【science封面文章】Human-level concept learning through probabilistic program induction
2016-01-03 22:44
513 查看
论文地址:《Human-level concept learning through probabilistic program induction》Science,11 December 2015
《通过概率规划归纳进行human-level的概念学习》,Science封面文章
这篇文章最近非常火,就连多伦多大学和谷歌的人工智能先驱Geoffrey Hinton都说这个研究「令人印象非常深刻」。他说,这个模型能通过视觉图灵测试,这很重要。「能实现这一点,是一个不错的成就。」
以下内容是我阅读原文和supplement material后的理解,如果有错误的地方,欢迎联系我修改。那么开始吧~
人类可以学习到更丰富的表征,即使是对于Fig 1B这样简单的概念,并将他们用于更多的任务。例如(i)对新的example进行分类,(ii)创造新的example,(iii)理解物体的构成,将物体分解成更小的部件和部件之间连接关系的集合,以及(iv)根据现有的类创造新的抽象类。而对于machine learning的方法来说,通常是针对特定任务的。
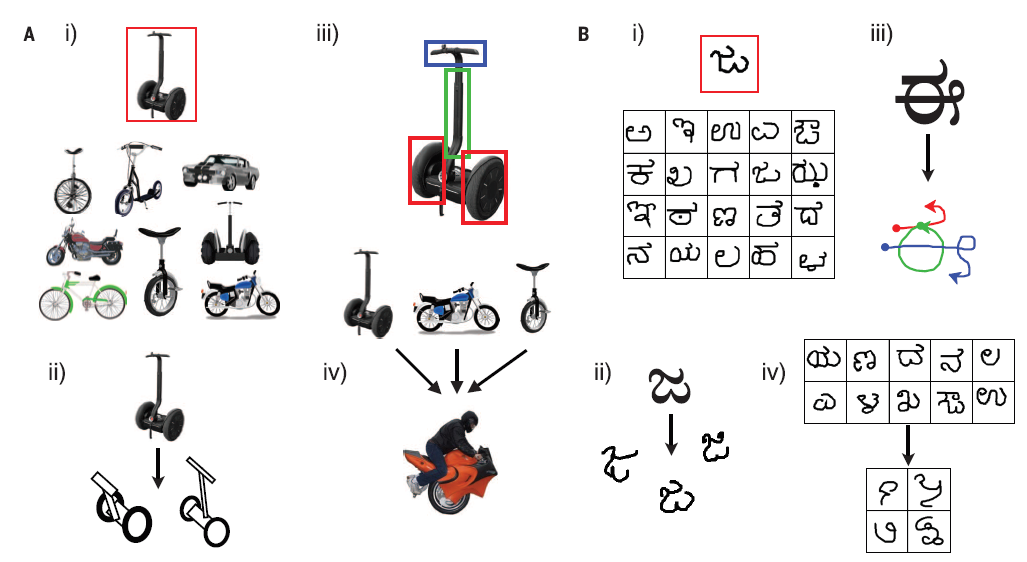
Fig 1
那么问题来了:人类是怎么从单个或少数的example中学到新的概念的呢?又是怎么从这么稀疏的数据中获得如此丰富的表征的呢?对于所有的learning方法而言,拟合一个更加复杂的模型需要更多的数据而不是更少,以便具有良好的泛化能力。尽管如此,人们似乎可以很快地从稀疏数据中学习丰富,可泛化的概念。
文章介绍了一种Bayesian program learning(BPL)框架,能够从一个example中学习到很多的视觉概念(visual concepts),并且以近似人类的方式进行泛化。concepts被表示成简单的概率规划(probabilistic programs)。我们的框架解决了3大关键问题:语义合成,因果关系,自主学习(compositionality, causality, and learning to learn),这些问题在认知科学和机器学习中是非常重要的。
语义合成(compositionality):表征是由更简单的基元构建而成。
因果关系(causality):模型表征了物体是如何生成的这一抽象的因果关系。比如我们看到一个字符,就知道他是怎么写的,并且可以写出它的不同变体
自主学习(learning to learn):过去的概念知识能够帮助学习新概念。简单地说就是BPL可以从现有的字符中抽象出其部件,然后根据不同部件的因果关系创造新的字符。
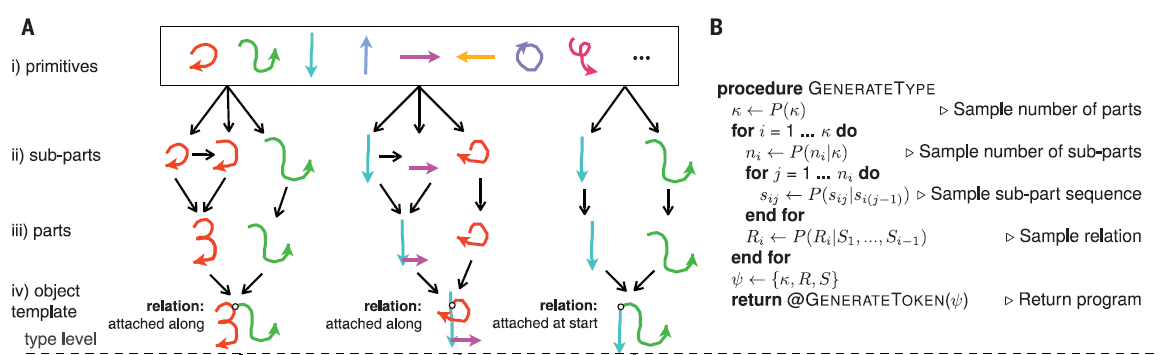
