从SVD到PCA——奇妙的数学游戏
2015-11-24 21:09
579 查看
方阵的特征值
当一个矩阵与一个向量相乘,究竟发生了什么?
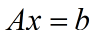
定义如下的 A 与 x:
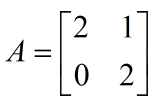
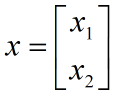
求得 b:

可以看到 A 乘以 x 就是将 x 的元素以线性的方式重新组合得到 b,数学上把这种重新组合叫 线性变换。
假设二维向量 x 满足如下条件:
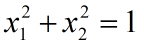
给定一个 2×2 的方阵:
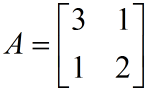
当 x 在满足约束条件的前提下取不同的值,Ax 的值的变化规律如下:

图中红色箭头为向量 x,蓝色箭头为矩阵 A 对 x 进行线性变换后的向量。
可以看到 A 对 x 做了两件事 : 旋转 与 伸缩。
在某些方向上,红色与蓝色向量共线,即在这些方向上 A 只对 x 进行了伸缩,称这些方向为 A 的主方向。在某个主方向上,设 A 对 x 伸缩的倍率为 λ,则:

把 λ 叫做方阵 A 的一个特征值,x 是相应的特征向量。
随着 x 的方向从 0 变化到 2π,红蓝向量有 4 次共线出现,但真正线性无关的共线只有2个,因为各有两次共线仅是方向相反,所以 A 有 2 个特征值。
蓝色向量划出了一个椭圆轨迹,这个椭圆表示了 A 是如何对 x 做线性变换的,可以认为这个椭圆包含了 A 的全部信息(因为 x 可以任意取值)。从动图可以看出,这个椭圆以 A 的特征值 λ1 和 λ2 为长轴和短轴的长度,特征向量 x1 和 x2 为长短轴的方向,即 λ1 、λ2、x1、x2 包括了 A 的所有信息。
由于这是一个狭长的椭圆,长轴包含的信息更多,所以 λ1 与 x1 包含了 A 的大部分信息。
矩阵的奇异值分解
当矩阵不是方阵,无法为其定义特征值与特征向量,可以用一个相似的概念来代替:奇异值。
通常用一种叫奇异值分解的算法来求取任意矩阵的奇异值:

抽象的概念要用具体的方式理解,来看几张图:

上图中的红色区域是一个以原点为中心的单位圆。圆当中的任意一点可以用向量 x 标示,且 x 满足:
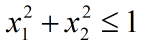
给定一个 2×2 的方阵:
利用 MATLAB 对 A 做奇异值分解:

即:
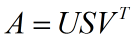
所以:
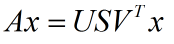
先看 V' 对 x 做了什么:
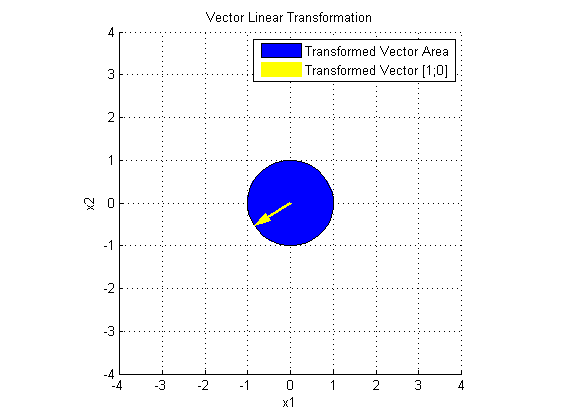
V' 使 x 旋转了一个角度。
再看 SV' 对 x 做了什么:
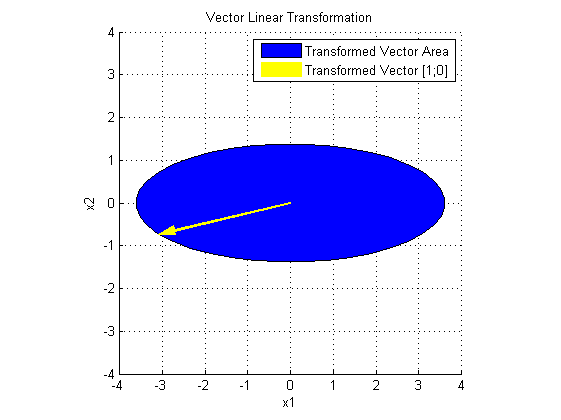
S 在 V'x 的基础上,在两个主方向进行了伸缩变换。
最后看 USV' 对 x 做了什么:
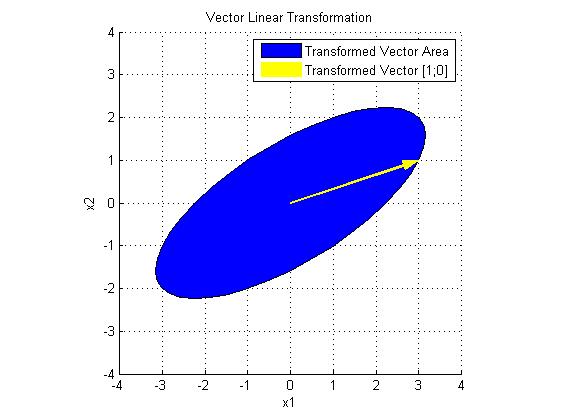
U 在 SV'x 的基础上,进行了旋转变换。
至此,奇异值分解的几何意义可谓一目了然:
A 是一个线性变换,把 A 分解成 USV',S 给出了变换后椭圆长短轴的长度, U 和 V' 一起确定了变换后的方向,所以 U、S、V' 包含了这个线性变换的全部信息。S 矩阵的对角线元素称为 A 的奇异值,与特征值一样,大的奇异值对应长轴,小的奇异值对应短轴,大的奇异值包含更多信息。
当矩阵是对称方阵时,其特征值与奇异值相等。
网上有一个很经典的案例来说明 SVD 的应用:
有一张 25×15 的图片:

