GIS+=地理信息+行业+大数据——Spark集群下SPARK SQL开发测试介绍
2016-02-24 22:30
1521 查看
Spark集群下SPARK SQL开发介绍
在之前的文章《SPARK for IntelliJ IDEA 开发环境部署》中已经完成了对开发环境的搭建工作,下面就可以开发程序了。对于GIS的数据分析需要通过SQL查询和空间查询来实现对空间数据的查询和检索。而Spark SQL是进行属性查询的主要工具,下面就利用Spark SQL技术针对自己组织的数据进行SQL查询的功能开发。
开发环境操作系统:Ubuntu 14开发工具:IntelliJ IDEA 15开发语言:scala 2.10.6Java版本:JDK 1.7开发的功能主要是模拟一个json数据文件,在集群环境下读取该数据,并对其数据进行sql查询。下面开始开发,创建一个scala类文件命名为mysqltest,代码如下: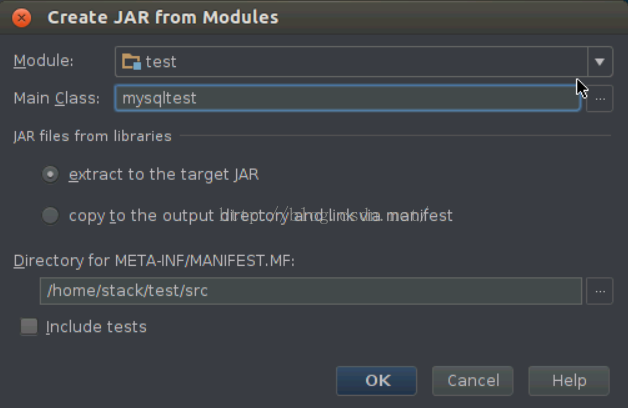
 最后依次选择“Build”–> “Build Artifact”编译生成jar包。具体如下图所示。
最后依次选择“Build”–> “Build Artifact”编译生成jar包。具体如下图所示。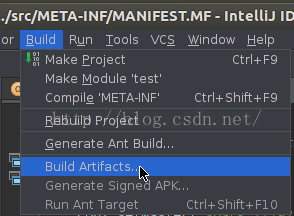 代码编写完毕,可以通过iDEA运行并查看结果了。除了以上在iDEA中运行代码以外,还可以将编译的test.jar文件上传到master节点上,通过spark-submit命令执行,
代码编写完毕,可以通过iDEA运行并查看结果了。除了以上在iDEA中运行代码以外,还可以将编译的test.jar文件上传到master节点上,通过spark-submit命令执行,
运行结果是一样的。具体命令及参数如下:
在分析运行结果之前,对以上代码中的关键步骤做一下说明。1.关于SparkConf对象。SparkConf提供了Spark运行的各种配置信息的对象,在本次测试程序中为了要将程序运行在Spark集群环境下,所以通过setMaster方法指定Master节点所在的服务地址。这个方法等同于通过spark-submit命令来运行test.jar时的参数中的—master
spark://192.168.12.210:7077。如果要在开发的代码中加入更多spark-submit命令中包含的参数,比如设置Executor Memory参数,命令的参数写法是spark-submit executor-memory 10g,而在scala程序中的代码是
通过iDEA运行程序来查看输出的日志信息,查看关键的计算过程。先介绍几个执行程序输出的关键日志。1.程序启动后在ip为192.168.13.75的开发节点上启动了SparkUI,并成功连接了master节点的服务。
s。 日志内容如下:
日志内容如下:
首先在通过的加密验证之后,先后启动driverPropsFetcher和sparkExecutor服务和端口,基于分配给该节点的调度作业任务来进行计算,从日志中可以看到192.168.12.155节点被分配执行的task有:task 4.0 in stage 0.0 (TID 4)task 1.0 in stage 0.0 (TID 1)task 0.0 in stage 1.0 (TID 5)task 1.0 in stage 1.0 (TID 6)task 4.0 in stage 1.0 (TID 9)这与前面执行程序输出的日志中显示的任务分配是一致的。在worker的执行过程中除了计算以外还有两个关键的操作,一个是获取test.jar文件,然后将该文件拷贝到本地的任务执行目录下,并加载类文件。下面的日志显示了worker已经获取到了test.jar的下载地址
通过以上的测试我们完成了对SparkSQL的开发、调试、部署、运行的完整过程的实践,并对日志的关键内容进行了分析,体验到了Spark在分布式计算环境下的高性能优势。这里并没有对Spark任务调度的原理做详细介绍,有兴趣的可以查看Spark官方文档或者搜索一些关于作业调度相关的博客来学习了解。最后将几个在开发过程中会遇到的一些问题做个分享。问题1:TaskSchedulerImpl: Initial job has not accepted
