利用矩阵计算提升推荐系统的速度
2016-03-18 11:40
387 查看
在《利用python实现电影推荐》一文中,使用的cal_score()函数计算各用户对每一部电影的评分,cal_matscore()调用cal_score()计算预估评分矩阵。由于cal_matscore()内嵌两个循环,调用的cal_score()包含一个循环,实际上是三层循环嵌套,时间复杂度达到O(n3)。
在用户-电影矩阵规模较小时,采用以上方法没有问题;但一旦用户-电影矩阵的规模达到数千行、数千列时,计算时间会大大增加。
为此,本文利用矩阵计算方式重写评分矩阵的计算程序,极大提升了运算速度。重写后的程序包含cal_matscore()和recommend()两个方法,分别用来计算评分矩阵和进行推荐。
基本思想如下:
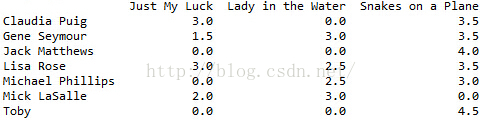
1)读入数据,形成用户-电影原始评分矩阵。如图所示:矩阵中的数据为用户(横坐标)对特定电影(纵坐标)的评分。
2)计算电影-电影相关度矩阵。根据用户-电影矩阵计算不同电影之间的相关系数(一般用person相关系数),形成电影-电影相关度矩阵。
3)计算用户-电影预估评分矩阵(cal_matscore(matrix,mcors))。参数matrix表示用户-电影原始评分矩阵(size:m×n),mcors表示电影-电影相关度矩阵(size: n×n)。np.dot(matrix,mcors)实现matrix和mcors的点乘,计算得到评分*相关度的和矩阵rating_cor_smatrix;通过matrix!=0的逻辑运算得到matrix_I,在matrix_I中用户已评分电影标记为True、未评分的标记为False;利用np.dot(matrix_I,mcors)实现matrix_I和mcors的点乘,计算得到已评分电影的相关度和矩阵。
这样,将rating_cor_smatrix除以cor_smatrix的对应项即可得到用户对电影评分的加权平均值矩阵,也就是对电影评分的预测值矩阵。
score_matrix = rating_cor_smatrix/cor_smatrix
4)根据预估评分矩阵做出推荐(recommend(score_matrix,user,n))。有了score_matrix,推荐实际上就变成了查询用户user的预估评分排前n位的电影。
源代码如下。由于用到了矩阵运算,所以直观理解起来可能比较困难,建议和以上文字介绍对照来看。
在用户-电影矩阵规模较小时,采用以上方法没有问题;但一旦用户-电影矩阵的规模达到数千行、数千列时,计算时间会大大增加。
为此,本文利用矩阵计算方式重写评分矩阵的计算程序,极大提升了运算速度。重写后的程序包含cal_matscore()和recommend()两个方法,分别用来计算评分矩阵和进行推荐。
基本思想如下:
1)读入数据,形成用户-电影原始评分矩阵。如图所示:矩阵中的数据为用户(横坐标)对特定电影(纵坐标)的评分。
2)计算电影-电影相关度矩阵。根据用户-电影矩阵计算不同电影之间的相关系数(一般用person相关系数),形成电影-电影相关度矩阵。
3)计算用户-电影预估评分矩阵(cal_matscore(matrix,mcors))。参数matrix表示用户-电影原始评分矩阵(size:m×n),mcors表示电影-电影相关度矩阵(size: n×n)。np.dot(matrix,mcors)实现matrix和mcors的点乘,计算得到评分*相关度的和矩阵rating_cor_smatrix;通过matrix!=0的逻辑运算得到matrix_I,在matrix_I中用户已评分电影标记为True、未评分的标记为False;利用np.dot(matrix_I,mcors)实现matrix_I和mcors的点乘,计算得到已评分电影的相关度和矩阵。
这样,将rating_cor_smatrix除以cor_smatrix的对应项即可得到用户对电影评分的加权平均值矩阵,也就是对电影评分的预测值矩阵。
score_matrix = rating_cor_smatrix/cor_smatrix
4)根据预估评分矩阵做出推荐(recommend(score_matrix,user,n))。有了score_matrix,推荐实际上就变成了查询用户user的预估评分排前n位的电影。
源代码如下。由于用到了矩阵运算,所以直观理解起来可能比较困难,建议和以上文字介绍对照来看。
import pandas as pd
import numpy as np
import time
t1 = time.time()
#read the data
data={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'The Night Listener': 3.0},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Just My Luck': 2.0, 'Lady in the Water': 3.0,'Superman Returns': 3.0, 'The Night Listener': 3.0, 'You, Me and Dupree': 2.0},
'Jack Matthews': {'Snakes on a Plane': 4.0, 'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}
#clean&transform the data
data = pd.DataFrame(data)
#0 represents not been rated
data = data.fillna(0)
#each column represents a movie
mdata = data.T
#calculate the simularity of different movies, normalize the data into [0,1]
np.set_printoptions(3)
mcors = np.corrcoef(mdata, rowvar=0)
mcors = 0.5+mcors*0.5
mcors = pd.DataFrame(mcors, columns=mdata.columns, index=mdata.columns)
#calculate the socre matrix
#matrix:the user-movie rating matrix
#mcors:the movie-movie correlation matrix
#rating_cor_smatrix:rating * correlation summation matrix
#cor_smatrix:correlation summation matrix
#score_matrix:score matrix of movie for different users
def cal_matscore(matrix,mcors):
t1 = time.time()
rating_cor_smatrix = np.dot(matrix,mcors)
matrix_I = (matrix!=0)
cor_smatrix = np.dot(matrix_I,mcors)
score_matrix = rating_cor_smatrix/cor_smatrix
score_matrix = pd.DataFrame(score_matrix, columns=matrix.columns, index=matrix.index)
matrix_nI = (matrix==0)
score_matrix = score_matrix[matrix_nI]
t2 = time.time()
print 'cal_matscore time consumed:',round((t2-t1),2),'s'
return score_matrix
#give recommendations: depending on the score matrix
#matrix:the user-movie matrix
#score_matrix:score matrix of movie for different users
#user:the user id
#n:the number of recommendations
def recommend(score_matrix,user,n):
user_ratings = score_matrix.ix[user]
not_rated_item = user_ratings[user_ratings.notnull()]
recom_items = not_rated_item.sort_values(ascending=False)
return recom_items[:n]
#main
score_matrix = cal_matscore(mdata,mcors)
t2 = time.time()
print('time consumed:'+str(t2-t1))
print score_matrix
#for i in range(10):
# user = input(str(i)+' please input the name of user:')
# print recommend(score_matrix,user,2)

相关文章推荐
- python3 字符编码处理
- Linux内核配置系统-Kconfig和Makefile参数讲解
- Gson解析第三方提供Json数据(天气预报,新闻等)
- CentOS 下FTP服务器(vsftpd)的安装
- Delphi语言如何对自定义类进行持久化保存及恢复 (性能远比json/xml高)
- C# - 序列化与反序列化
- connect to SQL Server in python on centos
- intel hex文件格式
- 项目中的小技巧-文件的绝对路径
- java project 项目的开发--简单的http请求, 模仿浏览器发出请求get
- 【开车旅行】题解(NOIP2012提高组)
- 生成树配置实战
- linux 自启动oracle脚本(使用oracle自带脚本)
- Android 屏幕适配方案
- 五大常用算法——动态规划
- JNI常用函数大全
- 单例模式的创建方式
- java-io-inputStream
- digital root问题
- 网络编程 实现服务器与客户端通讯