局部敏感哈希
2016-01-21 22:47
204 查看
局部敏感哈希
在检索技术中,索引一直需要研究的核心技术。当下,索引技术主要分为三类:基于树的索引技术(tree-based index)、基于哈希的索引技术(hashing-based index)与基于词的倒排索引(visual words based inverted index)[1]。本文主要对哈希索引技术进行介绍。
哈希技术概述
在检索中,需要解决的问题是给定一个查询样本query,返回与此query相似的样本,线性搜索耗时耗力,不能承担此等重任,要想快速找到结果,必须有一种方法可以将搜索空间控制到一个可以接受的范围,哈希在检索中就是承担这样的任务,因而,这些哈希方法一般都是局部敏感(Locality-sensitive)的,即样本越相似,经过哈希后的值越有可能一样。所以,本文中介绍的技术都是局部敏感哈希(Locality Sensitive Hashing,LSH),与hashmap、hashtable等数据结构中的哈希函数有所不同。
哈希技术分类

图 1 LSH分层法使用
对于哈希技术,可以按照不同的维度对齐进行划分。
按照其在检索技术中的应用方法来划分,可以分为分层法和哈希码法:
分层法即为在数据查询过程中使用哈希技术在中间添加一层,将数据划分到桶中;在查询时,先对query计算桶标号,找到与query处于同一个桶的所有样本,然后按照样本之间的相似度计算方法(比如欧氏距离、余弦距离等)使用原始数据计算相似度,按照相似度的顺序返回结果,在该方法中,通常是一组或一个哈希函数形成一个表,表内有若干个桶,可以使用多个表来提高查询的准确率,但通常这是以时间为代价的。分层法的示意图如图1所示。在图1中,H1、H2等代表哈希表,g1、g2等代表哈希映射函数。
分层法的代表算法为E2LSH[2]。
哈希码法则是使用哈希码来代替原始数据进行存储,在分层法中,原始数据仍然需要以在第二层被用来计算相似度,而哈希码法不需要,它使用LSH函数直接将原始数据转换为哈希码,在计算相似度的时候使用hamming距离来衡量。转换为哈希码之后的相似度计算非常之快,比如,可以使用64bit整数来存储哈希码,计算相似度只要使用同或操作就可以得到,唰唰唰,非常之快,忍不住用拟声词来表达我对这种速度的难言之喜,还望各位读者海涵。
哈希码法的代表算法有很多,比如KLSH[3]、Semantic Hashing[4]、KSH[5]等。
以我看来,两者的区别在于如下几点:
在对哈希函数的要求上,哈希码方法对哈希函数的要求更高,因为在分层法中,即便哈希没有计算的精确,后面还有原始数据直接计算相似度来保底,得到的结果总不会太差,而哈希码没有后备保底的,胜则胜败则败。
在查询的时间复杂度上,分层法的时间复杂度主要在找到桶后的样本原始数据之间的相似度计算,而哈希码则主要在query的哈希码与所有样本的哈希码之间的hamming距离的相似计算。哈希码法没有太多其他的需要,但分层法中的各个桶之间相对较均衡方能使复杂度降到最低。按照我的经验,在100W的5000维数据中,KSH比E2LSH要快一个数量级。
在哈希函数的使用上,两者使用的哈希函数往往可以互通,E2LSH使用的p-stable LSH函数可以用到哈希码方法上,而KSH等哈希方法也可以用到分层法上去。
上述的区别分析是我自己分析的,如果有其他意见欢迎讨论。
按照哈希函数来划分,可以分为无监督和有监督两种:
无监督,哈希函数是基于某种概率理论的,可以达到局部敏感效果。如E2LSH等。
有监督,哈希函数是从数据中学习出来的,如KSH、Semantic Hashing等。
一般来说,有监督算法比无监督算法更加精确,因而也更常用于哈希码法中。
本文中,主要对无监督的哈希算法进行介绍。
Origin LSH
最原始的LSH算法是1999年提出来的[6]。在本文中称之为Origin LSH。
Embedding
Origin LSH在哈希之前,首先要先将数据从L1准则下的欧几里得空间嵌入到Hamming空间。在做此embedding时,有一个假设就是原始点在L1准则下的效果与在L2准则下的效果相差不大,即欧氏距离和曼哈顿距离的差别不大,因为L2准则下的欧几里得空间没有直接的方法嵌入到hamming空间。| 12 | Embedding算法如下: |
对于一个点P来说,P=(x1,x2,…,xd),d是数据的维度;
将每一维xi转换为一个长度为C的0/1序列,其中序列的前xi个值为1,剩余的为0.
然后将d个长度为C的序列连接起来,形成一个长度为Cd的序列.
这就是embedding方法。注意,在实际运算过程中,通过一些策略可以无需将embedding值预先计算出来。
Algorithm of Origin LSH
在Origin LSH中,每个哈希函数的定义如下:
即输入是一个01序列,输出是该序列中的某一位上的值。于是,hash函数簇内就有Cd个函数。在将数据映射到桶中时,选择k个上述哈希函数,组成一个哈希映射,如下:

| 1 2 | 再细化,LSH的算法步骤如下: |
对于一个向量P,得到一个L维哈希值,即P|G,其中L维中的每一维都对应一个哈希函数h。
由于直接以上步中得到的L维哈希值做桶标号不方便,因而再进行第二步哈希,第二步哈希就是普通的哈希,将一个向量映射成一个实数。

其中,a是从[0,M-1]中随机抽选的数字。
这样,就把一个向量映射到一个桶中了。
LSH based on p-stable distribution
该方法由[2]提出,E2LSH[7]是它的一种实现。
p-stable分布
定义:对于一个实数集R上的分布D,如果存在P>=0,对任何n个实数v1,…,vn和n个满足D分布的变量X1,…,Xn,随机变量ΣiviXi和(∑i|vi|p)(1/p)X有相同的分布,其中X是服从D分布的一个随机变量,则称D为一个p稳定分布。对任何p∈(0,2]存在稳定分布。P=1时是柯西分布;p=2时是高斯分布。
当p=2时,两个向量v1和v2的映射距离a·v1-a·v2和||v1-v2||pX的分布是一样的,此时对应的距离计算方式为欧式距离。
利用p-stable分布可以有效的近似高维特征向量,并在保证度量距离的同时,对高维特征向量进行降维,其关键思想是,产生一个d维的随机向量a,随机向量a中的每一维随机的、独立的从p-stable分布中产生。对于一个d维的特征向量v,如定义,随机变量a·v具有和(∑i|vi|p)(1/p)X一样的分布,因此可以用a·v表示向量v来估算||v||p。
E2LSH
基于p-stable分布,并以‘哈希技术分类’中的分层法为使用方法,就产生了E2LSH算法。E2LSH中的哈希函数定义如下:

其中,v为d维原始数据,a为随机变量,由正态分布产生; w为宽度值,因为a∙v+b得到的是一个实数,如果不加以处理,那么起不到桶的效果,w是E2LSH中最重要的参数,调得过大,数据就被划分到一个桶中去了,过小就起不到局部敏感的效果。b使用均匀分布随机产生,均匀分布的范围在[0,w]。
与Origin LSH类似,选取k个上述的哈希函数,组成一个哈希映射,效果如图2所示:

图 2 E2LSH映射
但是这样,得到的结果是(N1,N2,…,Nk),其中N1,N2,…,Nk在整数域而不是只有0,1两个值,这样的k元组就代表一个桶。但将k元组直接当做桶标号存入哈希表,占用内存且不便于查找,为了方便存储,设计者又将其分层,使用数组+链表的方式,如图3所示:

图 3 E2LSH为存储桶标号而产生的数组+链表二层结构
对每个形式为k元组的桶标号,使用如下h1函数和h2函数计算得到两个值,其中h1的结果是数组中的位置,数组的大小也相当于哈希表的大小,h2的结果值作为k元组的代表,链接到对应数组的h1位置上的链表中。在下面的公式中,r’为[0,prime-1]中依据均匀分布随机产生。


| 1 2 | 经过上述组织后,查询过程如下: |
使用k个哈希函数计算桶标号的k元组;
对k元组计算h1和h2值,
获取哈希表的h1位置的链表,
在链表中查找h2值,
获取h2值位置上存储的样本
Query与上述样本计算精确的相似度,并排序
按照顺序返回结果。
E2LSH方法存在两方面的不足[8]:首先是典型的基于概率模型生成索引编码的结果并不稳定。虽然编码位数增加,但是查询准确率的提高确十分缓慢;其次是需要大量的存储空间,不适合于大规模数据的索引。E2LSH方法的目标是保证查询结果的准确率和查全率,并不关注索引结构需要的存储空间的大小。E2LSH使用多个索引空间以及多次哈希表查询,生成的索引文件的大小是原始数据大小的数十倍甚至数百倍。
Hashcode of p-stable distribution
E2LSH可以说是分层法基于p-stable distribution的应用。另一种当然是转换成hashcode,则定义哈希函数如下:
其中,a和v都是d维向量,a由正态分布产生。同上,选择k个上述的哈希函数,得到一个k位的hamming码,按照”哈希技术分类”中描述的技术即可使用该算法。
Reference
[1]. Ai L, Yu J, He Y, et al. High-dimensional indexing technologies for large scale content-based image retrieval: a review[J]. Journal of Zhejiang University SCIENCE C, 2013, 14(7): 505-520.[2]. Datar M, Immorlica N, Indyk P, et al. Locality-sensitive hashing scheme based on p-stable distributions[C]//Proceedings of the twentieth annual symposium on Computational geometry. ACM, 2004: 253-262.
[3]. Kulis B, Grauman K. Kernelized locality-sensitive hashing[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2012, 34(6): 1092-1104.
[4]. Salakhutdinov R, Hinton G. Semantic hashing[J]. International Journal of Approximate Reasoning, 2009, 50(7): 969-978.
[5]. Liu W, Wang J, Ji R, et al. Supervised hashing with kernels[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 2074-2081.
[6]. Gionis A, Indyk P, Motwani R. Similarity search in high dimensions via hashing[C]//VLDB. 1999, 99: 518-529.
[7]. http://web.mit.edu/andoni/www/LSH/
[8]. http://blog.csdn.net/jasonding1354/article/details/38237353
文章出处:http://blog.csdn.net/stdcoutzyx/article/details/44456679
位置敏感哈希(Locality Sensitive Hashing,LSH)是近似最近邻搜索算法中最流行的一种,它有坚实的理论依据并且在高维数据空间中表现优异。由于网络上相关知识的介绍比较单一,现就LSH的相关算法和技术做一介绍总结,希望能给感兴趣的朋友提供便利,也希望有兴趣的同道中人多交流、多指正。
1、LSH原理
最近邻问题(nearest neighbor problem)可以定义如下:给定n个对象的集合并建立一个数据结构,当给定任意的要查询对象时,该数据结构返回针对查询对象的最相似的数据集对象。LSH的基本思想是利用多个哈希函数把高维空间中的向量映射到低维空间,利用低维空间的编码来表示高维向量。通过对向量对象进行多次哈希映射,高维向量按照其分布以及自身的特性落入不同哈希表的不同桶中。在理想情况下可以认为在高维空间中位置比较接近的向量对象有很大的概率最终落入同一个桶中,而距离比较远的对象则以很大的概率落入不同的桶中。因此在查询的时候,通过对查询向量进行同样的多次哈希操作,综合多个哈希表中的查询操作得到最终的结果。
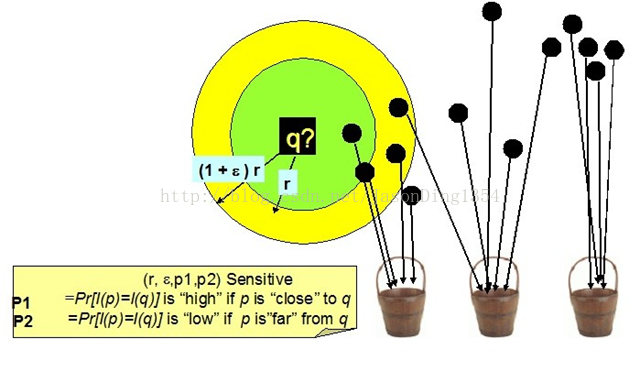
图1 LSH哈希桶演示
使用哈希函数对整个数据集进行过滤,得到可能满足查询条件的点再计算距离,这样就避免了查询点与数据集中所有点进行距离计算,提高了查询效率。该框架可以被称为过滤-验证框架。
2、LSH函数族定义
为了形式化地描述LSH使用的哈希函数的性质,现定义LSH函数族概念。
令S为d维数据点的数据域,D为相似性度量函数,p和q为S中任意两点。函数族H={h:S->U}被称为(r1,r2,p1,p2)-敏感的,当且仅当:

通过使用LSH函数族中函数进行哈希,可以保证距离近的点冲突的概率大于距离远的点冲突的概率。
3、通用的LSH算法框架
(1)构建LSH索引(哈希过程,Hashing)
定义一个函数族G={g:S->U},其中g(v)=(h1(v),...,hk(v)),hi∈H,独立随机地从G中选择L个哈希函数g1,...,gL。对于数据集中任意一点v,将其存储到桶gi(v)中,i=1,...,L。
这种算法是完全索引算法(full-indexing algorithms),它为每个可能的查询点提供一个查询表,因此,响应一个查询点,该算法只需在特殊构造的哈希表中进行一次查询(look-up)。
(2)LSH搜索算法
对于一个查询点q以及给定的距离阈值r,搜索桶g1(q),...,gL(q),取出其中的所有点v1,...,vn作为候选近似最近邻点。对于任意的vj,如果D(q,vj)<=r,那么返回vj,其中D为相似性度量函数。
在创建LSH索引时,选取的哈希函数是k个LSH函数的串联函数,这样就相对拉大了距离近的点冲突的概率pn与距离远的点冲突的概率pf之间的差值,但这同时也使这两个值一起减小了,于是需要同时使用L张哈希表来加大pn同时减小pf。通过这样的构造过程,在查询时,与查询点q距离近的点就有很大的概率被取出作为候选近似最近邻点并进行最后的距离计算,而与查询点q距离远的点被当作候选近似最近邻点的概率则很小,从而能够在很短的时间内完成查询。
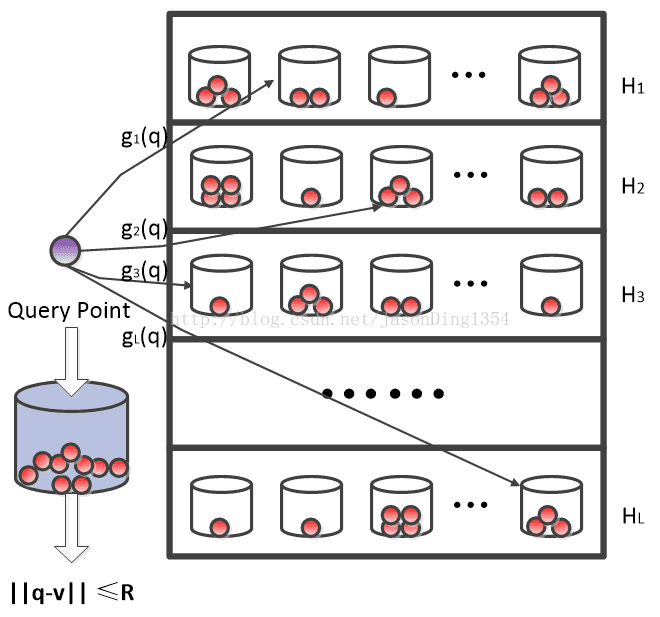
图2 通用LSH策略示意图
转载请注明作者及文章出处:http://blog.csdn.net/jasonding1354/article/details/38227085
参考资料:
1、陈永健.基于内容的大规模图像检索关键技术研究[D].华中科技大学.2011
2、凌康.基于位置敏感哈希的相似性搜索技术研究[D].南京大学.2012
上一节,我们分析了LSH算法的通用框架,主要是建立索引结构和查询近似最近邻。这一小节,我们从p稳定分布LSH(p-Stable LSH)入手,逐渐深入学习LSH的精髓,进而灵活应用到解决大规模数据的检索问题上。
对应海明距离的LSH称为位采样算法(bit sampling),该算法是比较得到的哈希值的海明距离,但是一般距离都是用欧式距离进行度量的,将欧式距离映射到海明空间再比较其的海明距离比较麻烦。于是,研究者提出了基于p-稳定分布的位置敏感哈希算法,可以直接处理欧式距离,并解决(R,c)-近邻问题。
1、p-Stable分布
定义:对于一个实数集R上的分布D,如果存在P>=0,对任何n个实数v1,…,vn和n个满足D分布的变量X1,…,Xn,随机变量ΣiviXi和(Σi|vi|p)1/pX有相同的分布,其中X是服从D分布的一个随机变量,则称D为
一个p稳定分布。
对任何p∈(0,2]存在稳定分布:
p=1是柯西分布,概率密度函数为c(x)=1/[π(1+x2)];
p=2时是高斯分布,概率密度函数为g(x)=1/(2π)1/2*e-x^2/2。
利用p-stable分布可以有效的近似高维特征向量,并在保证度量距离的同时,对高维特征向量进行降维,其关键思想是,产生一个d维的随机向量a,随机向量a中的每一维随机的、独立的从p-stable分布中产生。对于一个d维的特征向量v,如定义,随机变量a·v具有和(Σi|vi|p)1/pX一样的分布,因此可以用a·v表示向量v来估算||v||p 。
2、p-Stable分布LSH中的哈希函数
p-Stable分布的LSH利用p-Stable的思想,使用它对每一个特征向量v赋予一个哈希值。该哈希函数是局部敏感的,因此如果v1和v2距离很近,它们的哈希值将相同,并被哈希到同一个桶中的概率会很大。
根据p-Stable分布,两个向量v1和v2的映射距离a·v1-a·v2和||v1-v2||pX 的分布是一样的。
a·v将特征向量v映射到实数集R,如果将实轴以宽度w等分,并对每一段进行标号,则a·v落到那个区间,就将此区间标号作为哈希值赋给它,这种方法构造的哈希函数对于两个向量之间的距离具有局部保护作用。
哈希函数格式定义如下:
ha,b(v):Rd->N,映射一个d维特征向量v到一个整数集。哈希函数中又两个随机变量a和b,其中a为一个d维向量,每一维是一个独立选自满足p-Stable的随机变量,b为[0,w]范围内的随机数,对于一个固定的a,b,则哈希函数ha,b(v)为
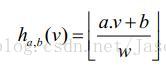
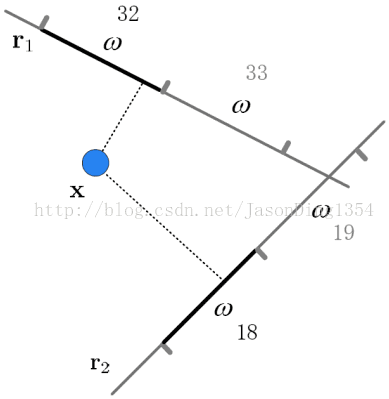
图1 p-Stable LSH在二维空间的示例
3、特征向量碰撞概率
随机选取一个哈希函数ha,b(v),则特征向量v1和v2落在同一桶中的概率该如何计算呢?
首先定义c=||v1-v2||p,fp(t)为p-Stable分布的概率密度函数的绝对值,那么特征向量v1和v2映射到一个随机向量a上的距离是|a·v1-a·v2|<w,即|(v1-v2)·a|<w,根据p-Stable分布的特性,||v1-v2||pX=|cX|<w,其中随机变量X满足p-Stable分布。
可得其碰撞概率p(c):
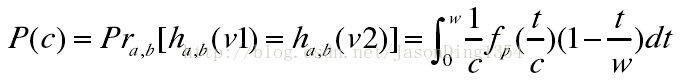
根据该式,可以得出两个特征向量的冲突碰撞概率随着距离c的增加而减小。
4、p-Stable分布LSH的相似性搜索算法
经过哈希函数哈希之后,g(v)=(h1(v),...,hk(v)),但将(h1(v),...,hk(v))直接存入哈希表,即占用内存,又不便于查找,为解决此问题,现定义另外两个哈希函数:

由于每一个哈希桶(Hash Buckets)gi被映射成Zk,函数h1是普通哈希策略的哈希函数,函数h2用来确定链表中的哈希桶。
(1)要在一个链表中存储一个哈希桶gi(v)=(x1,...,xk)时,实际上存的仅仅是h2(x1,...,xk)构造的指纹,而不是存储向量(x1,...,xk),因此一个哈希桶gi(v)=(x1,...,xk)在链表中的相关信息仅有标识(identifier)指纹h2(x1,...,xk)和桶中的原始数据点。
(2)利用哈希函数h2,而不是存储gi(v)=(x1,...,xk)的值有两个原因:首先,用h2(x1,...,xk)构造的指纹可以大大减少哈希桶的存储空间;其次,利用指纹值可以更快的检索哈希表中哈希桶。通过选取一个足够大的值以很大的概率来保证任意在一个链表的两个不同的哈希桶有不同的h2指纹值。
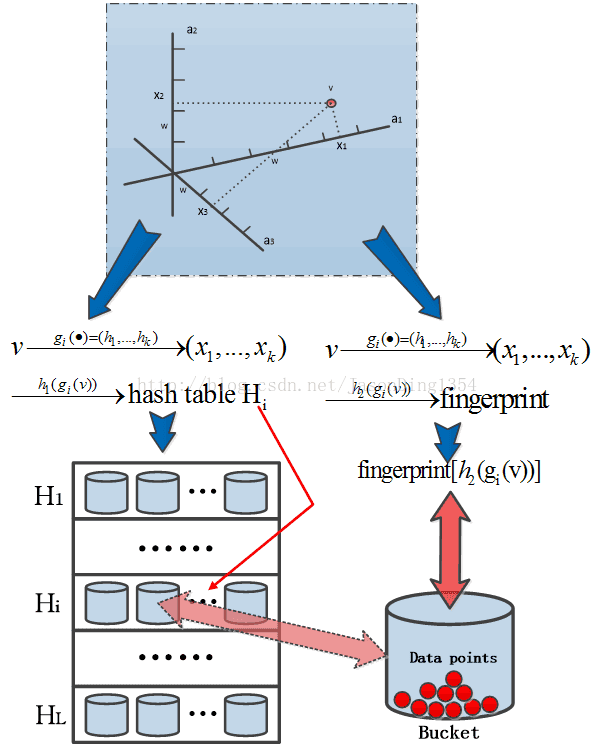
图2 桶哈希策略示意图
5、不足与缺陷
LSH方法存在两方面的不足:首先是典型的基于概率模型生成索引编码的结果并不稳定。虽然编码位数增加,但是查询准确率的提高确十分缓慢;其次是需要大量的存储空间,不适合于大规模数据的索引。E2LSH方法的目标是保证查询结果的准确率和查全率,并不关注索引结构需要的存储空间的大小。E2LSH使用多个索引空间以及多次哈希表查询,生成的索引文件的大小是原始数据大小的数十倍甚至数百倍。
转载请注明作者及文章出处:http://blog.csdn.net/jasonding1354/article/details/38237353
参考资料:
1、王旭乐.基于内容的图像检索系统中高维索引技术的研究[D].华中科技大学.2008
2、M.Datar,N.Immorlica,P.Indyk,and V.Mirrokni,“Locality-SensitiveHashing Scheme Based on p-Stable Distributions,”Proc.Symp. ComputationalGeometry, 2004.
3、A.Andoni,“Nearest Neighbor Search:The Old, theNew, and the Impossible”PhD dissertation,MIT,2009.
4、A.Andoni,P.Indyk.E2lsh:Exact Euclidean locality-sensitive hashing.http://web.mit.edu/andoni/www/LSH/.2004.
搜集了快一个月的资料,虽然不完全懂,但还是先慢慢写着吧,说不定就有思路了呢。
开源的最大好处是会让作者对脏乱臭的代码有羞耻感。
当一个做推荐系统的部门开始重视【数据清理,数据标柱,效果评测,数据统计,数据分析】这些所谓的脏活累活,这样的推荐系统才会有救。
求教GitHub的使用。
简单不等于傻逼。
我为什么说累:我又是一个习惯在聊天中思考前因后果的人,所以整个大脑高负荷运转。不过这样真不好,学习学成傻逼了。
研一的最大收获是让我明白原来以前仰慕的各种国家自然基金项目,原来都是可以浑水摸鱼忽悠过去的,效率不高不说,还有可能有很多错误,哎,我就不说了。
一、问题来源
查找LSH发现的,这个是谷歌现在的网页去重方案。但是simHash和LSH有什么联系呢?提前透漏下,simHash本质上是一种LSH。正因为它的局部敏感性(这段的局部敏感性指的是非常相似的文本,即便只差一个字符,md5后的序列也可能非常不同,但是simHash之后的序列可能只是某几位不同),所以我们可以使用海明距离来衡量simhash值的相似度。simhash是google用来处理海量文本去重的算法。google出品,你懂的。simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
谷歌出品嘛,简单实用。
二、算法解析
2.1 算法伪代码
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。