文章以字符为例比较了人类,BPL和其他一些算法在学习概念(concept learning task)上的差别,这一任务用到的视觉概念来自于Omniglot,这是一个我们从50个书写系统中收集到的1623个手写字符(Fig 2),包含每个字符的图片和笔画。(这里所说的视觉概念可以理解成一个字符,比如说中文里一个“高”字,不同的人可能写出不同版本的高,但这些都是“高”这个concept的examples)
关于Omniglot数据集:首先从www.omniglot.com网站上获取这么多字符的图片(printed form),再在Amazon Mechanical Turk (AMT)上雇佣志愿者来看图手写这些字符,手写过程会被记录,包括何时提笔,何时落笔,字符笔画的书写顺序等,这样就相当于进行了笔画的拆分。

概念类Ψ和M个该类的token{θ(1),...,θ(M)}以及对应的二值图像{I(1),...,I(M)}之间的联合概率分布为:
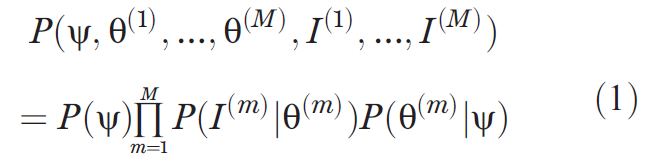
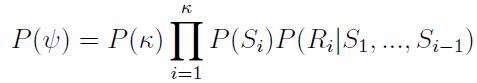
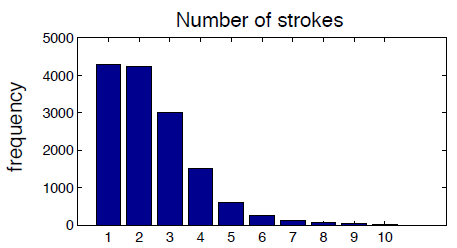
其中笔画数目κ是由经验频率(empirical frequencies)估计的多项式P(κ)采样得到的。如下图我们看出所有的字符中,1笔2笔的字符最多,3,4,5笔的稍少,笔画更多的则更少。根据统计结果我们可以估计出笔画数目k为不同值得一个概率P(k).
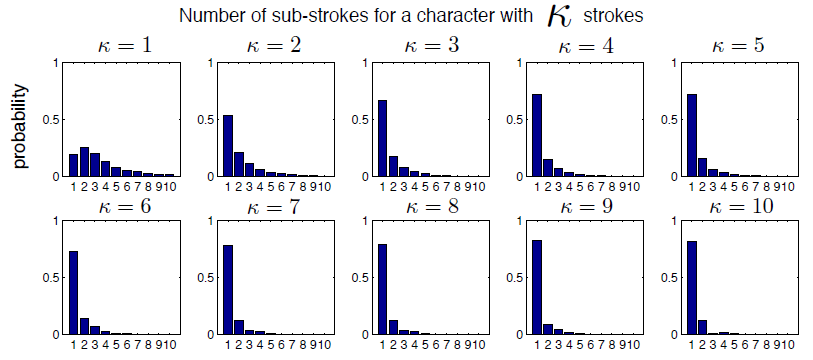
得到笔画数目以后再来考虑各个笔画是什么。一段笔画是落笔-提笔的一个阶段(Fig. 3A, iii),其中每次暂停分割开了许多的子笔画(Fig. 3A, ii),即Si={si1,....sini},子笔画的数目ni是由经验频率采样得到,如下图,可以得到的一个结论是一个字符的笔画越多,笔画越简单(子笔画少)。
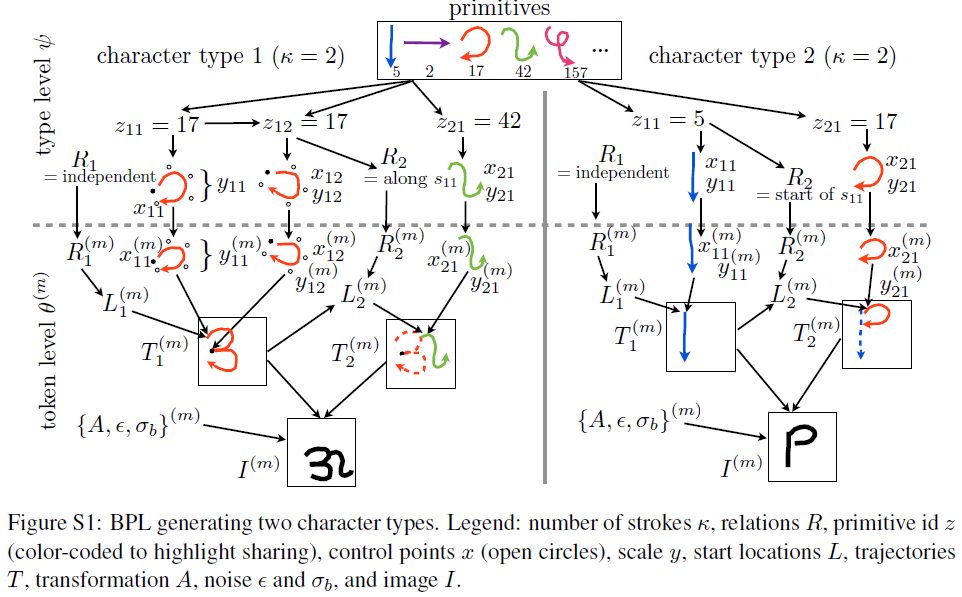
每段子笔画sij表示成3次B样条曲线,包含3个参数sij={zij,xij,yij},zij是当前子笔画在library of primitives中的index,xij是样条的5个控制点,yij是尺度因子,如Fig S1所示。则联合分布
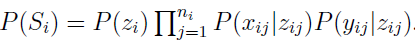
。其中
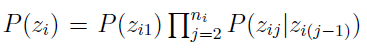
是一个从经验bigrams中学到的一阶马尔科夫过程。大概的意思就是说我们通过事先准备好的子笔画数据库进行采样,得到不同的子笔画,进而构造出不同的笔画,当然子笔画与子笔画之间是否会连续出现是受经验制约的,表示成一阶马尔科夫过程。(bigram是指给定seed primitive后,我们可以得到5个最可能的接下来的动作,即second primitive,这可以用一阶马尔科夫表示。)