any resources;当运行程序时,master在最后反复出现以上的日志而不进行后续操作时,有几个原因可以确认。1. 可能是节点可用的资源不足于分配的资源,比如剩余内存不足。2. 检查Spark-env.sh的配置信息,检查SPARK_MASTER_IP
和 SPARK_LOCAL_IP 是否正确(在个人笔记本开发使用虚拟机如果没有固定ip的话会容易犯此错误)。3. 检查客户端节点的防火墙是否因打开而影响了节点之间的访问。问题2:如何通过程序动态指定Executor Memory的大小。例如:sparkConf.set("spark.executor.memory","800m")问题3:运行程序出现类似java.lang.ClassNotFoundException的错误。在本文的测试程序中,如果出现这个问题,有可能是test.jar的路径写错了,导致worker没有办法通过该路径找到test.jar。
前言
在之前的文章《SPARK for IntelliJ IDEA 开发环境部署》中已经完成了对开发环境的搭建工作,下面就可以开发程序了。对于GIS的数据分析需要通过SQL查询和空间查询来实现对空间数据的查询和检索。而Spark SQL是进行属性查询的主要工具,下面就利用Spark SQL技术针对自己组织的数据进行SQL查询的功能开发。
开发
开发环境操作系统:Ubuntu 14开发工具:IntelliJ IDEA 15开发语言:scala 2.10.6Java版本:JDK 1.7开发的功能主要是模拟一个json数据文件,在集群环境下读取该数据,并对其数据进行sql查询。下面开始开发,创建一个scala类文件命名为mysqltest,代码如下:01.
import
org.apache.spark.sql.SQLContext
02.
import
org.apache.spark.{SparkContext,SparkConf}03.
import
scala.sys.SystemProperties
04.
05.
object
mysqltest {06.
def
main(args
:
Array[String]) {07.
val
sparkConf
=
new
SparkConf().setAppName(
"mysqltest"
)
08.
sparkConf.setMaster(
"spark://192.168.12.154:7077"
)
09.
val
sc
=
new
SparkContext(sparkConf)
10.
sc.addJar(
"/home/test.jar"
)
11.
val
sqlContext
=
new
SQLContext(sc)
12.
val
dd
=
new
SystemProperties()
13.
val
sparkhome
=
dd.get(
"SPARK_HOME"
)
14.
val
_
ar
=
args
15.
val
sss
=
sys.props
16.
val
sparkhomepath
=
"/home/sougou.json"
17.
val
sougou
=
sqlContext.read.json(sparkhomepath)
18.
// 输出schema结构
19.
sougou.printSchema()
20.
// 注册DataFrame 为一个table.
21.
sougou.registerTempTable(
"sougou"
)
22.
// 通过sqlContext对象进行SQL查询
23.
var
arry
=
sqlContext.sql(
"SELECT * FROM sougouWHERE num >= 13 AND num <= 100"
)
24.
//show方法默认显示20条记录的结果记录
25.
arry.show()
26.
sc.stop()
27.
}
28.