2.2 simHash和传统哈希的区别
大家可能会有疑问,经过这么多步骤搞这么麻烦,不就是为了得到个 0 1 字符串吗?我直接把这个文本作为字符串输入,用hash函数生成 0 1 值更简单。其实不是这样的,传统hash函数解决的是生成唯一值,比如 md5、hashmap等。md5是用于生成唯一签名串,只要稍微多加一个字符md5的两个数字看起来相差甚远;hashmap也是用于键值对查找,便于快速插入和查找的数据结构。不过我们主要解决的是文本相似度计算,要比较的是两个文章是否相识,当然我们降维生成了hashcode也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成01 串也还是可以用于计算相似度的,而传统的hashcode却不行。我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过 hashcode计算为:
1111111111111111111111111111111110001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出来,相似的文本只有部分 01 串变化了,而普通的hashcode却不能做到,这个就是局部敏感哈希的魅力。目前Broder提出的shingling算法和Charikar的simhash算法应该算是业界公认比较好的算法。
在simhash的发明人Charikar的论文中并没有给出具体的simhash算法和证明,“量子图灵”得出的证明simhash是由随机超平面hash算法演变而来的。
现在通过这样的转换,我们把库里的文本都转换为simhash 代码,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?难道是比较两simhash的01有多少个不同吗?对的,其实也就是这样,我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下:
10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
simhash和普通hash最大的不同在于传统的hash函数虽然也可以用于映射来比较文本的重复,但是对于可能差距只有一个字节的文档也会映射成两个完全不同的哈希结果,而simhash对相似的文本的哈希映射结果也相似。
http://www.lanceyan.com/tech/arch/simhash_hamming_distance_similarity.html
http://blog.sina.com.cn/s/blog_81e6c30b0101cpvu.html
权重该如何指派呢?我只知道用TF-IDF算法。
三、算法实现
谁有容易理解的java或者matlab代码,可以发短消息给我,一起为大家服务。
四、对比其他去重算法
4.1 百度
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。百度的去重算法没有这么傻瓜吧?据一个百度凤巢出来的同事是这么说的。而且我个人觉得简单不等于傻逼。
4.2 shingle算法
shingle原理略复杂,不细说。 shingle算法我认为过于学院派,对于工程实现不够友好,速度太慢,基本上无法处理海量数据。
五、问题扩展
问题:一个80亿的64-bit指纹组成的集合Q,对于一个给定64-bit的指纹F,如何在a few millionseconds中找到Q中和f至多只有k(k=3)位差别的指纹。看文献吧。
我想的是能否借鉴AC自动机一类的算法,来做匹配,只不过匹配规则是海明距离小于3。我说的是优化后的精确匹配了。
http://grunt1223.iteye.com/blog/964564
http://blog.csdn.net/lgnlgn/article/details/6008498
http://blog.sina.com.cn/s/blog_81e6c30b0101cpvu.html
六、意外收获
1.python的计算能力确实很强,float可以表示任意长度的数字,而对应java、c++只能用其他办法来实现了,比如java的BigIneteger,对应的位操作也只能利用类方法。。。汗。。。另外说明,位运算只适合整数哦。。。因为浮点的存储方案决定不能位运算,如果非要位运算,就需要Float.floatToIntBits,运算完,再通过Float.intBitsToFloat转化回去。(java默认的float,double的hashcode其实就是对应的floatToIntBits的int值)。
2.百度竞价排名系统:凤巢系统
3.大神关于就业读研的感触:http://yanyiwu.com/life/2014/10/11/choices-change-my-life.html
七、编者注
参考文献是混合交叉的,也就是说,在第1中的参考文献也可能在第2中引用了,但是第2中未作标注。为什么这么些呢?若是以前把所有的参考文献直接放在最后,这样很不方便日后的查找,不过博客园又不想word那样引用方便,所以就取巧了。以后的博文,未作生命的也按词处理。
LSH local sensitive hash,来自于 mining of massive datasets
包括lsh的详细介绍以及针对不同距离函数的LSH。
作用:
解决的问题:相似性计算,避免两两计算,提供一组Hash函数,将相似的pair放在一个bucket里面,降低计算规模。
约束:
Hash函数的要求:
1.相似的pair比不相似的paire更容易成为candidate
2.识别candidate paire的效率要比从所有pair中识别candidate pair效率高(利用minhash)
3.combinable 技术可以更好的降低false positive/negative
4.combinable 技术识别candidate pair时间更少
Local sensitive hash function: 是一组hash函数F, 如果f(x) = f(y),说明x,y是candiadte pair。 如果f(x) != f(y),x,y不是candidate pair。
LSH函数集合将原始的特征规模降低为|F|,也就是Hash函数的个数。