得到P(Si)以后,他们之间的空间关系Ri表示的是笔画Si的起点与之前的笔画{S1,…,Si−1}的关系,共定义了4种关系:ξi={Independent, start, end, along},他们的可能性为θR(34% independent, 5% start, 11% end, and 50% along)。
笔画和关系都确定以后,一个字符类就创建好了,如下图所示。
在得到了tokenθ(m)后,它的图片I(m)则是通过定义一个grayscale ink模型来模拟墨水的笔迹,将token渲染成图片。
这样经过以上步骤,我们其实分别得到了P(Ψ),P(θ(m)|Ψ),P(I(m)|θ(m)),因此字符的生成模型就得到了。
正如我们一开始所说的,BPL可以完成不同的任务,如(i)对新的example进行分类,(ii)创造新的example,(iii)理解物体的构成,将物体分解成更小的部件和部件之间连接关系的集合,以及(iv)根据现有的类创造新的抽象类,我们下面就来介绍如何完成这些不同的任务。
学习subpart primitive:首先是根据笔画的暂停得到所有的subparts,然后经过一定规则的筛选最终得到1250个subpart的轨迹,每个subpart拟合成样条,并以5个控制点表示.
学习starting positions:开始位置通常集中在左上角,并且越早书写的笔画这一特性越明显。

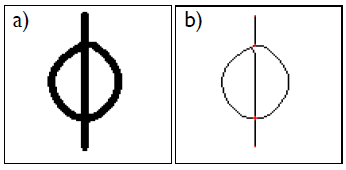
首先从图片中提取字符的骨架并得到关键点(下图a->b),
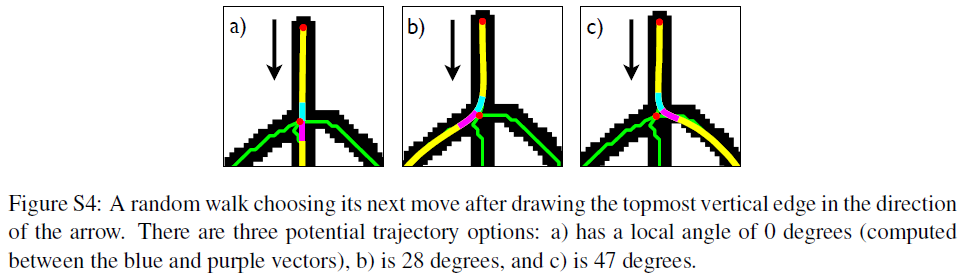
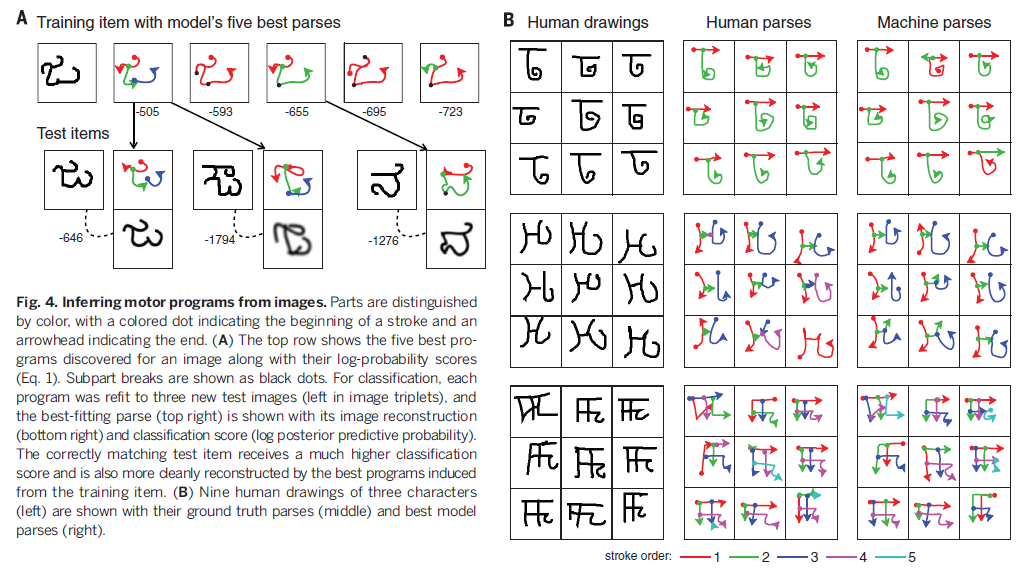
然后从最左上角的点开始查找可能的轨迹(即生成candidate parse),如图Fig S4,一共有3种轨迹,a)在交点处的角度为0,b)为28°,c)为47°,根据先验知识,通常会选择运动角度最小的轨迹,因此图a)轨迹的概率高于b)c),经过random walk,我们可以得到不同的candidate parse,也产生了这个字符的不同笔画。然后和之前一样地,根据笔画中的停顿将笔画拆分成子笔画,并且通过前面提到的笔画的generative model(也就是不同的子笔画之间是否会连续出现的那个马尔科夫过程)对拆分的过程进行打分。这样在搜索完成后,我们可以得到比较靠谱的candidate parse,也就是字符是怎么构成的。Fig 4B比较了模型最佳得分的parse和ground-truth human parse。
这一点是可以实现的,我的理解是,首先对这些例子进行parse,然后重新生成“经验”,也就是说这个alphabet中最常出现的笔画数目,子笔画的样式,相互位置关系等等,然后再根据这一经验去创造新的类。
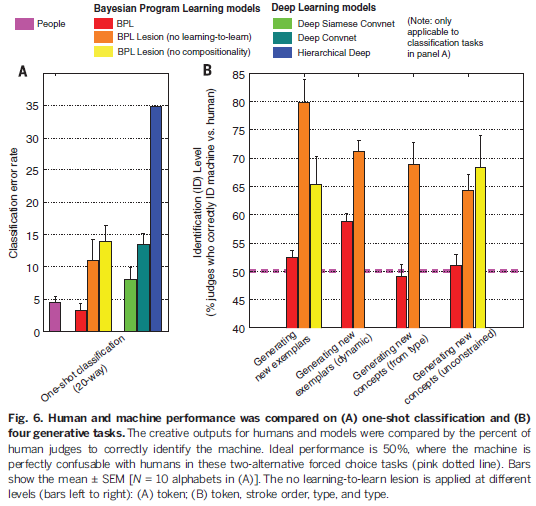
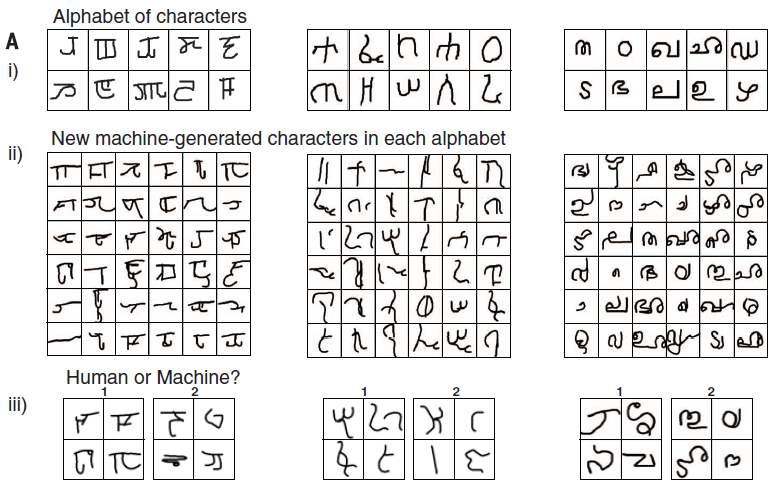
