数据挖掘面试题150解析(一)
2016-03-20 22:55
239 查看
等频划分,等宽划分
离散化方法的研究,已经提出了等频划分、等宽划分和适应离散法等。
1、等宽划分:在最小值和最大值之间平均划分成N个区间(N用户给定),假定A和B分别是最大值和最小值,则每个区间的宽度为W=(B-A)/N,区间的边界线分别为A,A+W,A+2W,......,A+(N-1)W,A+NW=B
2、等频划分:把整个区域分为N个区间,每个区间有大约相同数目的例子
如:N=10,则每个区间中有大约10%的例子
这两种离散化方法都与分类信息无关
当属性值分布不均匀时,不能很好表示数据分布
要声明一个静态变量或定义一个静态方法,就要在变量或方法的声明中加上修饰符static.
类中的常量应该声明为final static.
使'类名.方法名'调用静态方法
使'类名.变量名'调用静态变量。
静态变量和静态方法既可以在类的实例方法中使用,又可以在类的静态方法中使用。但是实例变量和实例方法就只能在实例方法中使用。
当方法不依赖于任何具体的实例,就声明为静态方法。
截断均值:指定0和100之间的百分数p,丢弃高端和低端(p/2)%的数据,然后用常规的方法计算均值,所得的结果就是截断均值.
按照公式,(p/2)%=20%,8*20%=1.6约等于2,那么应该截掉前两个数和后两个数,剩下{3,4},所以截断均值为(3+4)/2=3.5。
傅立叶变换,表示能将满足一定条件的某个函数表示成三角函数(正弦和/或余弦函数)或者它们的积分的线性组合。
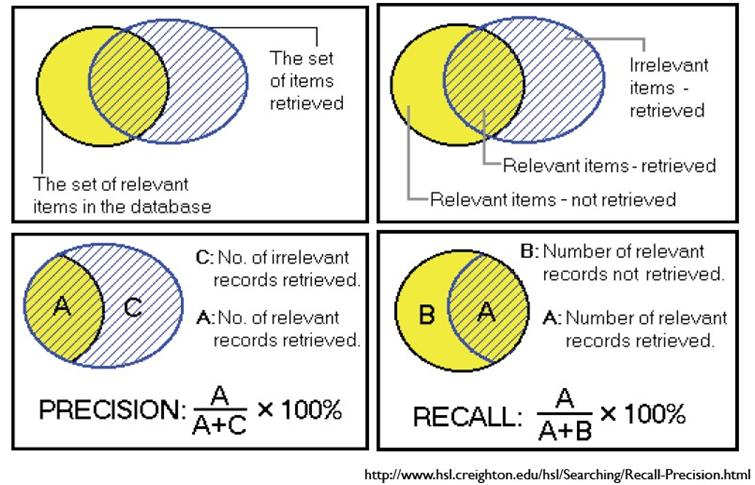
通俗的讲,Precision 就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张图介绍True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
ROC曲线和PR曲线
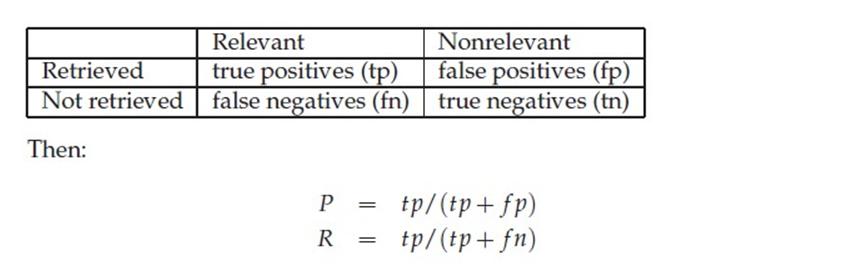
True Positives,TP:预测为正样本,实际也为正样本的特征数
False Positives,FP:预测为正样本,实际为负样本的特征数(错预测为正样本了,所以叫False)
True Negatives,TN:预测为负样本,实际也为负样本的特征数
False Negatives,FN:预测为负样本,实际为正样本的特征数(错预测为负样本了,所以叫False)
接着往下做做小学的计算题:
TP+FP+FN+FN:特征总数(样本总数)
TP+FN:实际正样本数
FP+TN:实际负样本数
TP+FP:预测结果为正样本的总数
TN+FN:预测结果为负样本的总数
有些绕,为做区分,可以这样记:相同的后缀(P或N)之和表示__预测__正样本/负样本总数,前缀加入T和F;实际样本总数的4个字母完全不同,含TP(正正得正)表示实际正样本,含FP(负正得负)表示实际负样本。
True Positive Rate(TPR)和False Positive Rate(FPR)分别构成ROC曲线的y轴和x轴。
TPR=TP/(TP+FN),实际正样本中被预测正确的概率
FPR=FP/(FP+TN),实际负样本中被错误预测为正样本的概率
实际学习算法中,预测率100%的话,TPR=100%和FPR=0,所以TPR越大而FPR越小越好。仅用其中一个作为衡量指标可以吗?考虑这么一种情况,一幅图片假如600x480个像素,其中目标(正样本)仅有100个像素,假如有某种算法,预测的目标为包含所有像素600x480,这种情况下TPR的结果是TPR=100%,但FPR却也接近于100%。明显,TPR满足要求但结果却不是我们想要的,因为FPR太高了。