LSH需要符合如下约束,d是距离度量函数,d1 < d2, p1 > p2:
if d(x,y) <= d1, p(f(x) = f(y)) >= p1
if d(x,y) >= d2, p(fx) = f(y)) <= p2
则称为(d1,d2,p1,p2)-sensitive
这两个约束说明两个问题:
1.如果x,y的距离小于d1, x,y成为candidate pair的概率要最小为 p1,尽量保证距离小的以大概率成为pair。
2.如果x,y的距离大于d2,x,y成为candidate pair概率最大伪p2, 保证距离大的以极小的概率成为pair。
这就要求,随着距离正大,成为pair的概率要降低,符合常识。
我理解d1,d2的约束是为了概念更严格,因为有的时候d1<d2,p1 不一定大于p2(欧氏距离),加上d1,d2的约束,在dx ~[0,d1], dy~[d2,无穷]这两个集合里,dx < dy,p1>p2一定成立
combining tech:
LSH提供hash function,保证candidate pair能在一起,而 combine 技术可以更好的延伸这个概念
combine技术有两种: and-construct or-constrauct,其实也就是band tech.
F为lsh集合, F'是针对F进行combile技术结果:
and-construct:将F中r个hash 函数作为一组,保证fi(x)=fi(y), i=1,2...r,也就是r个hash值都相等才算相等,显然限制更加严格 (d1,d2,p1^r, p2^r) p1^r < p1,进一步降低candidate pair的个数
or-construct :将F中r和hash函数作为一组,保证fi(x)=fi(y)中有一个为真则为真,i=1,2...r,限制变少(d1,d2,1-(1-p1)^r, 1-(1-p2)^r),也就是(1-p1)^r表示都不想等的概率。
两者结合起来,1-(1-p1^r)^m, r*m=hash函数个数
之前的博文中也提到了类这样的技术,min-hash 和banding技术的集合:
先利用and-construct,保证只有极其相似hash值相同概率才高,降低candidate pair的规模,然后利用 or-construct技术,保证整体上相似的pair至少在某个band里面成为candidate pair
整体来讲,LSH 就是基于距离度量函数提供一组hash函数,满足上面提到的约束,保证越相似的pair hash值相同的概率越高,能够成为candidate pair,同一hash值里面的元素少,降低整体的计算规模,同时利用and/or-construct,一方面降低计算规模,另一方面保证lsh的整体召回率,也就是相似pair至少会在某个band里面成为candidate pair。
LSH for different distance measure:
目前的问题是针对不同的距离度量函数,提供不同local sensitive hash函数,符合上面的条件
1.jaccard 距离,见 http://blog.csdn.net/hxxiaopei/article/details/7977248
jaccard的距离的LSH之前已经说过不再具体介绍,min-hash
2.哈明距离
计算x,y里面不同bit的个数。
这个也很简单,hash函数集合F中,fi(x) = xi即可。
其实这个和simhash的后续处理一致
3.cosin 相似性
jaccard/哈名距离 主要是基于特征字面值进行处理,相等或者不相等。而cosin计算的是夹角,而非计算两个向量里相同元素的个数。
比如[1,2,3,4,5][10,20,30,40,50]的cosin值为1,夹角为0。
假定d(x,y)表示向量x,y的相似性,对应cos中的夹角theta.
LSH函数这样定义:假定x,y的特征维数为N,random的选择K个N维度向量V={v1,v2...vk}
定义 d(v1,x)表示v1,x的夹角,基于V,定义LSH集合 F={f1,f2...fk},其中 fi(x)=sign, sign= {-1,+1},如果x与vi的夹角>90,sign=-1; 如果x与vi的夹角<=90,则sign = -1;
基于F的定义,
d(x,y)=0,表示两个x,y相等,则无论V取值如何fi(x) =fi(y)的概率p = 1.
d(x,y)=pi/2,表示x,y夹角为90度,则fi(x)=fi(y)的概率为1-pi/(2*pi) = 1-0.5=0.5
d(x,y)=pi,表示x,y的夹角为180,则fi(x)=fi(y)的概率为0
上面是三个比较特殊的夹角,针对normal的d(x,y),则有:
fi(x)=fi(y)的概率p1= 1-d(x,y)/pi,符合LSH的约束。
(d1,d2,1-d1/pi, 1-d2/pi)-sensitive
每个特征点,经过LSH处理,生成K维的{-1,+1}的向量,利用and-construct or-construct进一步优化即可
这里需要考虑的是如何选择K特征向量V,论文提高考虑要服从高斯分布。
4.欧式距离
欧式距离,L2-norm,计算两个点在欧式空间的距离。这个同cosin相似性一样,不能通过字面的相等不相等来计算。
比如[1,1,1]、[2,2,2] 的距离小于[1,1,1]、[10,10,10]的距离。
假定d(x,y)表示向量x,y的距离,值越大,相似性越低。
LSH的定义为:选择一条直线,水平或者垂直方向(针对多维数据,则取相应的直线),对直线按照宽度为a等分,利用用户在这个维度上的值,计算应该落在那一块,针对LSH 集合F,
fi(x) = (xi, a)~xi/a
基于F的定义,我们将情况分成2个部分:
1,x,y与直线平行:
d(x,y)为x,y的距离,d(x,y)< a,fi(x)=fi(y)的概率至少为p=(a-d(x,y))/a = 1 - d(x,y)/a:
d=0, 则p = 1
d = a/2,则p=0.5
p= 0.1a, 则 p = 0.9
p = a, 则p = 0
2.x,y与直线有夹角theta
如果d > a时,是有可能落在同一bucket中,比如下图的y,m。
