SVD与PCA,奇异值分解与主成分分析的比较
2016-03-19 09:42
323 查看
一般来说,想要获得低维的子空间,最简单的是对原始的高维空间进行线性变换(当然了,非线性也是可以的,如加入核函数,比较著名的就是KPCA)。SVD和PCA呢,都实现了降维与重构,但是呢,思路不太一样,老师课上提了一次,以前看的迷迷糊糊的,这次下定决心,怎么都要搞清楚这两个概念。
SVD(singular value decomposition),线性代数里也叫作奇异值分解,可以用来计算矩阵的特征值(奇异值)和特征向量(我知道表达不准确,但我也不想知道正确的说法)。
SVD大多数情况下用来提取一个矩阵的主特征值,可以用于图像的压缩和去噪。举个例子,将一个纳木错大牦牛图像奇异值分解,

原图像共有1936个奇异值,这里选用100个奇异值重建:

奇异值分解的公式为
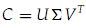
矩阵sigma中的最大的特征值所对应的U和V中的列向量和行向量,也就包含了图像中最多的信息。而且这种信息应该是低频的信息,特征值越大,表明原矩阵中的列向量的在该方向上的投影长度越大,也就是相关性越大,通过小的特征值重构出来的成分往往是高频噪声,因为在这些方向上,原矩阵中各个向量的相关性很小。
为什么说这些,其实我就想说,SVD也是一种实用的降维手段。下面说说是具体怎么降维的,降得是什么维?
因为正常我们会把每一个样本排成一个列向量,原始的矩阵C(m*n)的行数指的样本的维数m,列数就是样本的个数n,,现实生活中m<<n,因此rank(C)<=m。一个m维的向量,使用m个基向量就可以将其完备的表示出来,SVD就是寻找这些基向量。我们进行奇异值分解后,注意U的列向量和V的行向量都是单位向量,这不是明摆着的基向量么。将U中的列向量看做基,这些基地原矩阵C的列向量的基底,并且对于C中所有的列向量来说,这些矩阵在基向量u1上的投影长度最长,也就是说相关度最高,因为u1向量对应的sigma值最大,因此可以看做具体请看下图。

看完上面的图,有没有疑问,有就对了,我也是刚想到的一个问题,就拿c1向量来说,把他span成基向量的表达方式时,每个基向量前面的系数不仅有sigma,还有v1(1)等系数,经过这些系数的加权之后,那u1这个主向量还能保证吗?
答:可以保证,给大家一个思路,v*向量是单位向量,剩下来的大家应该知道了吧。
PCA(Principal Component Analysis)主成分分析最常用的一种降维方法,出发点是对于正交属性空间中的样本点,如何使用一个超平面对所有的样本进行恰当的表达。PCA在CSDN上已经被讲了n次了,有就不详细讲了,就理一理思路,大家感兴趣可以搜其他大牛的博客看看。一般来说,有两个出发点,1)样本点到这个超平面的距离足够近(重构性,最大程度的代表样本点),2)样本点在这个超平面上的投影尽可能分开(可分性,样本点在降维空间内可以区分)下面使用第二个指导思想简单的推导一下

