用逻辑回归对用户分类 (理论+实战)
2016-02-14 00:00
417 查看
如果你在运营一个2C的平台,那么你肯定关心用户流失的问题。腾讯有个产品叫信鸽Pro,它能够通过对用户往期行为的挖掘,预测用户潜在的流失(付费)行为,进而实现精准营销。据说,腾讯自己的手游就是用这个系统做用户分析的。
信鸽Pro获取大量用户数据,提取用户特征,然后通过算法建模,评估出用户可能的行为。算法建模中最基础的一步就是对用户进行分类。这里就介绍一种常用的分类算法 - 逻辑回归。

整个平面上只有两种图形,一种是三角形,另一种是圆形。可以把它们想象为两种不同的用户,比如活跃用户/非活跃用户。
问题:如果随意在这个平面新增加一个点, 比如点P(5,19),那怎知把它归到哪一组更合适?可以想象为对新用户的预测。

这个问题似乎很简单。但是,如果三维空间存在类似的问题,答案就没有那么显而易见了。那4维空间呢? 1024维空间呢?
不过别担心!借助计算机算法,N维空间分类的问题已经很容易解决,逻辑回归就是常用的一种。
在介绍算法之前,需要先介绍一个函数: Sigmoid函数。

在坐标系中的图形为:

x>0时,x越大y越接近于1;x<0时,x越小,y越接近于0。如果把坐标拉长,曲线中间就会很“陡”。直观上x的“轻微”变化,都会导致y接近于0或1。

Sigmoid函数的作用是将任意实数转换成0~1的数,而0和1刚好可以用做分类,比如,用1表示三角形,用0表示圆形。小于0.5的可以划分为0类,大于0.5的划分为1类。(注:Sigmoid是单调增长函数,因而多个数字通过Sigmoid转换后相对位置不变,这是选择该函数的重要原因。)