根据cos法则,落在水平直线上的距离为d*cos(theta),如果距离刚好是a,可以计算出theta,则落在一个bucket的概率最多为1-theta/90,如果d*cos(theta)<a,则theta变大,概率变低。随着d的变大,概率降低
如果d=2a,则theta=60,p=1/3
如果d=sqrt(a),则theta=45,p=1/2
则为(a/2, 2a, 1/2,1/3)-sensitive,符合d1>d2, p2< p1的约束。
解释一下,如果距离小于a/2,至少以p=1/2的概率落在一起,如果d变小,落在一个bucket的概率曾江;如果d>2a,则最多1/3的概率落在一起,如果d变大,摞在一起的概率一定降低
这说明一个事情,d1<d2,则p1>p2的成立条件是[0,d1][d2,~],大多数情况下(jaccard,hamming,cos),如果d1<d2,则p1>p2对任何d1<d2关系都成立。但是在欧式距离不一定。这是因为LSH F集合导致的。
不过在实际使用中,我们定义LSH 集合F,F = {f1,f2....fk},fi(x)为x的第i维在对应直线上的bucke id,具体a的大小 依赖于业务,如果d一定,那么越大,落在一起的概率就越高,无论d1还是d2
如果d(x,y) < d~a/2,则fi(x)=fi(y)的概率p=(a-d)/a = 0.5
|
|
| m.
z.
|
|
| x. y.
|
|
|
|
|
|
|--------------|--------------|--------------|--------------|--------------|--------------|--------------|
两点之间的距离可以用两种方式来衡量,一是几何距离,二是非几何距离。很显然距离的定义满足下面的条件:
d(x,y) > 0.
d(x,y) = 0 iff x = y.
d(x,y) = d(y,x).
d(x,y) < d(x,z) + d(z,y)
几何距离包括:
L2 norm : d(x,y) 是平方和的开方
L1 norm : d(x,y) 是每个维度的距离之和
L∞ norm : d(x,y) 是x和y在每个维度上距离的最大值
非几何距离用的就比较多了:
Jaccard距离:1减去Jaccad相似度
余弦距离:两个向量之间的角度
编辑距离(Edit distance):将一个串变为另一个串需要的插入或删除次数
海明距离(Hamming Distance):Bit向量中不同位置的个数
这里有一个重要的公理:三角形公理(Triangle Inequality),也就是距离的第四个性质。编辑距离d(x,y) = |x| + |y| – 2|LCS(x,y)|,其中LCS是longest common subsequence,最长公共子序列。
LSH的一个核心思想就是两个元素哈希值相等的概率等于两个元素之间的相似度。
下面介绍一个重要概念:Hash Family,哈希家族?不管怎么翻译,它指的是能够判断两个元素是否相等(h(x) = h(y) )的Hash函数集合。LS Hash Family,局部敏感哈希家族的定义是满足下面两个条件的哈希函数家族:
如果d(x,y) < d1,那么哈希家族H中的哈希函数h满足h(x) = h(y)的概率至少是p1.
如果d(x,y) > d2,那么哈希家族H中的哈希函数h满足h(x) = h(y)的概率至多是p2.
就是如果x和y离得越近,Pr[h(p)=h(q)]就越大。如果x和y离得越远,Pr[h(p)=h(q)]就越小。我们把局部敏感哈希家族记为(d1,d2,p1,p2)-sensitive。那什么样的函数满足呢?Jaccard就是。我们令S为一个集合,d是Jaccard距离,有Prob[h(x)=h(y)] = 1-d(x,y),我们就可以得到一个局部敏感哈希家族:a(1/3, 2/3, 2/3, 1/3)-sensitive。事实上,只要满足d1<d2,就可以得到一个局部敏感的哈希家族:(d1,d2,(1-d1),(1-d2))-sensitive。
(d1,d2,p1,p2)-sensitive将整个概率空间分成了三部分:<p1,p1-p2,>p2。为了有更好的区分度,我们想让p1-p2的空间尽可能小,让d2-d1尽可能大。选择合适的参数,能够有类似于下面的S曲线应该就是不错的了。可如何来做呢?
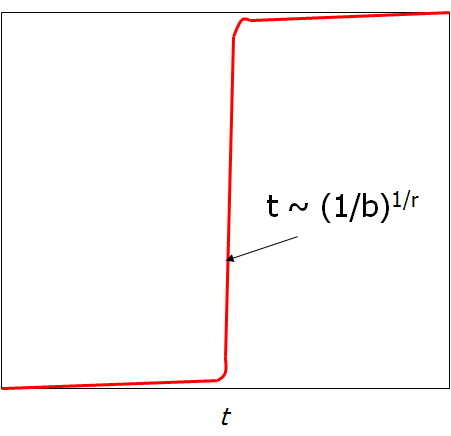
定义两种哈希函数的操作:AND和OR。
AND操作:在局部敏感哈希家族H中选出r个哈希哈数,构成哈希家族H’。对于H’家族中的h = [h1,…,hr],h(x)=h(y)当且仅当对所有的i,所有hi(x)=hi(y)都满足。这样得到的H’同样也是一个局部敏感哈希家族。并且若源哈希家族是(d1,d2,p1,p2)-sensitive,新哈希家族H’是(d1,d2,(p1)^r,(p2)^r)-sensitive。
OR操作:在局部敏感哈希家族H中选出b个哈希哈数,构成哈希家族H’。对于H’家族中的h = [h1,…,hb],h(x)=h(y)当且仅当存在i,满足hi(x)=hi(y)。这样得到的H’同样也是一个局部敏感哈希家族。并且若源哈希家族是(d1,d2,p1,p2)-sensitive,新哈希家族H’是(d1,d2,1-(1-p1)^b,1-(1-p2)^b)-sensitive。
可以看出AND操作是降低了概率,但如果选取一个合适的r,可以使下限概率接近0,而上限概率没有多大影响。类似的,OR操作是增加了概率,但如果选择一个合适的d,可以使上限概率接近1,而下限概率没有多大影响。
我们对AND操作和OR操作做级联:
AND-OR,1-(1-p^r)^b
OR-AND,(1-(1-p)^b)^r
举个例子,1-(1-p^4)^4,当p取不同值时:
| p | 1-(1-p4)4 |
| .2 | .0064 |
| .3 | .0320 |
| .4 | .0985 |
| .5 | .2275 |
| .6 | .4260 |
| .7 | .6666 |
| .8 | .8785 |
| .9 | .9860 |
p | (1-(1-p)4)4 |
.1 | .0140 |
.2 | .1215 |
.3 | .3334 |
.4 | .5740 |
.5 | .7725 |
.6 | .9015 |
.7 | .9680 |
.8 | .9936 |