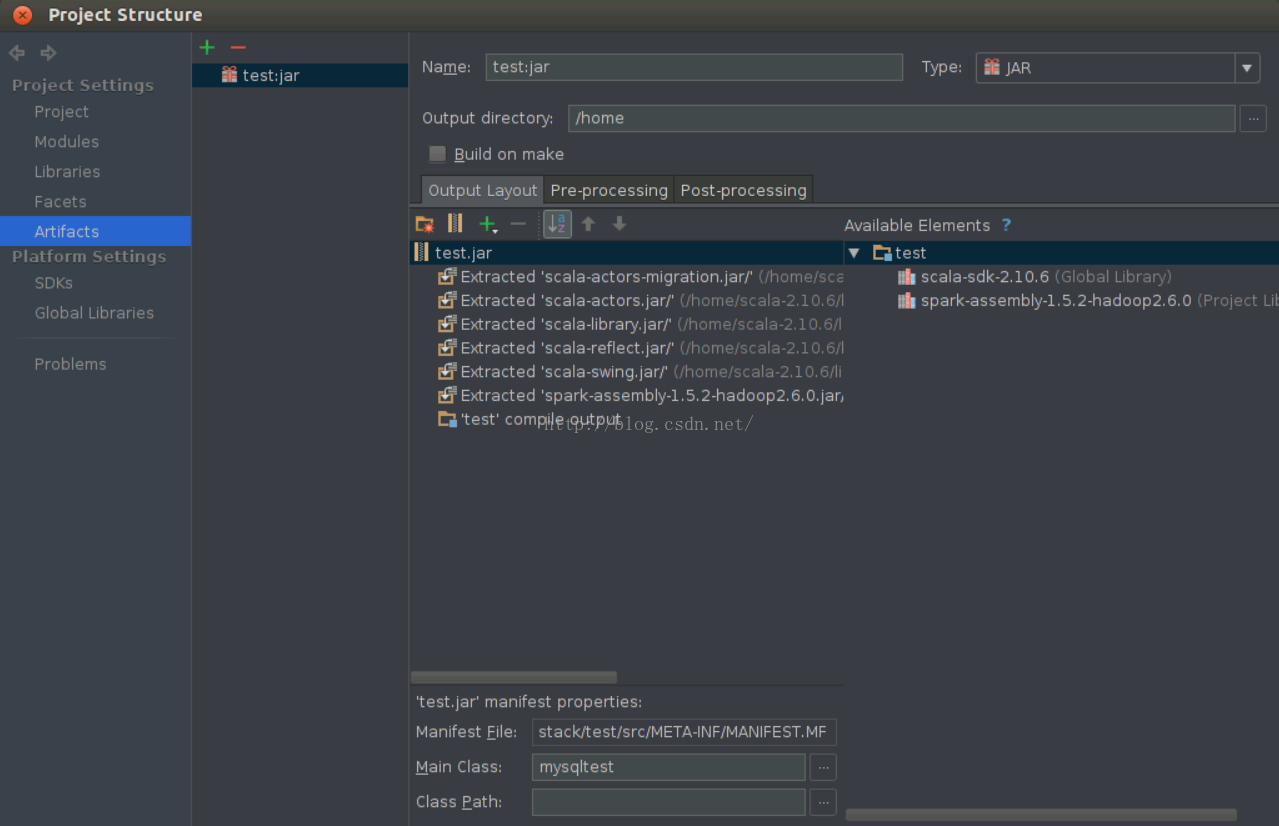
}注:在开发调试状态下需要添加setMaster和addJar方法为了测试程序在Spark集群环境下的分布式计算的效果,需要把程序打成jar包,才能运行在spark 集群中,可以按照以下步骤操作:依次选择“File”–> “Project Structure” –> “Artifact”,选择“+”–> “Jar” –> “From Modules with dependencies”,选择main函数,并在弹出框中选择输出jar位置,并选择“OK”。
最后依次选择“Build”–> “Build Artifact”编译生成jar包。具体如下图所示。代码编写完毕,可以通过iDEA运行并查看结果了。除了以上在iDEA中运行代码以外,还可以将编译的test.jar文件上传到master节点上,通过spark-submit命令执行,运行结果是一样的。具体命令及参数如下:
1.