如图5所示,给定人类产生的9个新样例和机器产生的样例,人类裁判挑选出人类的作品,我们称为identification(ID)level。理想情况是50% ID level,即裁判不能区分哪些是机器产生的,哪些是人产生的,最差的performance是100%,就是说人类裁判完全能够正确区分人类和机器。从Fig 6B 中看出,147个人类裁判只实现了52%的ID level,这个结果只稍稍比50%的随机概率要好一点。而对于BPL lesion来说,没有了learning to learn和compositionality,图灵测试就简单多了(80% ID level和65% ID level),因此这两条principle对于BPL具有human-like 生成模型起到了关键作用。
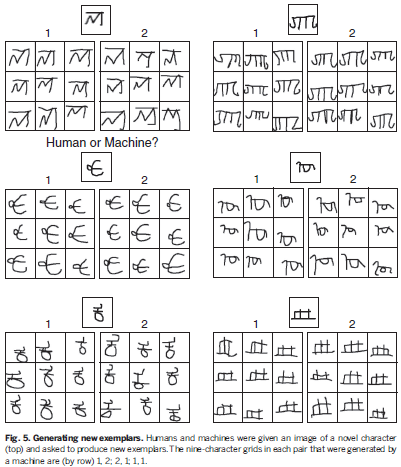
虽然BPL从30个background alphabets中学会学习新的character很有效,但是许多人类只需要很少的alphabet,如1个或几个,以及一些相关的drawing tasks。为了测试模型在更少的训练下的结果,我们重新训练了几个模型,只用了两个不同的子集,每个子集中包含5个background alphabets来进行训练。这时BPL 在one-shot learning问题上和之前表现差不多(两个子集的误差分别为4.3%,4.0 %error),同时deep convnet 则比之前的结果差很多(24%,22.3%).BPL在生成样例的视觉图灵测试上的结果也和之前差不多(52%和57%)。这些实验结果说明,虽然learning to learn是BPL成功的关键,模型的结构使得他能够在有限的background training中依旧能够得到很好的效果。
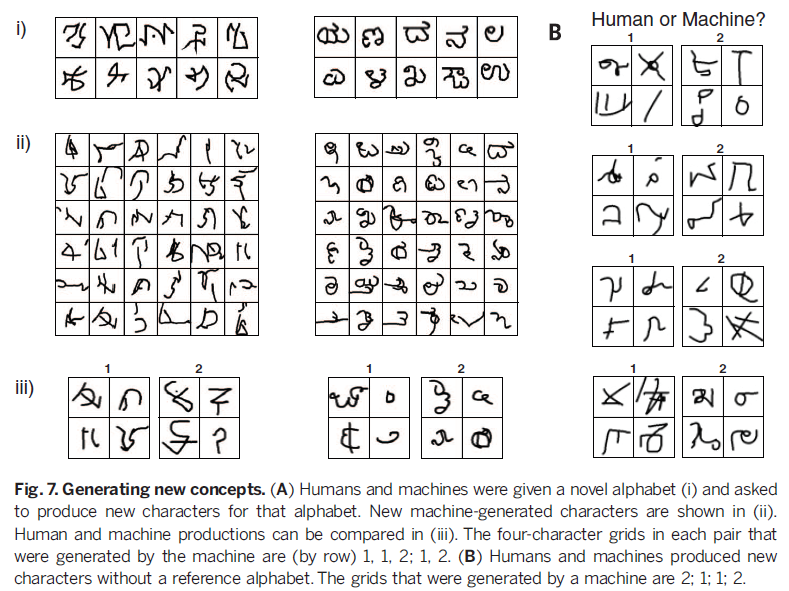
最后,124 个裁判比较了在完全unconstrained的情况下生成new concept(不受限于某个特定的alphabet,即Fig 7B),达到51%的ID level。BPL lesion的结果分别是68%和64%,说明compositionality和learning to learn都是通过视觉图灵测试的关键。
这种机制和人的大脑有着相似的地方。(最后这段话来自于知乎)人有大量先验知识(background set),这些知识首先会被分析并提取出各个层次的feature(part、subpart),之后大脑会尝试对这些feature进行不同的组合,包括完全不同领域的知识,并且从中筛选出有意义的组合(绝大多数都是完全没有意义的),当接收到一个全新的知识时,会与某些已经尝试过的组合非常契合,经过进一步适应,就能非常快的接受这样一个新的知识。当然人不仅可以利用先验知识准备一堆组合为新的知识服务,还可以通过内部的筛选机制,将有用的组合直接呈现给意识,也就是灵感迸发的时候。这篇工作将大脑的这种举一反三的能力运用了出来,可以说是非常有意义的,当然这篇工作中,feature的提取和组合用的是简单的拆分和条件概率的计算,对组合的筛选也是用的最简单的评分和排序,都是浅层的模型。用浅层的模型来完成复杂信息的组合和筛选是不现实的,以后如果能与深度网络结合起来,相信能有更大的突破,具有更强的举一反三地能力。