把它用矩阵表示:

这个矩阵的秩等于 3。即矩阵只有 3 种线性无关的列,其他的列都是冗余的:

对 M 做奇异值分解,得到 3 个不为零的奇异值:
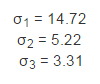
它们分别对应着 3 个线性无关的列。
另一种更一般的情况,处理一张有噪声的图片:

它的奇异值为:
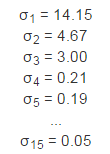
可以想象在15维空间中有一个超椭球体,它有15个轴,其中有3个轴是主要的轴(对应着3个最大的奇异值),有这3个轴就可以大致勾勒出超椭球体的形状,因为它们包含了大部分信息。
如果 S 中的对角线元素从大到小排列,我们就只保留 S 左上角的 3×3 的子矩阵,并相应保留 U 和 V 的前 3 列,简化后的 U、S、V 依然保留了 M 的大部分信息:
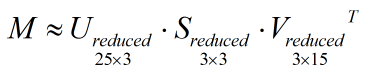
主成分分析
案例1
假如有 m 条1维数据,由于混入了噪音,变成了2维。
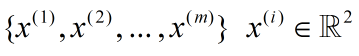
在坐标系中把他们绘制出来:

主成分分析(PCA)可以用来排除这些噪音,把原来的维度提取出来。
首先将数据归一化,并将其所包含的信息用 协方差矩阵(协方差矩阵表示不同维度之间的相关关系,这是一个对称矩阵)来表示:
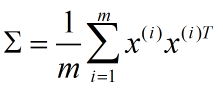
Σ 有2个奇异值,例如:
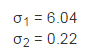
显然前者包含了大部分信息,对应的矩阵 U 的第一列就是主成分的方向:

于是就通过降维对数据实现了去噪。
在更一般的情况下,假设有 m 条 n 维的数据,对协方差矩阵进行奇异值分解得到 n 个从大到小排列的奇异值:

如果希望信息利用率在99%以上,可利用如下不等式来确定主成分的维度 p:
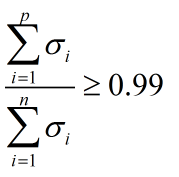
案例2
有 m 张人脸图,每张的大小都是 32×32 (1024 个像素)。

每个像素的颜色由一个灰度值来表示,这样每张图片就用一个 1024×1 的向量来表示。
定义第 i 张图片的数据为:

将数据归一化并计算其协方差矩阵 Σ ,Σ 是一个 1024×1024 的矩阵。
对 Σ 做奇异值分解,得到矩阵 U,S 和 V。其中 U 也是一个 1024×1024 的矩阵。根据之前的比喻,U 的每一列代表了 1024 维空间中一个超椭球体的主轴方向。其中若干个方向包含了 Σ 的大部分信息,我们把这些方向(对应 U 中的若干列)叫做数据的主成分。
假设取 U 的前 k(k<1024) 列作为主方向,在 1024 维空间中有一个数据点 x,记 x 在这 k 个主方向上的投影为 x(project),那么 x(project) 是对 x 的一个近似(更精确地讲,将 k 维的 x(project) 重新投影到 1024 维空间中得到 x(approx) 才是对 x 的近似,这个技术叫数据恢复(Data Reconstruction))。需要注意的一点是:x(project) 与 x(approx) 是等价的,它们是同一个数据点在不同坐标系下的不同表达(升维不丢失信息)。当k=1024, x(approx)=x。
在应用中,用降维后的 x(project) 参与后续计算,由于数据量变小,计算速度将加快。
回到案例中,我取 k = 100,即取 U 的前 100 列作为数据的主方向(主成分)。因为每一列都是 1024 维向量,可以把它们像图片一样打印出来:

越靠前的列对应着越大的奇异值,它们也包含了更多信息。在本例中,每个主方向(主成分)就是一张“基础图片”,每张原图都是这些基础图片的线性组合(系数就是原图在主方向上的投影)。
现在用这 100 张“基础图片”去简化原图片(将降维后的100维数据重新投影到1024维空间——Data Reconstruction),效果如下:

最后附上一首打油诗来帮助记忆PCA的原理:
主成分即主方向
数据投影在其上
投影形成新数据
降维加速本领强
总结
本文的灵感来自于 Andrew Ng 在 Coursera 上的 《Machine Learning》课程,在上一篇文章中我提到过,这是一门面向应用的,强调快速入门的课程。我始终认为,知其然也要知其所以然,也就是背后的数学原理,这是一名合格工程师应有的素质。
当一个矩阵与一个向量相乘,究竟发生了什么?
定义如下的 A 与 x:
求得 b:
可以看到 A 乘以 x 就是将 x 的元素以线性的方式重新组合得到 b,数学上把这种重新组合叫 线性变换。
假设二维向量 x 满足如下条件:
给定一个 2×2 的方阵:
当 x 在满足约束条件的前提下取不同的值,Ax 的值的变化规律如下:
图中红色箭头为向量 x,蓝色箭头为矩阵 A 对 x 进行线性变换后的向量。
可以看到 A 对 x 做了两件事 : 旋转 与 伸缩。
在某些方向上,红色与蓝色向量共线,即在这些方向上 A 只对 x 进行了伸缩,称这些方向为 A 的主方向。在某个主方向上,设 A 对 x 伸缩的倍率为 λ,则:
把 λ 叫做方阵 A 的一个特征值,x 是相应的特征向量。
随着 x 的方向从 0 变化到 2π,红蓝向量有 4 次共线出现,但真正线性无关的共线只有2个,因为各有两次共线仅是方向相反,所以 A 有 2 个特征值。
蓝色向量划出了一个椭圆轨迹,这个椭圆表示了 A 是如何对 x 做线性变换的,可以认为这个椭圆包含了 A 的全部信息(因为 x 可以任意取值)。从动图可以看出,这个椭圆以 A 的特征值 λ1 和 λ2 为长轴和短轴的长度,特征向量 x1 和 x2 为长短轴的方向,即 λ1 、λ2、x1、x2 包括了 A 的所有信息。
由于这是一个狭长的椭圆,长轴包含的信息更多,所以 λ1 与 x1 包含了 A 的大部分信息。
矩阵的奇异值分解
当矩阵不是方阵,无法为其定义特征值与特征向量,可以用一个相似的概念来代替:奇异值。
通常用一种叫奇异值分解的算法来求取任意矩阵的奇异值:
抽象的概念要用具体的方式理解,来看几张图:
上图中的红色区域是一个以原点为中心的单位圆。圆当中的任意一点可以用向量 x 标示,且 x 满足:
给定一个 2×2 的方阵:
利用 MATLAB 对 A 做奇异值分解:
即:
所以:
先看 V' 对 x 做了什么:
V' 使 x 旋转了一个角度。
再看 SV' 对 x 做了什么:
S 在 V'x 的基础上,在两个主方向进行了伸缩变换。
最后看 USV' 对 x 做了什么:
U 在 SV'x 的基础上,进行了旋转变换。
至此,奇异值分解的几何意义可谓一目了然:
A 是一个线性变换,把 A 分解成 USV',S 给出了变换后椭圆长短轴的长度, U 和 V' 一起确定了变换后的方向,所以 U、S、V' 包含了这个线性变换的全部信息。S 矩阵的对角线元素称为 A 的奇异值,与特征值一样,大的奇异值对应长轴,小的奇异值对应短轴,大的奇异值包含更多信息。
当矩阵是对称方阵时,其特征值与奇异值相等。
网上有一个很经典的案例来说明 SVD 的应用:
有一张 25×15 的图片:
把它用矩阵表示:
这个矩阵的秩等于 3。即矩阵只有 3 种线性无关的列,其他的列都是冗余的:
对 M 做奇异值分解,得到 3 个不为零的奇异值:
它们分别对应着 3 个线性无关的列。
另一种更一般的情况,处理一张有噪声的图片:
它的奇异值为:
可以想象在15维空间中有一个超椭球体,它有15个轴,其中有3个轴是主要的轴(对应着3个最大的奇异值),有这3个轴就可以大致勾勒出超椭球体的形状,因为它们包含了大部分信息。