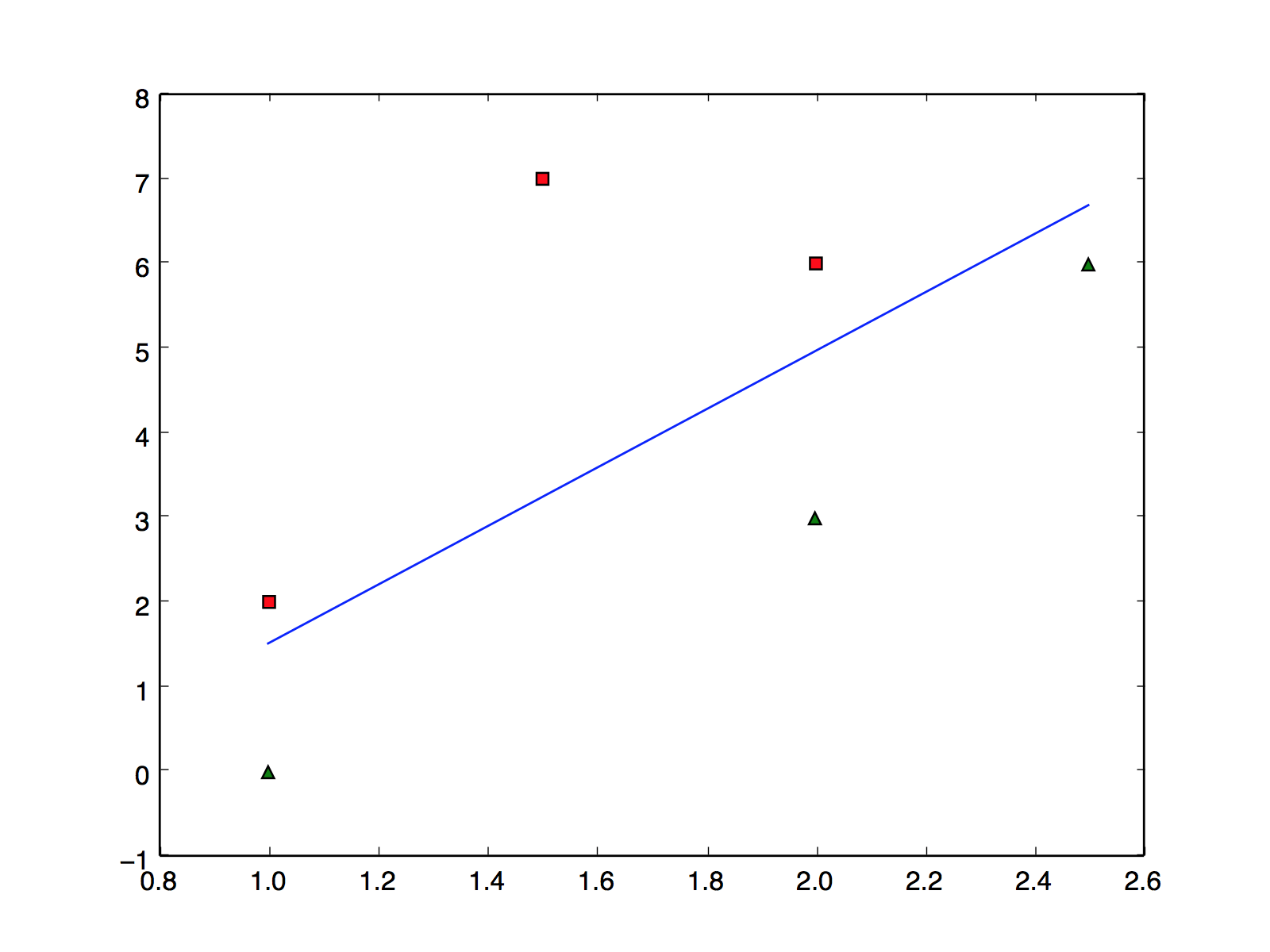
其中红色三角形坐标分别是(1,2)、(1.5,7)和(2,6)。绿色圆点坐标分别是(1,0)、(2,3)和(2.5,6)。分割线的函数为y=4x-3. 它的形式还可以转换成:3-4x+y=0 。
我们设表达式f(x,y) = 3-4x+y
把六个点的坐标代到这个方程式里,有
<表1>

(注:标识1表示三角形;标识0表示圆形)
f(x,y)>0的点在分割线上方,是三角形;f(x,y)<0的点在分割线下方,是圆形.
如果有个三角形的坐标是(2,4.5),那这个点的f(x,y)值等于-0.5,这个点就被分割线错误划分了。

现在的问题是,我们只有一些坐标以及这些坐标的分类信息,如何找到一条最优的分割线,使得尽可能少的点被错误划分?

如果是一个平面来划分三维空间的点,那距离公式为

一般的,n维空间上一个点到超平面的距离为

w是超平面的参数向量,

x是超平面的自变量,

b是截距
超平面函数:


表示x向量的第i个元素(特性);后面会用到

,表示空间中的第i个点。
为了方便计算,一般在x中增加一个元素1,w中增加一个元素w0=b


于是超平面函数变为:

距离公式变为:

超平面上方的点f(x)>0, 下方的点f(x)<0,因此点到超平面的距离(分正负):

d是一个负无穷到正无穷的数。
通过sigmoid函数,将d变成一个0~1的值,设h = sigmoid(d)。若d为正且越大,h越接近于1,也就越应该属于三角形(分类1);若d为负,且绝对值越大,h越接近于0,该点也就越应该属于圆形(分类0)。因此,h越接近于分类标识,划分的准确性越高。
设第j个点的分类表示为

