python实现决策树ID3算法
2015-12-22 13:06
716 查看
一、决策树概论
决策树是根据训练数据集,按属性跟类型,构建一棵树形结构。可以按照这棵树的结构,对测试数据进行分类。同时决策树也可以用来处理预测问题(回归)。
二、决策树ID3的原理
有多种类型的决策树,本文介绍的是ID3算法。
首先按照“信息增益”找出最有判别力的属性,把这个属性作为根节点,属性的所有取值作为该根节点的分支,把样例分成多个子集,每个子集又是一个子树。以此递归,一直进行到所有子集仅包含同一类型的数据为止。最后得到一棵决策树。ID3主要是按照按照每个属性的信息增益值最大的属性作为根节点进行划分。
ID3的算法思路
1、对当前训练集,计算各属性的信息增益(假设有属性A1,A2,…An);
2、选择信息增益最大的属性Ak(1<=k<=n),作为根节点;
3、把在Ak处取值相同的例子归于同一子集,作为该节点的一个树枝,Ak取几个值就得几个子集;
4、若在某个子集中的所有样本都是属于同一个类型(本位只讨论正(Y)、反(N)两种类型的情况),则给该分支标上类型号作为叶子节点;
5、对于同时含有多种(两种)类型的子集,则递归调用该算法思路来完成树的构造。
使用决策树对一下数据进行分类
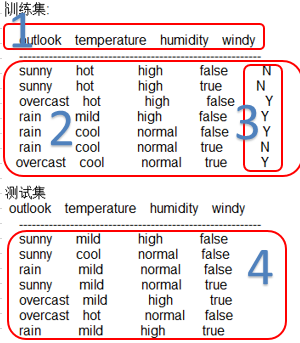
如上图:
1表示数据集的属性,有4个属性(outlook、temperature、humidity、windy);
2是二维矩阵,每行表示一个训练样本数据,每列表示各个测试样本的某个属性值(编号3除外),例如outlook这个属性有3个取值(sunny,rain,overcast)
3是各个训练样本的类型(这里只有两种类型Y,N)
4是测试样本,要求我们求出各个测试样本的类型(分类)
求解步骤
1、计算信息熵
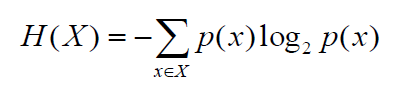
按照该公式,计算上面数据的信息熵。有上图2中测试样本的数据类型只有两种(Y,N)所以,X=[Y,N],测试数据一共有7行,期中Y类型有4个,N类型有3个。
H(X) = -p(Y)log2p(Y)-p(X)log2p(X)=-4/7*log2(4/7)-3/7*log2(3/7)
2、计算各个属性的信息增益
例如:对于测试集的第一列(属性outlook),有3种取值
属性outlook的信息增益值为:
g(X|A=”outlook”)=H(X)-H(X|A=”outlook”)

期中1公式表示的是outlook值等于sunny 的情况,2表示的是值等于overcast情况,3表示值等于rain情况。
1项中的2/7表示该值的样本有2个,总样本有7个;
2/2表示这两个样本中有2个是属于N类型,0/2是表示有0个是属于Y类型。
3、按照以上的公式,求出根节点
g(X|A=”outlook”)
g(X|A=”temperature”)
g(X|A=” humidity”)
g(X|A=”windy”)
4、在对不是同一类型的数据进行递归建树
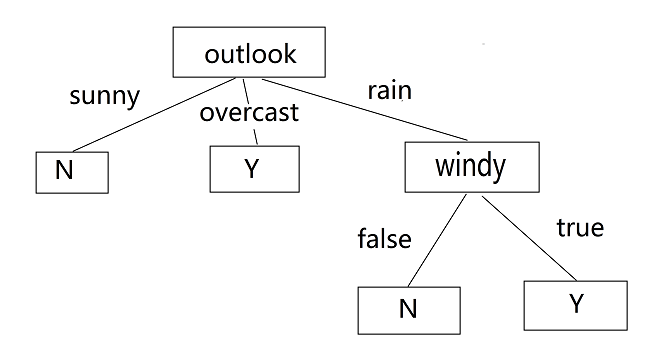
如上图,第一次求出第一个节点“outlook”,该节点有三个分支,期中第一个分支sunny的数据都是属于N类型,所归为一类;同样第二个分支overcast属于同一类型(Y),也归为一类;都标上类型符作为叶子节点。而第三个分支windy中既有N类型,也有Y类型,所以需要继续对outlook=”windy”的进行递归调用以上算法。最终得到上图的决策树。
5、对测试集按照前面建好的决策树进行分类
例如第一行测试数据的outlook属性的值是“sunny”,所以预测是属于N类型;同理第2、3…行测试样本的结果为N,Y, N, Y, Y, N。
python编程实现
(代码来自《机器学习实战》)
1、从txt文件中读取训练集数据,并生成二维列表
代码分析:
第一行:读取txt文件,每行作为一个元素组成列表复制给lines_set;
第二行:lines_set[2]里存放的是各属性名(outlook、temperature、humidity、windy);
labelLine.strip().split():为对读取到的一行字符串,按空格对字符串进行切割(并去掉字符串),labels 是存放所有属性名的列表;
lines_set[4:11]:为训练样本;
dataSet:使用二维矩阵(列表)存放训练样本的数据(包括各属性的值已经类型)
2、读取测试集数据
3、计算给定数据的熵函数
4、划分数据集,按照给定的特征划分数据集
5、选择最好的数据集划分方式
6、递归创建树
6.1、找出出现次数最多的分类名称的函数
6.2、用于创建树的函数代码
7、使用决策树对测试数据进行分类的函数
8、以上提供的是各个功能封装好的函数,下面开始调用这些函数来对测试集进行分类
注:上面代码中使用到了一些库,所以在前面import以下库