参考上图,如果我们要返回距离中心为r的点,LSH会返回给我们范围更远、更多的点,也就是说,LSH返回的结果会带有一定的false positive。我们或许需要使用linear search进行二次筛选,但这毕竟大大减少了计算的时间。
由此可见,LSH与一般的加密型哈希函数有很大的区别,参见下图:

一种实现(LSH)的最简单的方式是采用random bits sampling的方式,即将待索引的多维整型向量转化为0或1的字符串;再采用随机选取其中的K位拼接成新的字符串;最后再采用常规的哈希函数(例如MD5)等算法获取带索引向量的LSH Code。这样的Hash Code有一个特点,就是Hamming Distance相近的两个向量,其冲突的概率越大,即结果相等的可能性越大。为了减少增强KNN搜索的能力,与Bloom Filter类似,采用多个Hash Table增加冲突的概率,参见下图:

来看一下LSH的复杂度:

可见,与各种其它的数据结构相比,基于lsh的索引结构的query时间复杂度,可以做到与向量维度无关,有效地克服了维度灾难的问题,因此更适合高维向量的索引。
基于LSH实现的图像近似检索,其原理也很类似,如下图所示:


This entry was posted in Computing, Theories and
tagged Big
Data, LSH by Jason
KIM. Bookmark thepermalink.
Related Posts
二.simHash算法简介
以前写的一个介绍simHash的。1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
三.算法几何意义及原理
3.1 几何意义
这个算法的几何意义非常明了。它首先将每一个特征映射为f维空间的一个向量,这个映射规则具体是怎样并不重要,只要对很多不同的特征来说,它们对所对应的向量是均匀随机分布的,并且对相同的特征来说对应的向量是唯一的就行。比如一个特征的4位hash签名的二进制表示为1010,那么这个特征对应的 4维向量就是(1, -1, 1, -1)T,即hash签名的某一位为1,映射到的向量的对应位就为1,否则为-1。然后,将一个文档中所包含的各个特征对应的向量加权求和,加权的系数等于该特征的权重。得到的和向量即表征了这个文档,我们可以用向量之间的夹角来衡量对应文档之间的相似度。最后,为了得到一个f位的签名,需要进一步将其压缩,如果和向量的某一维大于0,则最终签名的对应位为1,否则为0。这样的压缩相当于只留下了和向量所在的象限这个信息,而64位的签名可以表示多达264个象限,因此只保存所在象限的信息也足够表征一个文档了。
3.2 算法原理描述性证明
明确了算法了几何意义,使这个算法直观上看来是合理的。但是,为何最终得到的签名相近的程度,可以衡量原始文档的相似程度呢?这需要一个清晰的思路和证明。在simhash的发明人Charikar的论文中并没有给出具体的simhash算法和证明,以下列出我自己得出的证明思路。Simhash是由随机超平面hash算法演变而来的,随机超平面hash算法非常简单,对于一个n维向量v,要得到一个f位的签名(f<<n),算法如下:
1,随机产生f个n维的向量r1,…rf;
2,对每一个向量ri,如果v与ri的点积大于0,则最终签名的第i位为1,否则为0.
这个算法相当于随机产生了f个n维超平面,每个超平面将向量v所在的空间一分为二,v在这个超平面上方则得到一个1,否则得到一个0,然后将得到的 f个0或1组合起来成为一个f维的签名。如果两个向量u, v的夹角为θ,则一个随机超平面将它们分开的概率为θ/π,因此u, v的签名的对应位不同的概率等于θ/π。所以,我们可以用两个向量的签名的不同的对应位的数量,即汉明距离,来衡量这两个向量的差异程度。
Simhash算法与随机超平面hash是怎么联系起来的呢?在simhash算法中,并没有直接产生用于分割空间的随机向量,而是间接产生的:第 k个特征的hash签名的第i位拿出来,如果为0,则改为-1,如果为1则不变,作为第i个随机向量的第k维。由于hash签名是f位的,因此这样能产生 f个随机向量,对应f个随机超平面。下面举个例子:
假设用5个特征w1,…,w5来表示所有文档,现要得到任意文档的一个3维签名。假设这5个特征对应的3维向量分别为:
h(w1) = (1, -1, 1)T
h(w2) = (-1, 1, 1)T
h(w3) = (1, -1, -1)T
h(w4) = (-1, -1, 1)T
h(w5) = (1, 1, -1)T
按simhash算法,要得到一个文档向量d=(w1=1, w2=2, w3=0, w4=3, w5=0) T的签名,
先要计算向量m = 1*h(w1) + 2*h(w2) + 0*h(w3) + 3*h(w4) + 0*h(w5) = (-4, -2, 6) T,然后根据simhash算法的步骤3,得到最终的签名s=001。上面的计算步骤其实相当于,先得到3个5维的向量,第1个向量由h(w1),…,h(w5)的第1维组成:r1=(1,-1,1,-1,1)
T;第2个5维向量由h(w1),…,h(w5)的第2维组成:r2=(-1,1,-1,-1,1) T;同理,第3个5维向量为:r3=(1,1,-1,1,-1)
T.按随机超平面算法的步骤2,分别求向量d与r1,r2,r3的点积:
d T r1=-4 < 0,所以s1=0;
d T r2=-2 < 0,所以s2=0;
d T r3=6 > 0,所以s3=1.
故最终的签名s=001,与simhash算法产生的结果是一致的。
从上面的计算过程可以看出,simhash算法其实与随机超平面hash算法是相同的,simhash算法得到的两个签名的汉明距离,可以用来衡量原始向量的夹角。这其实是一种降维技术,将高维的向量用较低维度的签名来表征。衡量两个内容相似度,需要计算汉明距离,这对给定签名查找相似内容的应用来说带来了一些计算上的困难;我想,是否存在更为理想的simhash算法,原始内容的差异度,可以直接由签名值的代数差来表示呢?
请先阅读有关图的基本知识,图的拉普拉斯矩阵分析以及谱聚类相关内容,谱哈希基于上述技术基础。
谱哈希对图像特征向量的编码过程可看做是图分割问题,借助于对相似图的拉普拉斯矩阵特征值和特征向量的分析可对图分割问题提供一个松弛解。由谱聚类可知,相似图拉普拉斯矩阵的特征向量实际上就是原始特征降维后的向量,但其并不是0-1的二值向量,可通过对特征向量进行阈值化产生spectral hashing的二值编码(The bits in spectral
hashing are calculated by thresholding a subset of eigenvectors of Laplacians of the similar graph).
若原始特征向量空间用高斯核度量相似度
,则令
为二值化后的特征向量矩阵即经Spectral
Hashing后的二值特征向量,则在低维Hamming空间的平均Hamming距离可表示为
。此外,What makes good
code?
(1) each bit has 50% chance of being 0 or 1;
(2) the bits are independent of each other(always relaxed to uncorrelated).
因此,spectral hashing的编码过程可描述为下述的优化问题(为了求解问题的方便,将二值中的0表示为-1):
用Spectral 理论描述为:
若没有二值的约束
,则上述优化问题就简化为
是拉普拉斯矩阵
的
个最小特征值所对应的特征向量构成的矩阵,通过简单的Thresholding可获取Binary
Code。
但上述的编码过程仅适用于训练集,而我们需要的是能够泛化到任意给定的out-of-example特征向量,因此引入
来描述原始特征空间中数据点的概率分布,则上述的优化问题可表述为:
当暂不考虑二值化约束时,上述优化问题的解即是eigenfunctions of weighted Laplace-Beltramician operactor
with
minimal
eigenvalue. And with proper normalization, the eigenvectors of the discrete Laplacian defined by
points sampled from
coverges
to eigenfunctions of
as
.
因此,就转化为如何利用服从
分布的
个离散的数据点求取
的特征方程的问题:
当
是separable distribution时,即
,亦即各维之间相互独立时,
的特征方程具有outer
product 形式:
即若
是特征值
对应的一维空间
的特征方程,则
是特征值
对应的
维空间的特征方程。特别的,针对
区间内均匀可分离的分布
,一维空间的特征值和特征向量可通过下式求得:
----------function
(1)
,
----------function
(2)
Summarize the spectral hashing alogrithm:
Input:
data points
and
the hashed bits
Finding the
principal components of the data using PCA;
Calculating the
smallest single-dimension analytical eigenfunctions of
along every PCA direction. This is done by evaluating the
smallest eigenvalues for each direction using function (2), thus creating a list
of
eigenvalues, and then sorting this list to find the
smallest
eigenvalues; ???
Thresholding the analytical eigenfunctions at zero, to obtain binary codes.
分析:
Step1中PCA的主要作用是align the axes for data points, 也就是使数据点各维之间相互独立,符合seperate distribution;
Step2个人理解应该是先求取
维数据点每一维
均匀分布区间
,然后利用方程(2)求取每一维对应的最小的
个特征值
,因此总计有
个特征值。然后在
个特征值中选取最小的
个,并记录其所对应的向量维度
及其特征值序号
,即
对;针对选取的
各最小特征值,计算其对应的一维特征方程
。
Step3是采用符号函数,对选取的特征方程进行二值化,产生二值码
由此可见,对图的
次分割,每次都是选取
维空间的某一维,并没有利用特征方程的outer-product的特性,paper
中的解释是二值化编码采用的是符号函数,且
,因此一个bit的取值可由其它bits确定,失了去独立性。但其前提是建立在每一个bit对应的特征方程是由其它bits对应特征方程的outer-product,若bits之间不包含相同的特征方程,则还会继续保留各bits之间的独立性。因此outer-product的特征方程应该也可以利用。这仅是个人理解,具体效果还有待验证。
训练集的作用主要是产生每维对应的分布区间
,利用记录的
个最小特征值对应的维度与特征值序号对
扩展至out-of-example。

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析
- C++实现汉诺塔算法经典实例
- PHP实现克鲁斯卡尔算法实例解析