Precision和Recall(有人中文翻译成召回率)则分别构成了PR曲线的y轴和x轴。
Precision=TP/(TP+FP),预测结果为有多少正样本是预测正确了的
Recall=TP/(TP+FN),召回率很有意思,这个其实就=TPR,相对于Precision只不过参考样本从预测总正样本数结果变成了实际总正样本数。
同理,Precision和Recall同时考虑才能确定算法好坏。好了,原来一切尽在尽在下图中,

最小-最大规范化对原始数据进行线性变换。假定minA和maxA分别为属性A的最小值和最大值。最小-最大规范化通过计算

将A的值v映射到区间[new_minA, new_maxA]中的v'。
最小-最大规范化保持原始数据值之间的联系。如果今后的输入落在A的原始数据值域之
外,该方法将面临“越界”错误。
例2-2 最小-最大规范化。假定属性income的最小与最大值分别为12 000美元和98 000美
元。我们想把income映射到区间[0.0, 0.1]。根据最小最大规范化,income值73 600美元将变换
为:

分箱法
shen_960124 2014-01-06 11:17
通过考察“邻居”(周围的值)来平滑存储数据的值,用“箱的深度”表示不同的箱里有相同个数的数据,用“箱的宽度”来表示每个箱值的取值区间为常数。由于分箱方法考虑相邻的值,因此是一种局部平滑方法。
按照取值的不同可划分为按箱平均值平滑、按箱中值平滑以及按箱边界值平滑。
举例:
假设有8、24、15、41、7、10、18、67、25等9个数,分为3箱。
箱1: 8、24、15
箱2: 41、7、10
箱3: 18、67、25
分别用三种不同的分箱法求出平滑存储数据的值:
按箱平均值求得平滑数据值:箱1: 16,16,16
按箱中值求得平滑数据值:箱2: 7,7,7
按箱边界值求得平滑数据值: 箱3:18,18,18
极差、四分位数和四分位数极差
开始,让我们先学习作为数据散布度量的极差、分位数、四分位数、百分位数和四分位数极差。
设x1,x2,…,xN是某数值属性X上的观测的集合。该集合的极差(range)是最大值(max())与最小值(min())之差。
假设属性X的数据以数值递增序排列。想象我们可以挑选某些数据点,以便把数据分布划分成大小相等的连贯集,如图2.2所示。这些数据点称做分位数。分位数(quantile)是取自数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合。(我们说“基本上”,因为可能不存在把数据划分成恰好大小相等的诸子集的X的数据值。为简单起见,我们将称它们相等。)给定数据分布的第k个q-分位数是值x,使得小于x的数据值最多为k/q,而大于x的数据值最多为(q-k)/q,其中k是整数,使得0<k<q。我们有q-1个q-分位数。
2-分位数是一个数据点,它把数据分布划分成高低两半。2-分位数对应于中位数。4-分位数是3个数据点,它们把数据分布划分成4个相等的部分,使得每部分表示数据分布的四分之一。通常称它们为四分位数(quartile)。100-分位数通常称做百分位数(percentile),它们把数据分布划分成100个大小相等的连贯集。中位数、四分位数和百分位数是使用最广泛的分位数。48
四分位数给出分布的中心、散布和形状的某种指示。第1个四分位数记作Q1,是第25个百分位数,它砍掉数据的最低的25%。第3个四分位数记作Q3,是第75个百分位数,它砍掉数据的最低的75%(或最高的25%)。第2个四分位数是第50个百分位数,作为中位数,它给出数据分布的中心。