,那么下面的公式就表示点j被错误划分的概率。

我们把损失函数设定为所有点被错误划分的平均概率

平方是为了保证概率为正,前面的1/2是为了求导数后消除参数。
那么,问题转化成:找到w的一个值,使得损失函数的值最小。


如果是曲面,梯度是在两个方向上求偏导。

梯度下降法的核心思想是:欲求函数的最小值,先从某一点出发,沿着函数的梯度的反方向探寻,直到找到最小值。设每次探寻Delta(w),步长为alpha,则梯度下降的算法的公式为:

——— (1)

——— (2)

———- (3)
可以通过复合函数求导法对损失函数求偏导:

梯度公式重点关注的是导数的符号,所以这里可以简化一下。函数(2)是单调递增函数,所以导数是正数,不影响整体导数的符号,可以去除。 公式(3)的分母是正数,也不影响导数的符号,也可以去掉。最后得:

代入梯度下降算法公式得:

1/m为正数,也可用去掉。
Sigmoid函数
梯度下降算法
input ds: 坐标数据; label: 标签
return w: 系数向量, nx1的矩阵
测试
运行结果
也就是说w=(3.1, -5.5, 1.6), 即w0=3.1, w1=-5.5, w2 = 1.6
分割线的表达式为:w0+w1x+w2y=0, 代入w后得 3.1-5.5x+1.6y=0, 即y=3.44x-1.9 。 见下图,该直线正确地将图形划分开。

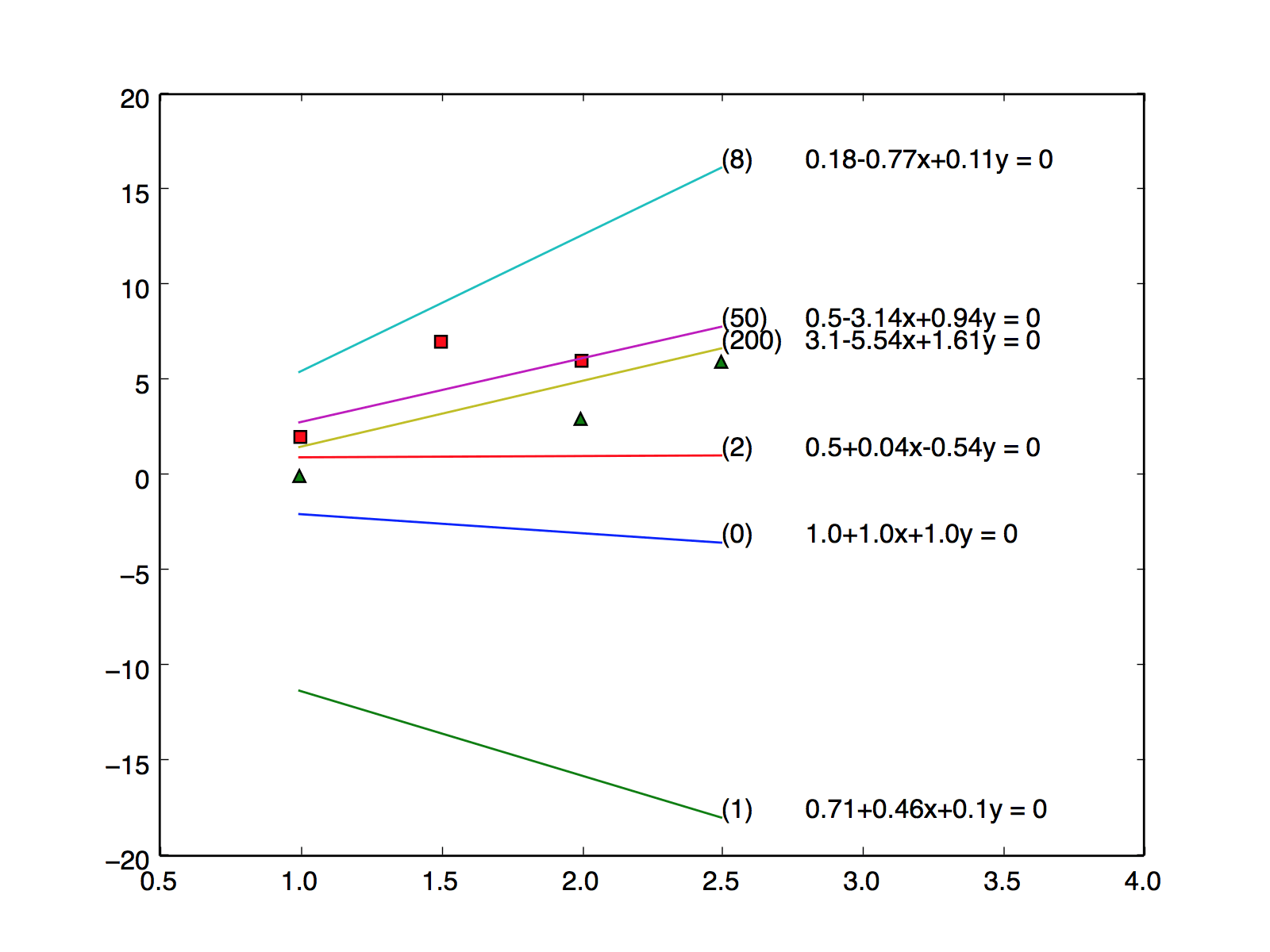
每次循环都会调整分割线的位置,执行到第200次的时候,分割线已经能够很好对坐标分组了。
<分割线调整图> 线编号n表示第n次调整(循环)之后的位置