利用PCA进行降维的过程中,我们只需要按照特征值的大小顺序,将原来的样本挨个往特征向量投影即可,至于选几个向量,一般来说需要调参。
Andrew ng教程中又提及了白化(whiten)的概念,目的就是为了把特征向量的特征值变成1,这样就消除了主方向的影响,具体可以看 http://ufldl.stanford.edu/wiki/index.php/Whitening。
参考
《机器学习》周志华
《The Matrix Cook book》 version:November 15,2012(强烈推荐的手头工具书,涉及矩阵的求导之类的直接套公式就行)
SVD(singular value decomposition),线性代数里也叫作奇异值分解,可以用来计算矩阵的特征值(奇异值)和特征向量(我知道表达不准确,但我也不想知道正确的说法)。
SVD大多数情况下用来提取一个矩阵的主特征值,可以用于图像的压缩和去噪。举个例子,将一个纳木错大牦牛图像奇异值分解,
Im=imread('niu.jpg');
figure(1);
Im=rgb2gray(Im);
imshow(Im,[]);
set(gca,'position',[0 0 1 1])
[m n]=size(Im);
Im=double(Im);
r=rank(Im);
[s v d]=svd(Im);
Im2=s(:,:)*v(:,1:100)*d(:,1:100)';
figure(2);
imshow(mat2gray(Im2));
imwrite(mat2gray(Im2),'1.jpg')
set(gca,'position',[0 0 1 1])原图:原图像共有1936个奇异值,这里选用100个奇异值重建:
奇异值分解的公式为
矩阵sigma中的最大的特征值所对应的U和V中的列向量和行向量,也就包含了图像中最多的信息。而且这种信息应该是低频的信息,特征值越大,表明原矩阵中的列向量的在该方向上的投影长度越大,也就是相关性越大,通过小的特征值重构出来的成分往往是高频噪声,因为在这些方向上,原矩阵中各个向量的相关性很小。
为什么说这些,其实我就想说,SVD也是一种实用的降维手段。下面说说是具体怎么降维的,降得是什么维?
因为正常我们会把每一个样本排成一个列向量,原始的矩阵C(m*n)的行数指的样本的维数m,列数就是样本的个数n,,现实生活中m<<n,因此rank(C)<=m。一个m维的向量,使用m个基向量就可以将其完备的表示出来,SVD就是寻找这些基向量。我们进行奇异值分解后,注意U的列向量和V的行向量都是单位向量,这不是明摆着的基向量么。将U中的列向量看做基,这些基地原矩阵C的列向量的基底,并且对于C中所有的列向量来说,这些矩阵在基向量u1上的投影长度最长,也就是说相关度最高,因为u1向量对应的sigma值最大,因此可以看做具体请看下图。
看完上面的图,有没有疑问,有就对了,我也是刚想到的一个问题,就拿c1向量来说,把他span成基向量的表达方式时,每个基向量前面的系数不仅有sigma,还有v1(1)等系数,经过这些系数的加权之后,那u1这个主向量还能保证吗?
答:可以保证,给大家一个思路,v*向量是单位向量,剩下来的大家应该知道了吧。
PCA(Principal Component Analysis)主成分分析最常用的一种降维方法,出发点是对于正交属性空间中的样本点,如何使用一个超平面对所有的样本进行恰当的表达。PCA在CSDN上已经被讲了n次了,有就不详细讲了,就理一理思路,大家感兴趣可以搜其他大牛的博客看看。一般来说,有两个出发点,1)样本点到这个超平面的距离足够近(重构性,最大程度的代表样本点),2)样本点在这个超平面上的投影尽可能分开(可分性,样本点在降维空间内可以区分)下面使用第二个指导思想简单的推导一下
利用PCA进行降维的过程中,我们只需要按照特征值的大小顺序,将原来的样本挨个往特征向量投影即可,至于选几个向量,一般来说需要调参。
Andrew ng教程中又提及了白化(whiten)的概念,目的就是为了把特征向量的特征值变成1,这样就消除了主方向的影响,具体可以看 http://ufldl.stanford.edu/wiki/index.php/Whitening。
参考
《机器学习》周志华
《The Matrix Cook book》 version:November 15,2012(强烈推荐的手头工具书,涉及矩阵的求导之类的直接套公式就行)

相关文章推荐
- 从SVD到PCA——奇妙的数学游戏
- 白化(Whitening):PCA vs. ZCA
- 推荐引擎算法 - 猜你喜欢的东西
- Kernel PCA
- SVD分解的理解
- 基于单边Jacobi旋转的并行SVD算法-MPI框架
- pca 主成分分析
- svd矩阵奇异值分解
- recommentation
- PCA算法人脸识别小结--原理到实现
- vs2010+opencv调试
- PCA实训报告
- PCA + SVM 人脸识别
- 学习pca的一点小小感悟
- 有关PCA(Principal Component Analysis)主成分分析/主累積寄与率元分析
- SVD奇异值分解
- PCA-sift源码解释
- PCA学习过程
- matlab svd 和 eig 的区别
- 关于机器学习中数据降维的相关方法