2016/1/8 预习 冒泡排序和快速排序 (面试必知)
2016-01-09 00:44
232 查看
冒泡排序
(一)概念及实现
冒泡排序的原理:重复的遍历要排序的数组,每次遍历过程中从头至尾比较两个相邻的元素,若顺序错误则交换两个元素。
具体如下(实现为升序):
设数组为a[0…n]。
从头至尾比较相邻的元素。如果第一个元素比第二个元素大,就交换。
重复步骤1,每次遍历都将冒出一个最大数,直到排序完成。
实现代码:
示例:
89,-7,999,-89,7,0,-888,7,-7
排序的过程:
-7 89 -89 7 0 -888 7 -7 [999]
-7 -89 7 0 -888 7 -7 [89] 999
……
……
-888 [-89] -7 -7 0 7 7 89 999
(二)算法复杂度
时间复杂度:O(n^2)
冒泡排序耗时的操作有:比较 + 交换(每次交换两次赋值)。时间复杂度如下:
1) 最好情况:序列是升序排列,在这种情况下,需要进行的比较操作为(n-1)次。交换操作为0次。即O(n)
2) 最坏情况:序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。交换操作数和比较操作数一样。即O(n^2)
3) 渐进时间复杂度(平均时间复杂度):O(n^2)
空间复杂度:O(1)
从实现原理可知,冒泡排序是在原输入数组上进行比较交换的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
(三)稳定性
冒泡排序是稳定的,不会改变相同元素的相对顺序。
(四)优化改进
有序优化:在进行相邻元素比较时,可以记录下循环中没有发生交换的多个连续索引对(起始索引和结束索引),在下次轮询时直接对有序区间的最大值进行比较。
双向冒泡:参考资料过程中看到了双向冒泡,不同之处在于“从左至右与从右至左两种冒泡方式交替执行”,个人认为不能提高算法效率并且增加代码复杂度。
快速排序
(一)概念及实现
思想:分治策略。
快速排序的原理:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序。
"保证列表的前半部分都小于后半部分"就使得前半部分的任何一个数从此以后都不再跟后半部分的数进行比较了,大大减少了数字间的比较次数。
具体如下(实现为升序):
设数组为a[0…n]。
数组中找一个元素做为基准(pivot),通常选数组的第一个数。
对数组进行分区操作。使基准元素左边的值都小于pivot,基准元素右边的值都大于等于pivot。
将pivot值调整到分区后的正确位置。
将基准两边的分区序列,分别进行步骤1~3。(递归)
重复步骤1~4,直到排序完成。
实现代码:
特别注意在递归前的判断语句,他减少了50%-55%的递归次数。
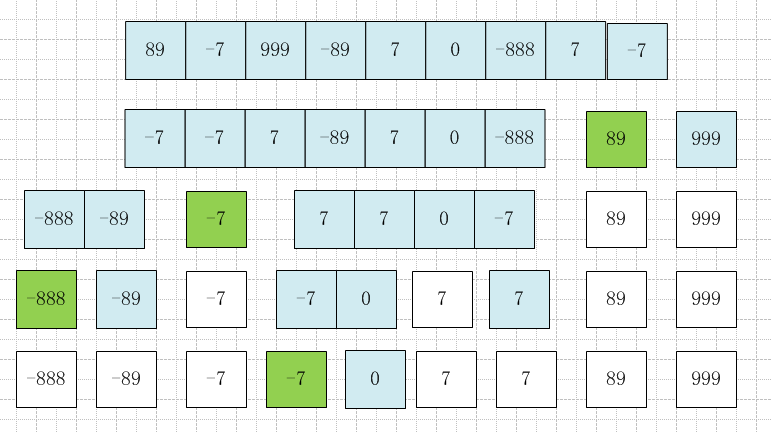
示例:
89,-7,999,-89,7,0,-888,7,-7
排序的过程:
(以数组第一个元素做为基准值。蓝色代表被分区出来的子数组,绿色代表本次分区基准值)
(二)算法复杂度
时间复杂度:O(nlog2n)
快速排序耗时的操作有:比较 + 交换(每次交换两次赋值)。时间复杂度如下:
1) 最好情况:选择的基准值刚好是中间值,分区后两分区包含元素个数接近相等。因为,总共经过x次分区,根据2^x<=n得出x=log2n,每次分区需用n-1个元素与基准比较。所以O(nlog2n)
2) 最坏情况:每次分区后,只有一个分区包含除基准元素之外的元素。这样就和冒泡排序一样慢,需n(n-1)/2次比较。即O(n^2)