./bin/spark-submit master spark://192.168.12.210:7077 name mysqltest class mysqltest /home/
test
.jar
代码分析
在分析运行结果之前,对以上代码中的关键步骤做一下说明。1.关于SparkConf对象。SparkConf提供了Spark运行的各种配置信息的对象,在本次测试程序中为了要将程序运行在Spark集群环境下,所以通过setMaster方法指定Master节点所在的服务地址。这个方法等同于通过spark-submit命令来运行test.jar时的参数中的—masterspark://192.168.12.210:7077。如果要在开发的代码中加入更多spark-submit命令中包含的参数,比如设置Executor Memory参数,命令的参数写法是spark-submit executor-memory 10g,而在scala程序中的代码是
1.
val
conf
=
new
SparkConf()
2.
conf.set(
"spark.executor.memory"
,
"10g"
)2.关于SparkContext。SparkContext类是Spark的关键类,是Spark的入口,负责连接Spark集群,创建RDD,累积量和广播量等。从本质上来说,SparkContext是Spark的对外接口,负责向调用这提供Spark的各种功能。它的作用是一个容器。SparkContext类非常简洁,大多数函数体只有几行代码。
1.
val
sc
=
new
SparkContext(sparkConf)
2.
sc.addJar(
"/home/test.jar"
)代码执行之后输出的正确日志如下
1.
16/02/19 16:50:38 INFO SparkContext: Added JAR /home/test.jar at http://192.168.13.34:53254/jars/test.jar with timestamp 1455871838045addJar方法将该jar包提交到spark集群中,然后spark的master会将该jar包分发到各个worker上面。3.关于测试数据。这里由于没有使用hdfs,而是测试程序通过sqlContext直接读取sougou.json文件,文件大小为134m,包含140多万条记录。文件的内容结构:{"fstw":"工艺","scd":"供应","num":392}{"fstw":"政法","scd":"研究生","num":6}{"fstw":"重复","scd":"设计","num":15}……将数据放在了一个各个节点都相同的目录下,并将数据文件拷贝在各个节点上做测试。
1.
val
sparkhomepath
=
"/home/sougou.json"代码中通过sqlContext.read方法返回了DataFrameReader对象,该对象提供了多种数据读取的方法,包括jdbc、json、hdfs等等。返回的结果是DataFrame类型,就是早期版本的SchemeRDD。
结果分析
通过iDEA运行程序来查看输出的日志信息,查看关键的计算过程。先介绍几个执行程序输出的关键日志。1.程序启动后在ip为192.168.13.75的开发节点上启动了SparkUI,并成功连接了master节点的服务。1.
16/02/24 11:33:39 INFO Utils: Successfully started service 'SparkUI' on port 4040.
2.
16/02/24 11:33:39 INFO SparkUI: Started SparkUI at http://192.168.13.75:4040
3.
16/02/24 11:33:39 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
4.
16/02/24 11:33:39 INFO AppClient$ClientEndpoint: Connecting to master spark://192.168.12.154:7077...2.已经成功的将test.jar和sougou.json的目录提交到了集群中
1.
16/02/24 11:33:46 INFO SparkContext: Added JAR /home/test.jar at http://192.168.13.75:43680/jars/test.jar with timestamp 1456284826060
2.
16/02/24 11:33:48 INFO JSONRelation: Listing file:/home/sougou.json on driver3.通过计算资源和DAGScheduler调度,创建了第一个Job,名为Job 0,用来读取json数据,通过任务调度生成了5个task,分别分配到3个集群节点中进行处理。
1.
16/02/24 11:33:51 INFO TaskSchedulerImpl: Adding task set 0.0 with 5 tasks
2.
16/02/24 11:33:51 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0,192.168.12.154,PROCESS_LOCAL,2181 bytes)
3.
16/02/24 11:33:51 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1,192.168.12.155,PROCESS_LOCAL,2181 bytes)
4.
16/02/24 11:33:51 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2,192.168.12.156,PROCESS_LOCAL,2181 bytes)
5.
16/02/24 11:33:51 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3,192.168.12.154,PROCESS_LOCAL,2181 bytes)
6.
16/02/24 11:33:51 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4,192.168.12.155,PROCESS_LOCAL,2181 bytes)4.第一步操作Job 0完成后,json数据已经成功导入进spark,并生成了一个DataFrame,程序中输出了它的结构
1.
root
2.
| fstw: string (nullable = true)
3.
| num: long (nullable = true)
4.
| scd: string (nullable = true)5.第二步操作是做SQL查询,基于DAGScheduler生成了Job 1,导入的数据在内存中被划分了8个MapPartitionsRDD,进行分布式的并行计算。最终SQL查询总共用了11.497205s,因为是在虚拟机环境中做的测试,所以性能很慢,实际在部署了spark集群的三台普通4核4g内存的pc机物理环境下测试,时间为0.506523
s。
01.