当然,这只是个理论模型,实际应用要比这复杂的多的多。
相关文章
推荐引擎算法 - 猜你喜欢的东西
TensorFlow学习笔记 -- 安装
TensorFlow学习笔记 --识别圆圈内的点
信鸽Pro获取大量用户数据,提取用户特征,然后通过算法建模,评估出用户可能的行为。算法建模中最基础的一步就是对用户进行分类。这里就介绍一种常用的分类算法 - 逻辑回归。
模型
用户数据比较复杂,这里用平面上的点举例。假设平面上有一些点,如图所示: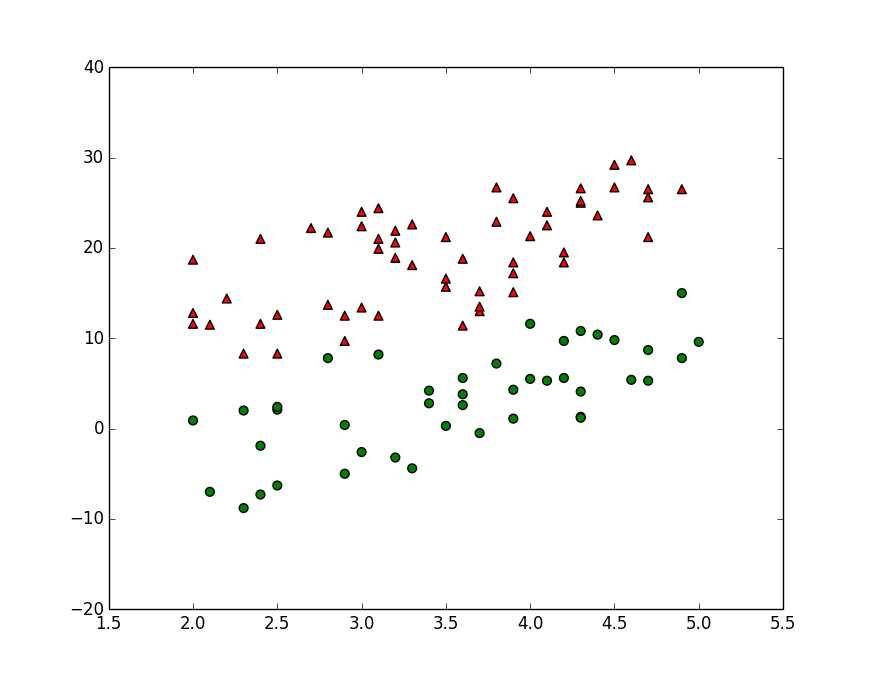
整个平面上只有两种图形,一种是三角形,另一种是圆形。可以把它们想象为两种不同的用户,比如活跃用户/非活跃用户。
问题:如果随意在这个平面新增加一个点, 比如点P(5,19),那怎知把它归到哪一组更合适?可以想象为对新用户的预测。
思路
我们发现,三角形大都位于左上方,而圆形大都位于右下方。我们可以用尺子在图上画一条直线,该直线尽可能的将三角形和圆形分到两边。然后观察新点位于哪一侧。若与三角形在同一侧,则它应该属于三角形;若位于圆形一侧,则应属于圆形。在本例中,坐标P应该属于三角形更合适。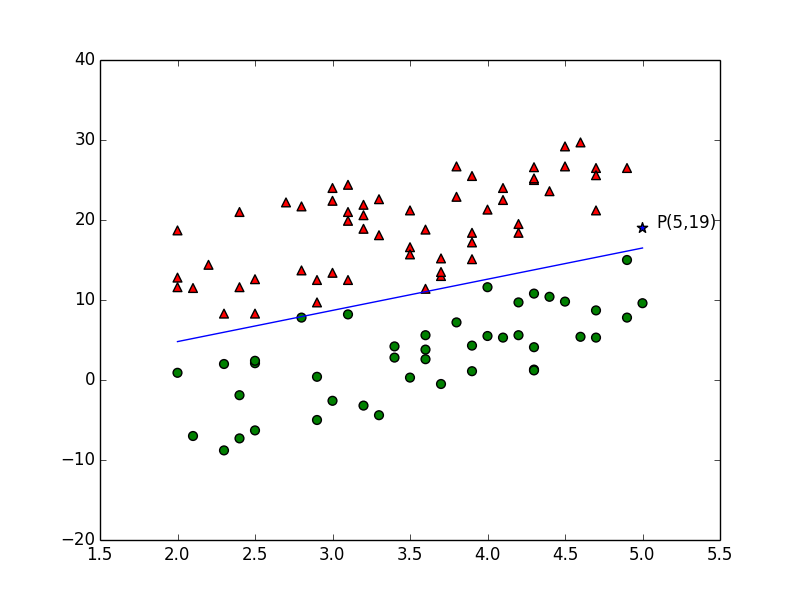
这个问题似乎很简单。但是,如果三维空间存在类似的问题,答案就没有那么显而易见了。那4维空间呢? 1024维空间呢?
不过别担心!借助计算机算法,N维空间分类的问题已经很容易解决,逻辑回归就是常用的一种。
逻辑回归
逻辑回归的核心思想就是通过现有数据,对分类边界线建立回归公式,以此进行分类。在介绍算法之前,需要先介绍一个函数: Sigmoid函数。
Sigmoid函数
Sigmoid函数的表达式为: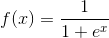
在坐标系中的图形为:
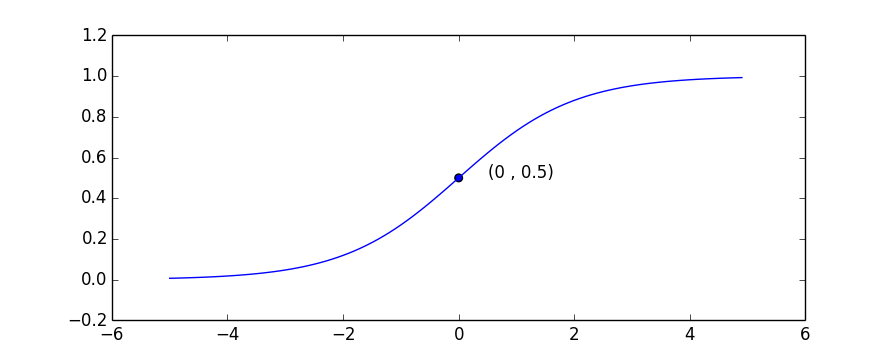
x>0时,x越大y越接近于1;x<0时,x越小,y越接近于0。如果把坐标拉长,曲线中间就会很“陡”。直观上x的“轻微”变化,都会导致y接近于0或1。
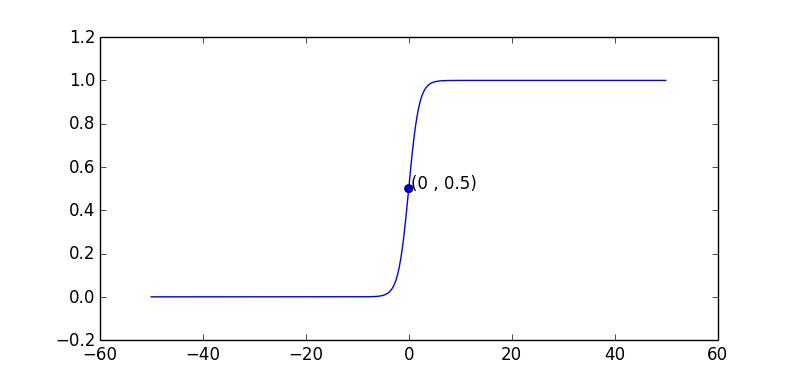