第1个和第3个四分位数之间的距离是散布的一种简单度量,它给出被数据的中间一半所覆盖的范围。该距离称为四分位数极差(IQR),定义为
例2.10 四分位数极差。四分位数是3个值,把排序的数据集划分成4个相等的部分。例2.6的数据包含12个观测,已经按递增序排序。这样,该数据集的四分位数分别是该有序表的第3、第6和第9个值。因此,Q1=47000美元,而Q3=63000美元。于是,四分位数极差为IQR=63000-47000=16000美元。(注意,第6个值是中位数52000美元,尽管这个数据集因为数据值的个数为偶数有两个中位数。)
数据粒度是指数据仓库中数据的细化和综合程度。一般情况下,根据数据粒度划分标准,可以将数据仓库中的数据划分为:详细数据、轻度总结、高度总结三级。在确定数据粒度时应注意一条原则:细化程度越高,粒度越小;细化程度越低,粒度越大。
OLAP特点:
1. 假定性:需要初始的假设来给出导航数据分析的方向,最终用分析的结果来验证初始的假设。
2. 快速性:用户对OLAP的快速反映能力有很高的要求。
3. 可分析性:能处理与应用有关的任何逻辑分析和统计分析。用户可以在OLAP平台上进行分析,也可以连接到其他外部分析工具上。
4. 多维性:是OLAP的关键属性,系统提供对数据分析的多维视图和分析,如对层次维和多重层次维完全支持。
5. 信息性:系统能及时获取信息,并能管理大容量的信息。
频繁项:在多个集合中,频繁出现的元素/项,就是频繁项
频繁项集:有一系列集合,这些集合有些相同的元素,集合中同时出现频率高的元素形成一个子集,满足一定阈值条件,就是频繁项集。
极大频繁项集:元素个数最多的频繁项集合,即其任何超集都是非频繁项集。
k项集:k项元素组成的一个集合
相似性分析,研究的对象是集合之间的相似性关系。而频繁项集分析,研究的集合间重复性高的元素子集。
频繁项集的应用:真实超市购物篮的分析,文档或网页的关联程序分析,文档的抄袭分析,生物标志物(疾病与某人生物生理信息的关系)
1)支持度: 包含频繁项集F的集合的数目
2)可信度:频繁项F与某项j的并集 (即F U {j})的支持度 与 频繁项集F的支持度的比值,
3)兴趣度:F U {j} 可信度 与 包含{j}的集合比率之间的差值。若兴趣度很高,则 频繁项集F会促进 j 的存在, 若兴趣度为负值,且频繁项集会抑制 j 的存在;若兴趣度为0,则频繁项集对 j 无太大影响。
频繁项集 与 某项 j 的关系就是 关联规则。
离散化方法的研究,已经提出了等频划分、等宽划分和适应离散法等。
1、等宽划分:在最小值和最大值之间平均划分成N个区间(N用户给定),假定A和B分别是最大值和最小值,则每个区间的宽度为W=(B-A)/N,区间的边界线分别为A,A+W,A+2W,......,A+(N-1)W,A+NW=B
2、等频划分:把整个区域分为N个区间,每个区间有大约相同数目的例子
如:N=10,则每个区间中有大约10%的例子
这两种离散化方法都与分类信息无关
当属性值分布不均匀时,不能很好表示数据分布
要声明一个静态变量或定义一个静态方法,就要在变量或方法的声明中加上修饰符static.
类中的常量应该声明为final static.
使'类名.方法名'调用静态方法
使'类名.变量名'调用静态变量。
静态变量和静态方法既可以在类的实例方法中使用,又可以在类的静态方法中使用。但是实例变量和实例方法就只能在实例方法中使用。
当方法不依赖于任何具体的实例,就声明为静态方法。
截断均值:指定0和100之间的百分数p,丢弃高端和低端(p/2)%的数据,然后用常规的方法计算均值,所得的结果就是截断均值.