16/02/24 11:35:16 INFO TaskSchedulerImpl: Adding task set 1.0 with 5 tasks
02.
16/02/24 11:35:16 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 5,192.168.12.154,PROCESS_LOCAL,2181 bytes)
03.
16/02/24 11:35:16 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 6,192.168.12.155,PROCESS_LOCAL,2181 bytes)
04.
16/02/24 11:35:17 INFO TaskSetManager: Starting task 2.0 in stage 1.0 (TID 7,192.168.12.156,PROCESS_LOCAL,2181 bytes)
05.
16/02/24 11:35:17 INFO TaskSetManager: Starting task 3.0 in stage 1.0 (TID 8,192.168.12.154,PROCESS_LOCAL,2181 bytes)
06.
16/02/24 11:35:17 INFO TaskSetManager: Starting task 4.0 in stage 1.0 (TID 9,192.168.12.155,PROCESS_LOCAL,2181 bytes)
07.
16/02/24 11:35:17 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.12.155:38649 (size: 3.5 KB,free: 530.3 MB)
08.
16/02/24 11:35:17 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.12.154:53534 (size: 3.5 KB,free: 530.3 MB)
09.
16/02/24 11:35:17 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.12.155:38649 (size: 19.4 KB,free: 530.3 MB)
10.
16/02/24 11:35:19 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.12.154:53534 (size: 19.4 KB,free: 530.3 MB)
11.
16/02/24 11:35:22 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.12.156:35829 (size: 3.5 KB,free: 530.3 MB)
12.
16/02/24 11:35:22 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.12.156:35829 (size: 19.4 KB,free: 530.3 MB)
13.
16/02/24 11:35:22 INFO TaskSetManager: Finished task 4.0 in stage 1.0 (TID 9) in 5564 ms on 192.168.12.155 (1/5)
14.
16/02/24 11:35:25 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 6) in 8330 ms on 192.168.12.155 (2/5)
15.
16/02/24 11:35:25 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 5) in 8389 ms on 192.168.12.154 (3/5)
16.
16/02/24 11:35:25 INFO TaskSetManager: Finished task 3.0 in stage 1.0 (TID 8) in 8411 ms on 192.168.12.154 (4/5)
17.
16/02/24 11:35:28 INFO TaskSetManager: Finished task 2.0 in stage 1.0 (TID 7) in 11481 ms on 192.168.12.156 (5/5)
18.
16/02/24 11:35:28 INFO TaskSchedulerImpl: Removed TaskSet 1.0,whose tasks have all completed,from pool
19.
16/02/24 11:35:28 INFO DAGScheduler: ResultStage 1 (collect at mysqltest.scala:39) finished in 11.483 s
20.
16/02/24 11:35:28 INFO DAGScheduler: Job 1 finished: collect at mysqltest.scala:39,took 11.497205 s下面我们对worker的执行过程中输出的日志中的关键信息进行分析。在以下三个节点中选择192.168.12.155的日志进行介绍。
日志内容如下:01.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
02.
16/02/24 11:33:40 INFO CoarseGrainedExecutorBackend: Registered signal handlers for [TERM,HUP,INT]
03.
16/02/24 11:33:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
04.
16/02/24 11:33:41 INFO SecurityManager: Changing view acls to: root
05.
16/02/24 11:33:41 INFO SecurityManager: Changing modify acls to: root
06.
16/02/24 11:33:41 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
07.
16/02/24 11:33:42 INFO Slf4jLogger: Slf4jLogger started
08.
16/02/24 11:33:42 INFO Remoting: Starting remoting
09.
16/02/24 11:33:42 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://driverPropsFetcher@192.168.12.155:45705]
10.
16/02/24 11:33:42 INFO Utils: Successfully started service 'driverPropsFetcher' on port 45705.
11.
16/02/24 11:33:43 INFO SecurityManager: Changing view acls to: root
12.
16/02/24 11:33:43 INFO SecurityManager: Changing modify acls to: root
13.