《通过概率规划归纳进行human-level的概念学习》,Science封面文章
这篇文章最近非常火,就连多伦多大学和谷歌的人工智能先驱Geoffrey Hinton都说这个研究「令人印象非常深刻」。他说,这个模型能通过视觉图灵测试,这很重要。「能实现这一点,是一个不错的成就。」
以下内容是我阅读原文和supplement material后的理解,如果有错误的地方,欢迎联系我修改。那么开始吧~
Abstract
这篇文章针对的是one-shot learning,即小数据集下计算机学习的问题。通过一个基于bayesian的模型(BPL)来建模人类学习visual concepts的能力(所用的训练数据是世界各地的字母表的手写字符)。在one-shot classification问题上,该模型达到了human-level performance同时甩了deep learning approaches几条街(不过deep learning本来就不适用于one-shot)。另外一个selling point就是BPL是有创造性的——识别新的example,知道如何把object分成几块并知道它们相互间的关系,创造新的category等,也就是说BPL能自动归纳、抽象训练数据里的高层次信息。我们也通过几个视觉图灵测试来测试BPL的创造泛化能力(creative generalization abilities),结果显示在很多情况下,BPL和人类的行为相近,裁判区分不出哪些是人类做的,哪些是机器做的。Motivation
人类总可以从single example里面抽象出new concept并进行泛化,例如Fig 1A,我们只要看到一张两轮的车,就可以对新的examples进行分类,而计算机对于one-shot learning的能力就比较差,特别是现在火的不得了的DL,还是data-hungry的。人类可以学习到更丰富的表征,即使是对于Fig 1B这样简单的概念,并将他们用于更多的任务。例如(i)对新的example进行分类,(ii)创造新的example,(iii)理解物体的构成,将物体分解成更小的部件和部件之间连接关系的集合,以及(iv)根据现有的类创造新的抽象类。而对于machine learning的方法来说,通常是针对特定任务的。
Fig 1
那么问题来了:人类是怎么从单个或少数的example中学到新的概念的呢?又是怎么从这么稀疏的数据中获得如此丰富的表征的呢?对于所有的learning方法而言,拟合一个更加复杂的模型需要更多的数据而不是更少,以便具有良好的泛化能力。尽管如此,人们似乎可以很快地从稀疏数据中学习丰富,可泛化的概念。