按照公式,(p/2)%=20%,8*20%=1.6约等于2,那么应该截掉前两个数和后两个数,剩下{3,4},所以截断均值为(3+4)/2=3.5。
傅立叶变换,表示能将满足一定条件的某个函数表示成三角函数(正弦和/或余弦函数)或者它们的积分的线性组合。
查准与召回(Precision & Recall)
召回率和准确率是数据挖掘中预测、互联网中的搜索引擎等经常涉及的两个概念和指标。
召回率:Recall,又称“查全率”——还是查全率好记,也更能体现其实质意义。
准确率:Precision,又称“精度”、“正确率”。
通俗的讲,Precision 就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张图介绍True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
ROC曲线和PR曲线
基本概念
True Positives,TP:预测为正样本,实际也为正样本的特征数False Positives,FP:预测为正样本,实际为负样本的特征数(错预测为正样本了,所以叫False)
True Negatives,TN:预测为负样本,实际也为负样本的特征数
False Negatives,FN:预测为负样本,实际为正样本的特征数(错预测为负样本了,所以叫False)
接着往下做做小学的计算题:
TP+FP+FN+FN:特征总数(样本总数)
TP+FN:实际正样本数
FP+TN:实际负样本数
TP+FP:预测结果为正样本的总数
TN+FN:预测结果为负样本的总数
有些绕,为做区分,可以这样记:相同的后缀(P或N)之和表示__预测__正样本/负样本总数,前缀加入T和F;实际样本总数的4个字母完全不同,含TP(正正得正)表示实际正样本,含FP(负正得负)表示实际负样本。
ROC曲线和PR曲线
True Positive Rate(TPR)和False Positive Rate(FPR)分别构成ROC曲线的y轴和x轴。TPR=TP/(TP+FN),实际正样本中被预测正确的概率
FPR=FP/(FP+TN),实际负样本中被错误预测为正样本的概率
实际学习算法中,预测率100%的话,TPR=100%和FPR=0,所以TPR越大而FPR越小越好。仅用其中一个作为衡量指标可以吗?考虑这么一种情况,一幅图片假如600x480个像素,其中目标(正样本)仅有100个像素,假如有某种算法,预测的目标为包含所有像素600x480,这种情况下TPR的结果是TPR=100%,但FPR却也接近于100%。明显,TPR满足要求但结果却不是我们想要的,因为FPR太高了。
Precision和Recall(有人中文翻译成召回率)则分别构成了PR曲线的y轴和x轴。
Precision=TP/(TP+FP),预测结果为有多少正样本是预测正确了的
Recall=TP/(TP+FN),召回率很有意思,这个其实就=TPR,相对于Precision只不过参考样本从预测总正样本数结果变成了实际总正样本数。
同理,Precision和Recall同时考虑才能确定算法好坏。好了,原来一切尽在尽在下图中,
数据规范化
最小-最大规范化对原始数据进行线性变换。假定minA和maxA分别为属性A的最小值和最大值。最小-最大规范化通过计算将A的值v映射到区间[new_minA, new_maxA]中的v'。
最小-最大规范化保持原始数据值之间的联系。如果今后的输入落在A的原始数据值域之
外,该方法将面临“越界”错误。
例2-2 最小-最大规范化。假定属性income的最小与最大值分别为12 000美元和98 000美
元。我们想把income映射到区间[0.0, 0.1]。根据最小最大规范化,income值73 600美元将变换
为:
分箱法
shen_960124 2014-01-06 11:17
通过考察“邻居”(周围的值)来平滑存储数据的值,用“箱的深度”表示不同的箱里有相同个数的数据,用“箱的宽度”来表示每个箱值的取值区间为常数。由于分箱方法考虑相邻的值,因此是一种局部平滑方法。
按照取值的不同可划分为按箱平均值平滑、按箱中值平滑以及按箱边界值平滑。
举例:
假设有8、24、15、41、7、10、18、67、25等9个数,分为3箱。
箱1: 8、24、15
箱2: 41、7、10
箱3: 18、67、25
分别用三种不同的分箱法求出平滑存储数据的值:
按箱平均值求得平滑数据值:箱1: 16,16,16
按箱中值求得平滑数据值:箱2: 7,7,7
按箱边界值求得平滑数据值: 箱3:18,18,18
极差、四分位数和四分位数极差
开始,让我们先学习作为数据散布度量的极差、分位数、四分位数、百分位数和四分位数极差。
设x1,x2,…,xN是某数值属性X上的观测的集合。该集合的极差(range)是最大值(max())与最小值(min())之差。
 |
| 图2.2 某属性X的数据分布图。这里绘制的分位数是四分位数。 3个四分位数把分布划分成4个相等的部分。第2个四分位数对应于中位数 |
2-分位数是一个数据点,它把数据分布划分成高低两半。2-分位数对应于中位数。4-分位数是3个数据点,它们把数据分布划分成4个相等的部分,使得每部分表示数据分布的四分之一。通常称它们为四分位数(quartile)。100-分位数通常称做百分位数(percentile),它们把数据分布划分成100个大小相等的连贯集。中位数、四分位数和百分位数是使用最广泛的分位数。48
四分位数给出分布的中心、散布和形状的某种指示。第1个四分位数记作Q1,是第25个百分位数,它砍掉数据的最低的25%。第3个四分位数记作Q3,是第75个百分位数,它砍掉数据的最低的75%(或最高的25%)。第2个四分位数是第50个百分位数,作为中位数,它给出数据分布的中心。
第1个和第3个四分位数之间的距离是散布的一种简单度量,它给出被数据的中间一半所覆盖的范围。该距离称为四分位数极差(IQR),定义为
 |
数据粒度是指数据仓库中数据的细化和综合程度。一般情况下,根据数据粒度划分标准,可以将数据仓库中的数据划分为:详细数据、轻度总结、高度总结三级。在确定数据粒度时应注意一条原则:细化程度越高,粒度越小;细化程度越低,粒度越大。
OLAP特点:
1. 假定性:需要初始的假设来给出导航数据分析的方向,最终用分析的结果来验证初始的假设。
2. 快速性:用户对OLAP的快速反映能力有很高的要求。
3. 可分析性:能处理与应用有关的任何逻辑分析和统计分析。用户可以在OLAP平台上进行分析,也可以连接到其他外部分析工具上。
4. 多维性:是OLAP的关键属性,系统提供对数据分析的多维视图和分析,如对层次维和多重层次维完全支持。
5. 信息性:系统能及时获取信息,并能管理大容量的信息。
1. 什么是频繁项?什么是频繁项集?与相似性分析有什么差别? 有什么应用?
频繁项:在多个集合中,频繁出现的元素/项,就是频繁项频繁项集:有一系列集合,这些集合有些相同的元素,集合中同时出现频率高的元素形成一个子集,满足一定阈值条件,就是频繁项集。
极大频繁项集:元素个数最多的频繁项集合,即其任何超集都是非频繁项集。
k项集:k项元素组成的一个集合
相似性分析,研究的对象是集合之间的相似性关系。而频繁项集分析,研究的集合间重复性高的元素子集。
频繁项集的应用:真实超市购物篮的分析,文档或网页的关联程序分析,文档的抄袭分析,生物标志物(疾病与某人生物生理信息的关系)
2. 频繁项集分析有哪些指标?有什么意义?
1)支持度: 包含频繁项集F的集合的数目2)可信度:频繁项F与某项j的并集 (即F U {j})的支持度 与 频繁项集F的支持度的比值,
3)兴趣度:F U {j} 可信度 与 包含{j}的集合比率之间的差值。若兴趣度很高,则 频繁项集F会促进 j 的存在, 若兴趣度为负值,且频繁项集会抑制 j 的存在;若兴趣度为0,则频繁项集对 j 无太大影响。
频繁项集 与 某项 j 的关系就是 关联规则。

相关文章推荐
- 数据规范化常用方法
- Android等宽字体
- 聚类算法初探(二)预备知识
- 数据规范化(归一化)方法
- 方差、均值、中值matlab的求法
- a标签里面包裹img标签,两者要完全登高等宽
- Web前端面试题目及答案汇总
- 程序员的自我修养——静态链接
- 3年工作经验程序员应有的技能
- 面试大总结:Java搞定面试中的链表题目总结
- 面试常见问题:java中wait()和sleep()方法的区别
- 面试大总结之二:Java搞定面试中的二叉树题目
- Servlet生命周期与工作原理
- 安卓程序员个人角度浅析创业型公司败因
- SQL 常见面试题
- ajax的经典面试题以及答案
- 程序员对产品的思考暨项目总结:一品茶香
- List、Set、Map相关Q&A
- 剑指offer面试题之调整数组顺序奇数在偶数之前
- 面试锦集