16/02/24 11:33:43 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
14.
16/02/24 11:33:43 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
15.
16/02/24 11:33:43 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
16.
16/02/24 11:33:43 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
17.
16/02/24 11:33:43 INFO Slf4jLogger: Slf4jLogger started
18.
16/02/24 11:33:43 INFO Remoting: Starting remoting
19.
16/02/24 11:33:43 INFO Utils: Successfully started service 'sparkExecutor' on port 38788.
20.
16/02/24 11:33:43 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkExecutor@192.168.12.155:38788]
21.
16/02/24 11:33:43 INFO DiskBlockManager: Created local directory at /tmp/spark-8e4d1501-3f08-499f-a748-0b957f2850f6/executor-1a5e2d48-8f4a-49d0-8feb-3004e69ff544/blockmgr-0e0fe689-38b4-455c-a6a6-5aa3553b10ad
22.
16/02/24 11:33:43 INFO MemoryStore: MemoryStore started with capacity 530.3 MB
23.
16/02/24 11:33:44 INFO CoarseGrainedExecutorBackend: Connecting to driver: akka.tcp://sparkDriver@192.168.13.75:40962/user/CoarseGrainedScheduler
24.
16/02/24 11:33:44 INFO WorkerWatcher: Connecting to worker akka.tcp://sparkWorker@192.168.12.155:42717/user/Worker
25.
16/02/24 11:33:44 INFO WorkerWatcher: Successfully connected to akka.tcp://sparkWorker@192.168.12.155:42717/user/Worker
26.
16/02/24 11:33:44 INFO CoarseGrainedExecutorBackend: Successfully registered with driver
27.
16/02/24 11:33:44 INFO Executor: Starting executor ID 2 on host 192.168.12.155
28.
16/02/24 11:33:44 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 38649.
29.
16/02/24 11:33:44 INFO NettyBlockTransferService: Server created on 38649
30.
16/02/24 11:33:44 INFO BlockManagerMaster: Trying to register BlockManager
31.
16/02/24 11:33:44 INFO BlockManagerMaster: Registered BlockManager
32.
16/02/24 11:33:51 INFO CoarseGrainedExecutorBackend: Got assigned task 1
33.
16/02/24 11:33:51 INFO CoarseGrainedExecutorBackend: Got assigned task 4
34.
16/02/24 11:33:51 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
35.
16/02/24 11:33:51 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
36.
16/02/24 11:33:51 INFO Executor: Fetching http://192.168.13.75:43680/jars/test.jar with timestamp 1456284826060
37.
16/02/24 11:33:52 INFO Utils: Fetching http://192.168.13.75:43680/jars/test.jar to /tmp/spark-8e4d1501-3f08-499f-a748-0b957f2850f6/executor-1a5e2d48-8f4a-49d0-8feb-3004e69ff544/spark-005936a3-4733-4e3a-be4f-a840e2f40adb/fetchFileTemp7968052568997401059.tmp
38.
16/02/24 11:34:41 INFO Utils: Copying /tmp/spark-8e4d1501-3f08-499f-a748-0b957f2850f6/executor-1a5e2d48-8f4a-49d0-8feb-3004e69ff544/spark-005936a3-4733-4e3a-be4f-a840e2f40adb/-3951694191456284826060_cache to /home/supermap/program/spark-1.5.2-bin-hadoop2.6/work/app-20160224113339-0008/2/./test.jar
39.
16/02/24 11:34:41 INFO Executor: Adding file:/home/supermap/program/spark-1.5.2-bin-hadoop2.6/work/app-20160224113339-0008/2/./test.jar to class loader
40.
16/02/24 11:34:42 INFO TorrentBroadcast: Started reading broadcast variable 1
41.
16/02/24 11:34:42 INFO MemoryStore: ensureFreeSpace(2293) called with curMem=0,maxMem=556038881
42.
16/02/24 11:34:42 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.2 KB,free 530.3 MB)
43.
16/02/24 11:34:42 INFO TorrentBroadcast: Reading broadcast variable 1 took 819 ms
44.
16/02/24 11:34:42 INFO MemoryStore: ensureFreeSpace(4056) called with curMem=2293,maxMem=556038881
45.