Sigmoid函数的作用是将任意实数转换成0~1的数,而0和1刚好可以用做分类,比如,用1表示三角形,用0表示圆形。小于0.5的可以划分为0类,大于0.5的划分为1类。(注:Sigmoid是单调增长函数,因而多个数字通过Sigmoid转换后相对位置不变,这是选择该函数的重要原因。)
分析步骤
简化模型
为便于分析,把模型中的坐标简化一些。下面的六个坐标点和一条分割线:其中红色三角形坐标分别是(1,2)、(1.5,7)和(2,6)。绿色圆点坐标分别是(1,0)、(2,3)和(2.5,6)。分割线的函数为y=4x-3. 它的形式还可以转换成:3-4x+y=0 。
我们设表达式f(x,y) = 3-4x+y
把六个点的坐标代到这个方程式里,有
<表1>
(注:标识1表示三角形;标识0表示圆形)
f(x,y)>0的点在分割线上方,是三角形;f(x,y)<0的点在分割线下方,是圆形.
如果有个三角形的坐标是(2,4.5),那这个点的f(x,y)值等于-0.5,这个点就被分割线错误划分了。
现在的问题是,我们只有一些坐标以及这些坐标的分类信息,如何找到一条最优的分割线,使得尽可能少的点被错误划分?
损失函数
损失函数 (Loss Function) 的作用是判断直线错误划分数据的程度。一种方法是计算被错误划分的点的个数,错误点越少,直线越好。但,这种方法很难优化。另一种方法是计算点到直线的距离。如果是一个平面来划分三维空间的点,那距离公式为
一般的,n维空间上一个点到超平面的距离为
w是超平面的参数向量,
x是超平面的自变量,
b是截距
超平面函数:
表示x向量的第i个元素(特性);后面会用到
,表示空间中的第i个点。
为了方便计算,一般在x中增加一个元素1,w中增加一个元素w0=b
于是超平面函数变为:
距离公式变为:
超平面上方的点f(x)>0, 下方的点f(x)<0,因此点到超平面的距离(分正负):
d是一个负无穷到正无穷的数。
通过sigmoid函数,将d变成一个0~1的值,设h = sigmoid(d)。若d为正且越大,h越接近于1,也就越应该属于三角形(分类1);若d为负,且绝对值越大,h越接近于0,该点也就越应该属于圆形(分类0)。因此,h越接近于分类标识,划分的准确性越高。
设第j个点的分类表示为