3) 渐进时间复杂度(平均时间复杂度):O(nlog2n)
空间复杂度:O(1)
从实现原理可知,快速排序是在原输入数组上进行比较分区的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
(三)稳定性
快速是不稳定的,会改变相同元素的相对顺序。如示例,以第一个基准89排序时,首先将最后一个元素-7移到了第一个分区的第一个位置上。改变了与第二个-7的相对顺序。
(四)优化改进
当每次分区后,两个分区的元素个数相近时,效率最高。所以找一个比较有代表性的基准值就是关键。通常会采取如下方式:
选取分区的第一个元素做为基准值。这种方式在分区基本有序情况下会分区不均。
随机快排:每次分区的基准值是该分区的随机元素,这样就避免了有序导致的分布不均的问题
平衡快排:取开头、结尾、中间3个数据,通过比较选出其中的中值。
根据改进方案,写了如下基准值选取委托:
性能测试
测试步骤:
随机生成10个测试数组。
每个数组中包含5000个元素。
对这个数组集合进行本博文中介绍的三种排序。
重复执行1~3步骤。执行20次。
部分顺序测试用例:顺序率5%。
共测试 10*20 次,长度为5000的数组排序
参数说明:
(Time Elapsed:所耗时间。CPU Cycles:CPU时钟周期。Gen0+Gen1+Gen2:垃圾回收器的3个代各自的回收次数)

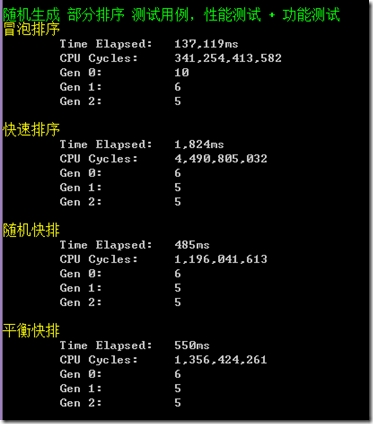
随机快排和平衡快排都比较稳定高效。顺序率约高,平衡快排的优势越明显。
(一)概念及实现
冒泡排序的原理:重复的遍历要排序的数组,每次遍历过程中从头至尾比较两个相邻的元素,若顺序错误则交换两个元素。
具体如下(实现为升序):
设数组为a[0…n]。
从头至尾比较相邻的元素。如果第一个元素比第二个元素大,就交换。
重复步骤1,每次遍历都将冒出一个最大数,直到排序完成。
实现代码:
89,-7,999,-89,7,0,-888,7,-7
排序的过程:
-7 89 -89 7 0 -888 7 -7 [999]
-7 -89 7 0 -888 7 -7 [89] 999
……
……
-888 [-89] -7 -7 0 7 7 89 999
(二)算法复杂度
时间复杂度:O(n^2)
冒泡排序耗时的操作有:比较 + 交换(每次交换两次赋值)。时间复杂度如下:
1) 最好情况:序列是升序排列,在这种情况下,需要进行的比较操作为(n-1)次。交换操作为0次。即O(n)
2) 最坏情况:序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。交换操作数和比较操作数一样。即O(n^2)
3) 渐进时间复杂度(平均时间复杂度):O(n^2)
空间复杂度:O(1)
从实现原理可知,冒泡排序是在原输入数组上进行比较交换的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
(三)稳定性
冒泡排序是稳定的,不会改变相同元素的相对顺序。
(四)优化改进
有序优化:在进行相邻元素比较时,可以记录下循环中没有发生交换的多个连续索引对(起始索引和结束索引),在下次轮询时直接对有序区间的最大值进行比较。
双向冒泡:参考资料过程中看到了双向冒泡,不同之处在于“从左至右与从右至左两种冒泡方式交替执行”,个人认为不能提高算法效率并且增加代码复杂度。
快速排序
(一)概念及实现
思想:分治策略。
快速排序的原理:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序。