(两种import的方式,from xx import * :在该文件内使用xx里的函数就像在该文件写的函数一样,直接使用函数名即可;而import xx:要在该文件调用xx库的f()函数时,要使用xx.f()。主要是因为这两种import方式使用不同的机制。有兴趣的可以另外查资料了解具体背后的机制原理)
附:开始读取txt文件中的数据的时候,读出来的字符串有点古怪,每个单词的各个字母间自动添加了奇怪的字符,开始以为是读取方式有问题,找了很久。最后发现是编码问题,老师提供的txt文件使用的是Unicode编码,而我的编辑器里设置的是UTF-8编码(把老师提供的txt文件(Unicode编码)拷贝到编辑器中能正常打开(不会乱码)所以开始没注意到这个问题)希望以后要注意文件的编码问题。
决策树是根据训练数据集,按属性跟类型,构建一棵树形结构。可以按照这棵树的结构,对测试数据进行分类。同时决策树也可以用来处理预测问题(回归)。
二、决策树ID3的原理
有多种类型的决策树,本文介绍的是ID3算法。
首先按照“信息增益”找出最有判别力的属性,把这个属性作为根节点,属性的所有取值作为该根节点的分支,把样例分成多个子集,每个子集又是一个子树。以此递归,一直进行到所有子集仅包含同一类型的数据为止。最后得到一棵决策树。ID3主要是按照按照每个属性的信息增益值最大的属性作为根节点进行划分。
ID3的算法思路
1、对当前训练集,计算各属性的信息增益(假设有属性A1,A2,…An);
2、选择信息增益最大的属性Ak(1<=k<=n),作为根节点;
3、把在Ak处取值相同的例子归于同一子集,作为该节点的一个树枝,Ak取几个值就得几个子集;
4、若在某个子集中的所有样本都是属于同一个类型(本位只讨论正(Y)、反(N)两种类型的情况),则给该分支标上类型号作为叶子节点;
5、对于同时含有多种(两种)类型的子集,则递归调用该算法思路来完成树的构造。
使用决策树对一下数据进行分类
如上图:
1表示数据集的属性,有4个属性(outlook、temperature、humidity、windy);
2是二维矩阵,每行表示一个训练样本数据,每列表示各个测试样本的某个属性值(编号3除外),例如outlook这个属性有3个取值(sunny,rain,overcast)
3是各个训练样本的类型(这里只有两种类型Y,N)
4是测试样本,要求我们求出各个测试样本的类型(分类)
求解步骤
1、计算信息熵
按照该公式,计算上面数据的信息熵。有上图2中测试样本的数据类型只有两种(Y,N)所以,X=[Y,N],测试数据一共有7行,期中Y类型有4个,N类型有3个。
H(X) = -p(Y)log2p(Y)-p(X)log2p(X)=-4/7*log2(4/7)-3/7*log2(3/7)
2、计算各个属性的信息增益
例如:对于测试集的第一列(属性outlook),有3种取值
属性outlook的信息增益值为:
g(X|A=”outlook”)=H(X)-H(X|A=”outlook”)
期中1公式表示的是outlook值等于sunny 的情况,2表示的是值等于overcast情况,3表示值等于rain情况。
1项中的2/7表示该值的样本有2个,总样本有7个;
2/2表示这两个样本中有2个是属于N类型,0/2是表示有0个是属于Y类型。
3、按照以上的公式,求出根节点
g(X|A=”outlook”)
g(X|A=”temperature”)
g(X|A=” humidity”)
g(X|A=”windy”)
4、在对不是同一类型的数据进行递归建树
如上图,第一次求出第一个节点“outlook”,该节点有三个分支,期中第一个分支sunny的数据都是属于N类型,所归为一类;同样第二个分支overcast属于同一类型(Y),也归为一类;都标上类型符作为叶子节点。而第三个分支windy中既有N类型,也有Y类型,所以需要继续对outlook=”windy”的进行递归调用以上算法。最终得到上图的决策树。
5、对测试集按照前面建好的决策树进行分类
例如第一行测试数据的outlook属性的值是“sunny”,所以预测是属于N类型;同理第2、3…行测试样本的结果为N,Y, N, Y, Y, N。
python编程实现
(代码来自《机器学习实战》)
1、从txt文件中读取训练集数据,并生成二维列表
#读取数据文档中的训练数据(生成二维列表)
def createTrainData():
lines_set = open('../data/ID3/Dataset.txt').readlines()
labelLine = lines_set[2];
labels = labelLine.strip().split()
lines_set = lines_set[4:11]
dataSet = [];
for line in lines_set:
data = line.split();
dataSet.append(data);
return dataSet, labels代码分析:
第一行:读取txt文件,每行作为一个元素组成列表复制给lines_set;