文章介绍了一种Bayesian program learning(BPL)框架,能够从一个example中学习到很多的视觉概念(visual concepts),并且以近似人类的方式进行泛化。concepts被表示成简单的概率规划(probabilistic programs)。我们的框架解决了3大关键问题:语义合成,因果关系,自主学习(compositionality, causality, and learning to learn),这些问题在认知科学和机器学习中是非常重要的。
语义合成(compositionality):表征是由更简单的基元构建而成。
因果关系(causality):模型表征了物体是如何生成的这一抽象的因果关系。比如我们看到一个字符,就知道他是怎么写的,并且可以写出它的不同变体
自主学习(learning to learn):过去的概念知识能够帮助学习新概念。简单地说就是BPL可以从现有的字符中抽象出其部件,然后根据不同部件的因果关系创造新的字符。
文章以字符为例比较了人类,BPL和其他一些算法在学习概念(concept learning task)上的差别,这一任务用到的视觉概念来自于Omniglot,这是一个我们从50个书写系统中收集到的1623个手写字符(Fig 2),包含每个字符的图片和笔画。(这里所说的视觉概念可以理解成一个字符,比如说中文里一个“高”字,不同的人可能写出不同版本的高,但这些都是“高”这个concept的examples)
关于Omniglot数据集:首先从www.omniglot.com网站上获取这么多字符的图片(printed form),再在Amazon Mechanical Turk (AMT)上雇佣志愿者来看图手写这些字符,手写过程会被记录,包括何时提笔,何时落笔,字符笔画的书写顺序等,这样就相当于进行了笔画的拆分。
Bayesian Program Learning
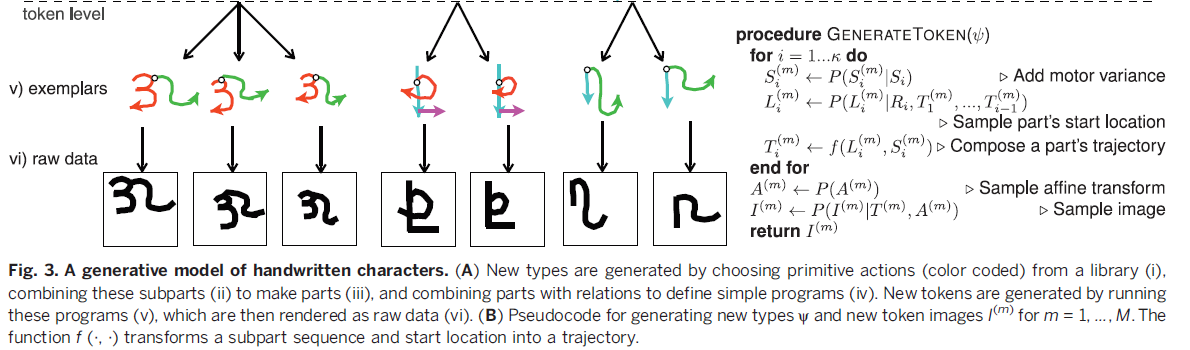
BPL通过简单的随机规划来表示concept,通过parts (Fig. 3A, iii)/ subparts (Fig.3A, ii)/ relation (Fig. 3A, iv)来进行语义合成,BPL定义了一个生成模型,可以通过对现有parts/subparts的重新组合得到新的concept type。然后新的概念类同样可以表示成一个生成模型,这个低层次的生成模型可以生成该概念的新的例子-token(Fig. 3A, v),这样BPL就是生成模型的生成模型了。概念类Ψ和M个该类的token{θ(1),...,θ(M)}以及对应的二值图像{I(1),...,I(M)}之间的联合概率分布为:
3.1 Generating character types
一个字符类Ψ={κ,S,R}是由κ段笔画S={S1,...,Sκ}以及他们之间的位置关系R={R1,...,Rκ}组成的,如“二”这个字符类,是由2段笔画,并且相互独立的位置关系构成的。联合概率为其中笔画数目κ是由经验频率(empirical frequencies)估计的多项式P(κ)采样得到的。如下图我们看出所有的字符中,1笔2笔的字符最多,3,4,5笔的稍少,笔画更多的则更少。根据统计结果我们可以估计出笔画数目k为不同值得一个概率P(k).