16/02/24 11:34:42 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.0 KB,free 530.3 MB)
46.
16/02/24 11:34:43 INFO HadoopRDD: Input split: file:/home/sougou.json:134217728+6622843
47.
16/02/24 11:34:43 INFO HadoopRDD: Input split: file:/home/sougou.json:33554432+33554432
48.
16/02/24 11:34:43 INFO TorrentBroadcast: Started reading broadcast variable 0
49.
16/02/24 11:34:43 INFO MemoryStore: ensureFreeSpace(19869) called with curMem=6349,maxMem=556038881
50.
16/02/24 11:34:43 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 19.4 KB,free 530.3 MB)
51.
16/02/24 11:34:43 INFO TorrentBroadcast: Reading broadcast variable 0 took 37 ms
52.
16/02/24 11:34:43 INFO MemoryStore: ensureFreeSpace(314136) called with curMem=26218,maxMem=556038881
53.
16/02/24 11:34:43 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 306.8 KB,free 530.0 MB)
54.
16/02/24 11:34:43 INFO deprecation: mapred.tip.id is deprecated. Instead,use mapreduce.task.id
55.
16/02/24 11:34:43 INFO deprecation: mapred.task.id is deprecated. Instead,use mapreduce.task.attempt.id
56.
16/02/24 11:34:43 INFO deprecation: mapred.task.is.map is deprecated. Instead,use mapreduce.task.ismap
57.
16/02/24 11:34:43 INFO deprecation: mapred.task.partition is deprecated. Instead,use mapreduce.task.partition
58.
16/02/24 11:34:43 INFO deprecation: mapred.job.id is deprecated. Instead,use mapreduce.job.id
59.
16/02/24 11:34:56 INFO Executor: Finished task 4.0 in stage 0.0 (TID 4). 2879 bytes result sent to driver
60.
16/02/24 11:34:59 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 2879 bytes result sent to driver
61.
16/02/24 11:35:17 INFO CoarseGrainedExecutorBackend: Got assigned task 6
62.
16/02/24 11:35:17 INFO Executor: Running task 1.0 in stage 1.0 (TID 6)
63.
16/02/24 11:35:17 INFO CoarseGrainedExecutorBackend: Got assigned task 9
64.
16/02/24 11:35:17 INFO Executor: Running task 4.0 in stage 1.0 (TID 9)
65.
16/02/24 11:35:17 INFO TorrentBroadcast: Started reading broadcast variable 4
66.
16/02/24 11:35:17 INFO MemoryStore: ensureFreeSpace(3595) called with curMem=0,maxMem=556038881
67.
16/02/24 11:35:17 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 3.5 KB,free 530.3 MB)
68.
16/02/24 11:35:17 INFO TorrentBroadcast: Reading broadcast variable 4 took 33 ms
69.
16/02/24 11:35:17 INFO MemoryStore: ensureFreeSpace(6592) called with curMem=3595,maxMem=556038881
70.
16/02/24 11:35:17 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 6.4 KB,free 530.3 MB)
71.
16/02/24 11:35:17 INFO HadoopRDD: Input split: file:/home/sougou.json:134217728+6622843
72.
16/02/24 11:35:17 INFO HadoopRDD: Input split: file:/home/sougou.json:33554432+33554432
73.
16/02/24 11:35:17 INFO TorrentBroadcast: Started reading broadcast variable 3
74.
16/02/24 11:35:17 INFO MemoryStore: ensureFreeSpace(19869) called with curMem=10187,maxMem=556038881
75.
16/02/24 11:35:17 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 19.4 KB,free 530.3 MB)
76.
16/02/24 11:35:17 INFO TorrentBroadcast: Reading broadcast variable 3 took 31 ms
77.
16/02/24 11:35:17 INFO MemoryStore: ensureFreeSpace(314136) called with curMem=30056,maxMem=556038881
78.
16/02/24 11:35:17 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 306.8 KB,free 530.0 MB)
79.
16/02/24 11:35:20 INFO GeneratePredicate: Code generated in 765.978034 ms
80.
16/02/24 11:35:22 INFO Executor: Finished task 4.0 in stage 1.0 (TID 9). 3594 bytes result sent to driver
81.
