者模式 第4页:注意事项
- 架构设计:生产者/消费者模式 第3页:队列缓冲区
- 架构设计:生产者/消费者模式 第2页:如何确定数据单元
- 【搜索引擎基础知识3】搜索引擎相关开源项目及网站