第二行:lines_set[2]里存放的是各属性名(outlook、temperature、humidity、windy);
labelLine.strip().split():为对读取到的一行字符串,按空格对字符串进行切割(并去掉字符串),labels 是存放所有属性名的列表;
lines_set[4:11]:为训练样本;
dataSet:使用二维矩阵(列表)存放训练样本的数据(包括各属性的值已经类型)
2、读取测试集数据
#读取数据文档中的测试数据(生成二维列表)
def createTestData():
lines_set = open('../data/ID3/Dataset.txt').readlines()
lines_set = lines_set[15:22]
dataSet = [];
for line in lines_set:
data = line.strip().split();
dataSet.append(data);
return dataSet3、计算给定数据的熵函数
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {} #类别字典(类别的名称为键,该类别的个数为值)
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): #还没添加到字典里的类型
labelCounts[currentLabel] = 0;
labelCounts[currentLabel] += 1;
shannonEnt = 0.0
for key in labelCounts: #求出每种类型的熵
prob = float(labelCounts[key])/numEntries #每种类型个数占所有的比值
shannonEnt -= prob * log(prob, 2)
return shannonEnt; #返回熵4、划分数据集,按照给定的特征划分数据集
#按照给定的特征划分数据集 def splitDataSet(dataSet, axis, value): retDataSet = [] for featVec in dataSet: #按dataSet矩阵中的第axis列的值等于value的分数据集 if featVec[axis] == value: #值等于value的,每一行为新的列表(去除第axis个数据) reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet #返回分类后的新矩阵
5、选择最好的数据集划分方式
#选择最好的数据集划分方式 def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0])-1 #求属性的个数 baseEntropy = calcShannonEnt(dataSet) bestInfoGain = 0.0; bestFeature = -1 for i in range(numFeatures): #求所有属性的信息增益 featList = [example[i] for example in dataSet] uniqueVals = set(featList) #第i列属性的取值(不同值)数集合 newEntropy = 0.0 for value in uniqueVals: #求第i列属性每个不同值的熵*他们的概率 subDataSet = splitDataSet(dataSet, i , value) prob = len(subDataSet)/float(len(dataSet)) #求出该值在i列属性中的概率 newEntropy += prob * calcShannonEnt(subDataSet) #求i列属性各值对于的熵求和 infoGain = baseEntropy - newEntropy #求出第i列属性的信息增益 if(infoGain > bestInfoGain): #保存信息增益最大的信息增益值以及所在的下表(列值i) bestInfoGain = infoGain bestFeature = i return bestFeature
6、递归创建树
6.1、找出出现次数最多的分类名称的函数
#找出出现次数最多的分类名称
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]6.2、用于创建树的函数代码
#创建树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]; #创建需要创建树的训练数据的结果列表(例如最外层的列表是[N, N, Y, Y, Y, N, Y])
if classList.count(classList[0]) == len(classList): #如果所有的训练数据都是属于一个类别,则返回该类别
return classList[0];