16/02/24 11:35:25 INFO Executor: Finished task 1.0 in stage 1.0 (TID 6). 4923 bytes result sent to driver
82.
16/02/24 11:35:28 INFO CoarseGrainedExecutorBackend: Driver commanded a shutdown
首先在通过的加密验证之后,先后启动driverPropsFetcher和sparkExecutor服务和端口,基于分配给该节点的调度作业任务来进行计算,从日志中可以看到192.168.12.155节点被分配执行的task有:task 4.0 in stage 0.0 (TID 4)task 1.0 in stage 0.0 (TID 1)task 0.0 in stage 1.0 (TID 5)task 1.0 in stage 1.0 (TID 6)task 4.0 in stage 1.0 (TID 9)这与前面执行程序输出的日志中显示的任务分配是一致的。在worker的执行过程中除了计算以外还有两个关键的操作,一个是获取test.jar文件,然后将该文件拷贝到本地的任务执行目录下,并加载类文件。下面的日志显示了worker已经获取到了test.jar的下载地址
1.
16/02/24 11:33:51 INFO Executor: Fetching http://192.168.13.75:43680/jars/test.jar with timestamp 1456284826060另一个关键的操作是该节点读取了两个数据分片。
1.
16/02/24 11:34:43 INFO HadoopRDD: Input split: file:/home/sougou.json:134217728+6622843
2.
16/02/24 11:34:43 INFO HadoopRDD: Input split: file:/home/sougou.json:33554432+33554432通过以上日志可以看到worker与master创建、分配和执行任务的过程,以及对数据切片的计算,最终将数据结果发送到driver,并汇总形成最终结果。所有的worker都是独立的执行任务,处理分片的数据,通过并行提高了计算的效率。
总结
通过以上的测试我们完成了对SparkSQL的开发、调试、部署、运行的完整过程的实践,并对日志的关键内容进行了分析,体验到了Spark在分布式计算环境下的高性能优势。这里并没有对Spark任务调度的原理做详细介绍,有兴趣的可以查看Spark官方文档或者搜索一些关于作业调度相关的博客来学习了解。最后将几个在开发过程中会遇到的一些问题做个分享。问题1:TaskSchedulerImpl: Initial job has not acceptedany resources;当运行程序时,master在最后反复出现以上的日志而不进行后续操作时,有几个原因可以确认。1. 可能是节点可用的资源不足于分配的资源,比如剩余内存不足。2. 检查Spark-env.sh的配置信息,检查SPARK_MASTER_IP
和 SPARK_LOCAL_IP 是否正确(在个人笔记本开发使用虚拟机如果没有固定ip的话会容易犯此错误)。3. 检查客户端节点的防火墙是否因打开而影响了节点之间的访问。问题2:如何通过程序动态指定Executor Memory的大小。例如:sparkConf.set("spark.executor.memory","800m")问题3:运行程序出现类似java.lang.ClassNotFoundException的错误。在本文的测试程序中,如果出现这个问题,有可能是test.jar的路径写错了,导致worker没有办法通过该路径找到test.jar。

相关文章推荐
- Zookeeper异常:FAILED TO WRITE PID与Permission denied
- Container With Most Water
- AIDL随写
- 高僧斗法--Staircase Nim
- poj 1363 Rails(栈)
- 【bzoj2434】[Noi2011]阿狸的打字机 AC自动机+fail树+dfs序+树状数组
- 欢迎使用CSDN-markdown编辑器
- How Does Caching Work in AFNetworking? : AFImageCache & NSUrlCache Explained
- 中国科学院信息工程研究所招聘研发工程师 /大数据安全分析工程
- 【bzoj3172】[Tjoi2013]单词 AC自动机+fail树
- leetcode笔记:Contains Duplicate II
- 二、大数据生态圈尝鲜
- 模型选择准则之AIC和BIC
- AIDL
- STM32 Keil仿真进不了Main()函数
- leetcode笔记:Contains Duplicate
- if __name__ == '__main__':
- 一、初识大数据
- 如何解决failed to push some refs to git
- 【云计算】qcow2虚拟磁盘映像转化为vmdk