如果 S 中的对角线元素从大到小排列,我们就只保留 S 左上角的 3×3 的子矩阵,并相应保留 U 和 V 的前 3 列,简化后的 U、S、V 依然保留了 M 的大部分信息:
主成分分析
案例1
假如有 m 条1维数据,由于混入了噪音,变成了2维。
在坐标系中把他们绘制出来:
主成分分析(PCA)可以用来排除这些噪音,把原来的维度提取出来。
首先将数据归一化,并将其所包含的信息用 协方差矩阵(协方差矩阵表示不同维度之间的相关关系,这是一个对称矩阵)来表示:
Σ 有2个奇异值,例如:
显然前者包含了大部分信息,对应的矩阵 U 的第一列就是主成分的方向:
于是就通过降维对数据实现了去噪。
在更一般的情况下,假设有 m 条 n 维的数据,对协方差矩阵进行奇异值分解得到 n 个从大到小排列的奇异值:
如果希望信息利用率在99%以上,可利用如下不等式来确定主成分的维度 p:
案例2
有 m 张人脸图,每张的大小都是 32×32 (1024 个像素)。
每个像素的颜色由一个灰度值来表示,这样每张图片就用一个 1024×1 的向量来表示。
定义第 i 张图片的数据为:
将数据归一化并计算其协方差矩阵 Σ ,Σ 是一个 1024×1024 的矩阵。
对 Σ 做奇异值分解,得到矩阵 U,S 和 V。其中 U 也是一个 1024×1024 的矩阵。根据之前的比喻,U 的每一列代表了 1024 维空间中一个超椭球体的主轴方向。其中若干个方向包含了 Σ 的大部分信息,我们把这些方向(对应 U 中的若干列)叫做数据的主成分。
假设取 U 的前 k(k<1024) 列作为主方向,在 1024 维空间中有一个数据点 x,记 x 在这 k 个主方向上的投影为 x(project),那么 x(project) 是对 x 的一个近似(更精确地讲,将 k 维的 x(project) 重新投影到 1024 维空间中得到 x(approx) 才是对 x 的近似,这个技术叫数据恢复(Data Reconstruction))。需要注意的一点是:x(project) 与 x(approx) 是等价的,它们是同一个数据点在不同坐标系下的不同表达(升维不丢失信息)。当k=1024, x(approx)=x。
在应用中,用降维后的 x(project) 参与后续计算,由于数据量变小,计算速度将加快。
回到案例中,我取 k = 100,即取 U 的前 100 列作为数据的主方向(主成分)。因为每一列都是 1024 维向量,可以把它们像图片一样打印出来:
越靠前的列对应着越大的奇异值,它们也包含了更多信息。在本例中,每个主方向(主成分)就是一张“基础图片”,每张原图都是这些基础图片的线性组合(系数就是原图在主方向上的投影)。
现在用这 100 张“基础图片”去简化原图片(将降维后的100维数据重新投影到1024维空间——Data Reconstruction),效果如下:
最后附上一首打油诗来帮助记忆PCA的原理:
主成分即主方向
数据投影在其上
投影形成新数据
降维加速本领强
总结
本文的灵感来自于 Andrew Ng 在 Coursera 上的 《Machine Learning》课程,在上一篇文章中我提到过,这是一门面向应用的,强调快速入门的课程。我始终认为,知其然也要知其所以然,也就是背后的数学原理,这是一名合格工程师应有的素质。

相关文章推荐
- Kernel PCA
- 我对特征值与特征向量的理解
- 特征值求解器的效率比较
- SVD分解的理解
- 基于单边Jacobi旋转的并行SVD算法-MPI框架
- pca 主成分分析
- svd矩阵奇异值分解
- recommentation
- PCA算法人脸识别小结--原理到实现
- 主成分分析和因子分析的区别
- vs2010+opencv调试
- PCA实训报告
- PCA + SVM 人脸识别
- Fisher判别法
- 学习pca的一点小小感悟
- 有关PCA(Principal Component Analysis)主成分分析/主累積寄与率元分析
- PCA-sift源码解释
- matlab svd 和 eig 的区别
- 关于机器学习中数据降维的相关方法
- 机器学习实战精读--------主成分分析(PCA)