数学之路(机器学习实践指南)-文本挖掘与NLP(4)
2016-01-29 16:00
295 查看
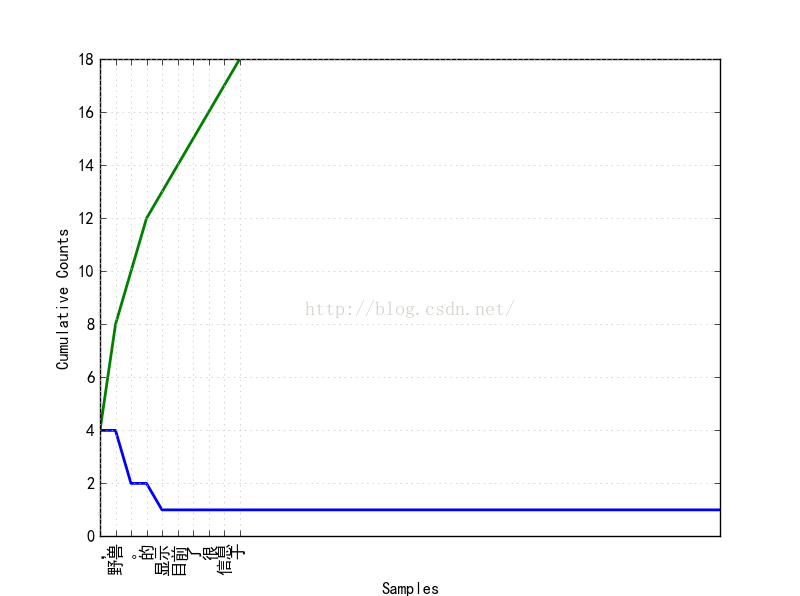
sample=cutstring(u"据悉,这辆汽车绰号野兽,野兽很可能于2017年1月份美国第45任总统就职时使用。目前,野兽的详细规格都属于绝密信息,但谍照显示野兽采用了凯迪拉克的最新护栅和前灯设计。") tokenstr=nltk.word_tokenize(sample) fdist3=nltk.FreqDist(tokenstr) print "---美国出现的次数---" print fdist3[u"美国"] print "---样本总数---" print fdist3.N() print "---数值最大的样本---" print fdist3.max() #频率分布表 fdist3.tabulate() #频率分布图 fdist3.plot() #累积频率分布图 fdist3.plot(10,cumulative=True)
本博客所有内容是原创,如果转载请注明来源
http://blog.csdn.net/myhaspl/

相关文章推荐
- 未知来源应用禁止/允许开关
- bitscount函数的重写
- viewFlipper小页面的滑动效果
- apk反编译
- 四:动画技术一
- Mac添加环境变量
- iOS--新建工程需知
- ASP.NET Web API 官方教学视频
- 2套RAC容灾切换+更改容灾RAC的虚拟ip和scan-ip
- 被脱裤也不怕,密码安全可以这样保障
- JavaScript内置对象
- Android实现AppWidget、Broadcast静态注册
- Python正则表达式中的re.S
- python requests 模块学习
- 【oracle概念】表联结方式
- nchar and nvarchar (Transact-SQL)(nchar 和nvarchar说明)
- Ubuntu安装iSCSI HBA
- .gitignore 与 Change-Id 的生成
- 手机App测试总结
- 使用phpexecel类库导出数据