得到笔画数目以后再来考虑各个笔画是什么。一段笔画是落笔-提笔的一个阶段(Fig. 3A, iii),其中每次暂停分割开了许多的子笔画(Fig. 3A, ii),即Si={si1,....sini},子笔画的数目ni是由经验频率采样得到,如下图,可以得到的一个结论是一个字符的笔画越多,笔画越简单(子笔画少)。
每段子笔画sij表示成3次B样条曲线,包含3个参数sij={zij,xij,yij},zij是当前子笔画在library of primitives中的index,xij是样条的5个控制点,yij是尺度因子,如Fig S1所示。则联合分布
。其中
是一个从经验bigrams中学到的一阶马尔科夫过程。大概的意思就是说我们通过事先准备好的子笔画数据库进行采样,得到不同的子笔画,进而构造出不同的笔画,当然子笔画与子笔画之间是否会连续出现是受经验制约的,表示成一阶马尔科夫过程。(bigram是指给定seed primitive后,我们可以得到5个最可能的接下来的动作,即second primitive,这可以用一阶马尔科夫表示。)
得到P(Si)以后,他们之间的空间关系Ri表示的是笔画Si的起点与之前的笔画{S1,…,Si−1}的关系,共定义了4种关系:ξi={Independent, start, end, along},他们的可能性为θR(34% independent, 5% start, 11% end, and 50% along)。
笔画和关系都确定以后,一个字符类就创建好了,如下图所示。
3.2 Genertating character tokens
在得到一个字符类后,生成他的token就简单了,如图Fig 3,在不同笔画上增加一些运动变量(motor variable),对每一笔画的起始位置进行采样,得到新的轨迹,然后再进行新的仿射变换,使得输出的token会有所不同。在得到了tokenθ(m)后,它的图片I(m)则是通过定义一个grayscale ink模型来模拟墨水的笔迹,将token渲染成图片。
这样经过以上步骤,我们其实分别得到了P(Ψ),P(θ(m)|Ψ),P(I(m)|θ(m)),因此字符的生成模型就得到了。
正如我们一开始所说的,BPL可以完成不同的任务,如(i)对新的example进行分类,(ii)创造新的example,(iii)理解物体的构成,将物体分解成更小的部件和部件之间连接关系的集合,以及(iv)根据现有的类创造新的抽象类,我们下面就来介绍如何完成这些不同的任务。
One-shot learning(从图片生成字符)
首先需要说明的是,我们通过background set(包括30个字母表的字符,训练时不仅使用了字符的图片,也使用了笔画的数据)来自主学习子笔画,以及子笔画之间的连接/联合出现概率等,为了对比实验,这些数据也用于pretrain deep learning models。这些用于训练的字母表以及产生的数据都不会用于接下来的evaluation task(这一步只为模型提供新的字符的图片)。学习subpart primitive:首先是根据笔画的暂停得到所有的subparts,然后经过一定规则的筛选最终得到1250个subpart的轨迹,每个subpart拟合成样条,并以5个控制点表示.
学习starting positions:开始位置通常集中在左上角,并且越早书写的笔画这一特性越明显。
4.1 理解字符的构成
在这里,我们用到的是后验概率,即给定一张图片,如何去理解它的构成。首先从图片中提取字符的骨架并得到关键点(下图a->b),
然后从最左上角的点开始查找可能的轨迹(即生成candidate parse),如图Fig S4,一共有3种轨迹,a)在交点处的角度为0,b)为28°,c)为47°,根据先验知识,通常会选择运动角度最小的轨迹,因此图a)轨迹的概率高于b)c),经过random walk,我们可以得到不同的candidate parse,也产生了这个字符的不同笔画。然后和之前一样地,根据笔画中的停顿将笔画拆分成子笔画,并且通过前面提到的笔画的generative model(也就是不同的子笔画之间是否会连续出现的那个马尔科夫过程)对拆分的过程进行打分。这样在搜索完成后,我们可以得到比较靠谱的candidate parse,也就是字符是怎么构成的。Fig 4B比较了模型最佳得分的parse和ground-truth human parse。
4.2 对新的example进行分类
Fig.4A给出了一张training image I(1)的5个最佳的parse,以及他们如何refit到不同的测试图片I(2),并计算classification score(the log posterior predictive probability),在这里更高的score说明他们更有可能属于同一类。只有当parts和relations的集合能够同时解释training和test image,一个高score才能被得到。4.3 创造新类
创造新类的意思是给定1个alphabet的几个例子,根据他们的特征创造出属于该alphabet的新类。这一点是可以实现的,我的理解是,首先对这些例子进行parse,然后重新生成“经验”,也就是说这个alphabet中最常出现的笔画数目,子笔画的样式,相互位置关系等等,然后再根据这一经验去创造新的类。
Experiments
研究者对这个AI系统进行了几项测试。5.1 One-shot classification
研究者给定1张字符图片,要求人类测试者和BPL机器从20张图片中选出和他同类的图片(如Fig 1B i所示)。人类作为skilled one-shot learners,错误率为4.5%,而BPL的错误率更好一些,3.3%。而Deep learning相关的model如convnet:13.5%error,HDmodel,34.8%error,这些模型都是在一系列计算机视觉任务上表现良好的模型,deep siamese convnet在one-shot learning任务上做了优化,其结果是8% error,误差还是比我们的结果高了2倍多。因此BPL的优势是可以在概念的学习中对隐含的因果关系进行建模。BPL的另一个关键点在于,如果没有learning to learn的机制,或者compositionality的机制,会产生较高的error(11%和14%)。no learning to learn的意思是破坏之前设计好的type level和token level生成模型的超参数,比如以token level为例,原来设计好的参数可能是让along这种位置关系的两个笔画在一定范围内进行连接,破坏后则是完全随机的一种连接方式。no compositionality的意思是说把字符看成一个整体,通过一条样条曲线进行拟合,而不是像之前一样做笔画和子笔画的拆分。5.2 Generating new examplars