,那么下面的公式就表示点j被错误划分的概率。
我们把损失函数设定为所有点被错误划分的平均概率
平方是为了保证概率为正,前面的1/2是为了求导数后消除参数。
那么,问题转化成:找到w的一个值,使得损失函数的值最小。
用梯度下降法求w
所谓梯度,就是函数在某个点增长最快的方向,有时称为斜度。如果函数是一个曲线,某个点的梯度就是该点的斜率,或导数。如果是曲面,梯度是在两个方向上求偏导。
梯度下降法的核心思想是:欲求函数的最小值,先从某一点出发,沿着函数的梯度的反方向探寻,直到找到最小值。设每次探寻Delta(w),步长为alpha,则梯度下降的算法的公式为:
求导
用梯度下降法需要先对损失函数求导,我们的损失函数被分成三部分:——— (1)
——— (2)
———- (3)
可以通过复合函数求导法对损失函数求偏导:
梯度公式重点关注的是导数的符号,所以这里可以简化一下。函数(2)是单调递增函数,所以导数是正数,不影响整体导数的符号,可以去除。 公式(3)的分母是正数,也不影响导数的符号,也可以去掉。最后得:
代入梯度下降算法公式得:
1/m为正数,也可用去掉。
代码
loadData()函数返回坐标值和分类标识。第一个返回值取前三列 x0,x1,x2;第二个返回值取第四列,即labelfrom numpy import * def loadData(): data = [[1, 1, 2, 1], [1, 2, 6, 1], [1, 1.5, 7, 1], [1, 1, 0, 0], [1, 2, 3, 0], [1, 2.5, 6, 0]] ds = [e[0:3] for e in data] label = [e[-1] for e in data] return ds, label
Sigmoid函数
def sigmoid(x): return 1.0/(1+exp(-x))
梯度下降算法
input ds: 坐标数据; label: 标签
return w: 系数向量, nx1的矩阵