if (len(dataSet[0]) == 1): #训练数据只给出类别数据(没给任何属性值数据),返回出现次数最多的分类名称
return majorityCnt(classList);
bestFeat = chooseBestFeatureToSplit(dataSet); #选择信息增益最大的属性进行分(返回值是属性类型列表的下标)
bestFeatLabel = labels[bestFeat] #根据下表找属性名称当树的根节点
myTree = {bestFeatLabel:{}} #以bestFeatLabel为根节点建一个空树
del(labels[bestFeat]) #从属性列表中删掉已经被选出来当根节点的属性
featValues = [example[bestFeat] for example in dataSet] #找出该属性所有训练数据的值(创建列表)
uniqueVals = set(featValues) #求出该属性的所有值得集合(集合的元素不能重复)
for value in uniqueVals: #根据该属性的值求树的各个分支
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels) #根据各个分支递归创建树
return myTree #生成的树7、使用决策树对测试数据进行分类的函数
#实用决策树进行分类 def classify(inputTree, featLabels, testVec): firstStr = inputTree.keys()[0] secondDict = inputTree[firstStr] featIndex = featLabels.index(firstStr) for key in secondDict.keys(): if testVec[featIndex] == key: if type(secondDict[key]).__name__ == 'dict': classLabel = classify(secondDict[key], featLabels, testVec) else: classLabel = secondDict[key] return classLabel
8、以上提供的是各个功能封装好的函数,下面开始调用这些函数来对测试集进行分类
myDat, labels = ID3.createTrainData() myTree = ID3.createTree(myDat,labels) print myTree bootList = ['outlook','temperature', 'humidity', 'windy']; testList = ID3.createTestData(); for testData in testList: dic = ID3.classify(myTree, bootList, testData) print dic
注:上面代码中使用到了一些库,所以在前面import以下库
from numpy import * from scipy import * from math import log import operator
(两种import的方式,from xx import * :在该文件内使用xx里的函数就像在该文件写的函数一样,直接使用函数名即可;而import xx:要在该文件调用xx库的f()函数时,要使用xx.f()。主要是因为这两种import方式使用不同的机制。有兴趣的可以另外查资料了解具体背后的机制原理)
附:开始读取txt文件中的数据的时候,读出来的字符串有点古怪,每个单词的各个字母间自动添加了奇怪的字符,开始以为是读取方式有问题,找了很久。最后发现是编码问题,老师提供的txt文件使用的是Unicode编码,而我的编辑器里设置的是UTF-8编码(把老师提供的txt文件(Unicode编码)拷贝到编辑器中能正常打开(不会乱码)所以开始没注意到这个问题)希望以后要注意文件的编码问题。

相关文章推荐
- python getopt.getopt 不能精确匹配的问题
- python 10min系列之实现增删改查系统
- 解决 “python + opencv” 不能读取视频的问题
- python之面向对象那点事
- Python函数,参数,变量
- Project Euler Problems 19-22 Python实现
- python datetime
- Flask 一个Python的微型WEB开发框架
- Python学习笔记4--列表
- 一篇文章入门Python生态系统
- Python 基础语法
- <Python for Kids>读书笔记
- python pandas
- python--requests下载图片
- Python过滤emoji
- Python控制流语句(if,while,for)
- python注意事项
- pip安装Python包到指定目录
- Python系统学习
- Python正则表达式