"保证列表的前半部分都小于后半部分"就使得前半部分的任何一个数从此以后都不再跟后半部分的数进行比较了,大大减少了数字间的比较次数。
具体如下(实现为升序):
设数组为a[0…n]。
数组中找一个元素做为基准(pivot),通常选数组的第一个数。
对数组进行分区操作。使基准元素左边的值都小于pivot,基准元素右边的值都大于等于pivot。
将pivot值调整到分区后的正确位置。
将基准两边的分区序列,分别进行步骤1~3。(递归)
重复步骤1~4,直到排序完成。
实现代码:
示例:
89,-7,999,-89,7,0,-888,7,-7
排序的过程:
(以数组第一个元素做为基准值。蓝色代表被分区出来的子数组,绿色代表本次分区基准值)
(二)算法复杂度
时间复杂度:O(nlog2n)
快速排序耗时的操作有:比较 + 交换(每次交换两次赋值)。时间复杂度如下:
1) 最好情况:选择的基准值刚好是中间值,分区后两分区包含元素个数接近相等。因为,总共经过x次分区,根据2^x<=n得出x=log2n,每次分区需用n-1个元素与基准比较。所以O(nlog2n)
2) 最坏情况:每次分区后,只有一个分区包含除基准元素之外的元素。这样就和冒泡排序一样慢,需n(n-1)/2次比较。即O(n^2)
3) 渐进时间复杂度(平均时间复杂度):O(nlog2n)
空间复杂度:O(1)
从实现原理可知,快速排序是在原输入数组上进行比较分区的(称“就地排序”),所需开辟的辅助空间跟输入数组规模无关,所以空间复杂度为:O(1)
(三)稳定性
快速是不稳定的,会改变相同元素的相对顺序。如示例,以第一个基准89排序时,首先将最后一个元素-7移到了第一个分区的第一个位置上。改变了与第二个-7的相对顺序。
(四)优化改进
当每次分区后,两个分区的元素个数相近时,效率最高。所以找一个比较有代表性的基准值就是关键。通常会采取如下方式:
选取分区的第一个元素做为基准值。这种方式在分区基本有序情况下会分区不均。
随机快排:每次分区的基准值是该分区的随机元素,这样就避免了有序导致的分布不均的问题
平衡快排:取开头、结尾、中间3个数据,通过比较选出其中的中值。
根据改进方案,写了如下基准值选取委托:
测试步骤:
随机生成10个测试数组。
每个数组中包含5000个元素。
对这个数组集合进行本博文中介绍的三种排序。
重复执行1~3步骤。执行20次。
部分顺序测试用例:顺序率5%。
共测试 10*20 次,长度为5000的数组排序
参数说明:
(Time Elapsed:所耗时间。CPU Cycles:CPU时钟周期。Gen0+Gen1+Gen2:垃圾回收器的3个代各自的回收次数)
随机快排和平衡快排都比较稳定高效。顺序率约高,平衡快排的优势越明显。

相关文章推荐
- 评程序员和会不会修电脑到底有几毛钱关系?
- Java程序员应聘必须知道的那些事
- 我的面试
- 十个JAVA程序员容易犯的错误
- 面试2016/01/05
- [面试]排列组合与概率计算(一)
- 面试题11 删除单向链表中的一个元素 但是只提供这个元素的操作权
- 你真的需要掌握多种语言吗?
- iOS面试题汇总-----专辑
- 程序员必读的职业规划书 - 思维导图
- 测试工程师面试题之:给你印象最深的Bug
- 十个JAVA程序员容易犯的错误
- 【转】成为Java顶尖程序员 ,看这10本书就够了
- 【转】成为Java顶尖程序员 ,看这10本书就够了
- 挑战面试编程:查找数组中第k大的数
- 【转】成为Java顶尖程序员 ,看这10本书就够了
- 程序员修炼之路
- 做一个文艺范的程序员
- 据说,年薪百万的程序员,都是这么开悟的
- 国外程序员常去的14个顶级开发社区