def reduce(ds, label): #转换成矩阵 dmat = mat(ds) lmat = mat(label).T #mxn的矩阵的行数和列数 m,n = shape(dmat) #步长 alpha = 0.1 #循环次数 loops = 200 #初始化w为[1,1,1],即分割线为 1+x+y=0 w = ones((n,1)) for i in range(loops): h = sigmoid(dmat*w) err = (h - lmat) w = w - alpha * dmat.T* err return w.A[:,0]
测试
def test(): ds,l = loadData() print reduce(ds,l)
运行结果
>>> import lr >>> lr.test() [ 3.1007773 -5.54393712 1.60563033]
也就是说w=(3.1, -5.5, 1.6), 即w0=3.1, w1=-5.5, w2 = 1.6
分割线的表达式为:w0+w1x+w2y=0, 代入w后得 3.1-5.5x+1.6y=0, 即y=3.44x-1.9 。 见下图,该直线正确地将图形划分开。
执行过程
w的初始值为(1,1,1),也就是0号线。每次循环都会调整分割线的位置,执行到第200次的时候,分割线已经能够很好对坐标分组了。
<分割线调整图> 线编号n表示第n次调整(循环)之后的位置
应用
把上面的x,y转换成用户特征,比如登录时间,登录频率等等。把三角形和圆形转换成付费用户和免费用户,就得到了付费用户预测模型;把三角形和圆形转换成流失用户和有效用户,就得到了流失用户预测模型。当然,这只是个理论模型,实际应用要比这复杂的多的多。
相关文章
推荐引擎算法 - 猜你喜欢的东西
TensorFlow学习笔记 -- 安装
TensorFlow学习笔记 --识别圆圈内的点

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- 反向传播(Backpropagation)算法的数学原理
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 自动编程体系设想(一)
- 自动编程体系设想(一)
- 支持向量机(SVM)算法概述
- [Ng机器学习公开课1]机器学习概述
- [Ng机器学习公开课2]单变量线性回归
- 神经网络初步学习手记