人类对于one-shot learning的能力并不仅仅用来做classification。他还可以生成同一概念的新例子。研究者向BPL系统展示它从未见过的书写系统(例如,藏文)中的一个字符例子,并让它写出同样的字符。并不是让它复制出完全相同的字符,而是让它写出9个不同的变体,就像人每次手写的笔迹都不相同一样。例如,在看了一个藏文字符之后,算法能挑选出该字符用不同的笔迹写出来的例子,识别出组成字符的笔画,并重画出来。与此同时,人类测试者也被要求做同样的事情。最后,通过视觉图灵测试来比较人类的creative outputs和机器产生的例子——研究者要求一组人类裁判(来自亚马逊土耳其机器人,Amazon Mechanical Turk)分辨出哪些字符是机器写的,哪些是人类写的。如图5所示,给定人类产生的9个新样例和机器产生的样例,人类裁判挑选出人类的作品,我们称为identification(ID)level。理想情况是50% ID level,即裁判不能区分哪些是机器产生的,哪些是人产生的,最差的performance是100%,就是说人类裁判完全能够正确区分人类和机器。从Fig 6B 中看出,147个人类裁判只实现了52%的ID level,这个结果只稍稍比50%的随机概率要好一点。而对于BPL lesion来说,没有了learning to learn和compositionality,图灵测试就简单多了(80% ID level和65% ID level),因此这两条principle对于BPL具有human-like 生成模型起到了关键作用。
5.3 Generating new examplars(dynamic)
为了更准确地测试语义分析的能力(Fig 4B)我们又跑了一个dynamic version of this task,并且换了一批裁判(N=143),每个裁判会被show人类和机器写同一个字符的movie(笔画的过程),这时BPL在这一视觉图灵测试上的performance为59% ID level,不是那么理想了。如果我们再把学习到的笔画的书写顺序等先验知识去掉,结果仅为71% ID level,因此捕捉正确的动态的因果关系对于BPL来说非常重要。虽然BPL从30个background alphabets中学会学习新的character很有效,但是许多人类只需要很少的alphabet,如1个或几个,以及一些相关的drawing tasks。为了测试模型在更少的训练下的结果,我们重新训练了几个模型,只用了两个不同的子集,每个子集中包含5个background alphabets来进行训练。这时BPL 在one-shot learning问题上和之前表现差不多(两个子集的误差分别为4.3%,4.0 %error),同时deep convnet 则比之前的结果差很多(24%,22.3%).BPL在生成样例的视觉图灵测试上的结果也和之前差不多(52%和57%)。这些实验结果说明,虽然learning to learn是BPL成功的关键,模型的结构使得他能够在有限的background training中依旧能够得到很好的效果。
5.4 Generating new concepts(from type)
人类的能力不仅仅能从一个给定的concept中产生新样例,同时我们可以产生新的concept。我们通过给测试者展示10个foreign alphabet中的1个的几个例子,让他产生新的属于该alphabet的字符。如图7A所示。BPL可以通过加一个nonparametric prior在type level上得到新的类,同时复用所给的例子的stroke来保证书写风格上的一致。人类裁判(N=117)比较了人类测试者和BPL在这一任务上的结果,如图7A所示,先给裁判看i再看iii,让他判断human or machine,最终裁判只得到了49%的ID level,这和随便猜没啥区别。另外,BPL lesion(没有type-level的learning to learn)则达到了69%ID level。最后,124 个裁判比较了在完全unconstrained的情况下生成new concept(不受限于某个特定的alphabet,即Fig 7B),达到51%的ID level。BPL lesion的结果分别是68%和64%,说明compositionality和learning to learn都是通过视觉图灵测试的关键。
Discussion
总结一下,这篇文章的大致流程是:首先使用了一个background set来模拟人的经验,将background set中的字符拆分成笔画(连贯的一笔),每个笔画再拆分成若干个子笔画(笔根据笔画中的停顿),并且记录各个子笔画之间的连接关系,由此得到了一堆子笔画及其之间连接关系的分布。以上是在background set上完成的,相当于人的先验知识,产生式模型是子笔画、笔画以及相互之间关系的联合概率分布。用概率分布可以生成新的图像,也可以计算生成某个图像的概率。这种机制和人的大脑有着相似的地方。(最后这段话来自于知乎)人有大量先验知识(background set),这些知识首先会被分析并提取出各个层次的feature(part、subpart),之后大脑会尝试对这些feature进行不同的组合,包括完全不同领域的知识,并且从中筛选出有意义的组合(绝大多数都是完全没有意义的),当接收到一个全新的知识时,会与某些已经尝试过的组合非常契合,经过进一步适应,就能非常快的接受这样一个新的知识。当然人不仅可以利用先验知识准备一堆组合为新的知识服务,还可以通过内部的筛选机制,将有用的组合直接呈现给意识,也就是灵感迸发的时候。这篇工作将大脑的这种举一反三的能力运用了出来,可以说是非常有意义的,当然这篇工作中,feature的提取和组合用的是简单的拆分和条件概率的计算,对组合的筛选也是用的最简单的评分和排序,都是浅层的模型。用浅层的模型来完成复杂信息的组合和筛选是不现实的,以后如果能与深度网络结合起来,相信能有更大的突破,具有更强的举一反三地能力。

相关文章推荐
- 一个游戏程序员的学习资料
- D-Wave量子计算机有可能引爆人工智能革命吗?
- 50年后人工智能将成为人类最大的威胁
- 人工智能与智能系统的先驱人物
- 人工智能与智能系统的先驱人物
- 人工智能与智能系统的先驱人物
- 10个关于人工智能和机器学习的有趣开源项目
- 五子棋的人工智能
- 更加现实的人工智能
- 心得:基于遗传算法的虚拟捡罐子机器人
- 互联网“亚洲新时代”背后的专利保驾
- 国外程序员爱用苹果Mac电脑的10大理由
- 上帝之眼——GIS技术的决定性作用
- 【Deep learning vs BPL】思考:complex => simple => rich
- Google最新人工智能算法RankBrain的实现--写在后面的话
- 调用一款强大的人工智能平台
- 微信会成为中国大妈的下一个时尚吗?
- 研一的人工智能课程作业
- 基于FPGA的脱机手写体汉字识别系统
- 人工意识(智能)的研究方向