Spark SQL 之 Migration Guide
2015-12-16 14:18
375 查看
Spark SQL 之 Migration Guide
支持的Hive功能转载请注明出处:http://www.cnblogs.com/BYRans/
Migration Guide
与Hive的兼容(Compatibility with Apache Hive)
Spark SQL与Hive Metastore、SerDes、UDFs相兼容。Spark SQL兼容Hive Metastore从0.12到1.2.1的所有版本。Spark SQL也与Hive SerDes和UDFs相兼容,当前SerDes和UDFs是基于Hive 1.2.1。在Hive warehouse中部署Spark SQL
Spark SQL Thrift JDBC服务与Hive相兼容,在已存在的Hive上部署Spark SQL Thrift服务不需要对已存在的Hive Metastore做任何修改,也不需要对数据做任何改动。Spark SQL支持的Hive特性
Spark SQL支持多部分的Hive特性,例如:Hive查询语句,包括:
SELECT
GROUP BY
ORDER BY
CLUSTER BY
SORT BY
所有Hive运算符,包括
比较操作符(=, ⇔, ==, <>, <, >, >=, <=, etc)
算术运算符(+, -, *, /, %, etc)
逻辑运算符(AND, &&, OR, ||, etc)
复杂类型构造器
数学函数(sign,ln,cos,etc)
字符串函数(instr,length,printf,etc)
用户自定义函数(UDF)
用户自定义聚合函数(UDAF)
用户自定义序列化格式器(SerDes)
窗口函数
Joins
JOIN
{LEFT|RIGHT|FULL} OUTER JOIN
LEFT SEMI JOIN
CROSS JOIN
Unions
子查询
SELECT col FROM ( SELECT a + b AS col from t1) t2
Sampling
Explain
表分区,包括动态分区插入
视图
所有的Hive DDL函数,包括:
CREATE TABLE
CREATE TABLE AS SELECT
ALTER TABLE
大部分的Hive数据类型,包括:
TINYINT
SMALLINT
INT
BIGINT
BOOLEAN
FLOAT
DOUBLE
STRING
BINARY
TIMESTAMP
DATE
ARRAY<>
MAP<>
STRUCT<>
支持的Hive功能
下面是当前不支持的Hive特性,其中大部分特性在实际的Hive使用中很少用到。Major Hive Features
Tables with buckets:bucket是在一个Hive表分区内进行hash分区。Spark SQL当前不支持。
Esoteric Hive Features
UNION type
Unique join
Column statistics collecting:当期Spark SQL不智齿列信息统计,只支持填充Hive Metastore的sizeInBytes列。
Hive Input/Output Formats
File format for CLI: 这个功能用于在CLI显示返回结果,Spark SQL只支持TextOutputFormat
Hadoop archive
Hive优化
部分Hive优化还没有添加到Spark中。没有添加的Hive优化(比如索引)对Spark SQL这种in-memory计算模型来说不是特别重要。下列Hive优化将在后续Spark SQL版本中慢慢添加。
块级别位图索引和虚拟列(用于建立索引)
自动检测joins和groupbys的reducer数量:当前Spark SQL中需要使用“
SET spark.sql.shuffle.partitions=[num_tasks];”控制post-shuffle的并行度,不能自动检测。
仅元数据查询:对于可以通过仅使用元数据就能完成的查询,当前Spark SQL还是需要启动任务来计算结果。
数据倾斜标记:当前Spark SQL不遵循Hive中的数据倾斜标记
jion中STREAMTABLE提示:当前Spark SQL不遵循STREAMTABLE提示
查询结果为多个小文件时合并小文件:如果查询结果包含多个小文件,Hive能合并小文件为几个大文件,避免HDFS metadata溢出。当前Spark SQL不支持这个功能。
Reference
Data Types
Spark SQL和DataFrames支持的数据格式如下:数值类型
ByteType: 代表1字节有符号整数. 数值范围: -128 到 127.
ShortType: 代表2字节有符号整数. 数值范围: -32768 到 32767.
IntegerType: 代表4字节有符号整数. 数值范围: -2147483648 t到 2147483647.
LongType: 代表8字节有符号整数. 数值范围: -9223372036854775808 到 9223372036854775807.
FloatType: 代表4字节单精度浮点数。
DoubleType: 代表8字节双精度浮点数。
DecimalType: 表示任意精度的有符号十进制数。内部使用java.math.BigDecimal.A实现。
BigDecimal由一个任意精度的整数非标度值和一个32位的整数组成。
String类型
StringType: 表示字符串值。
Binary类型
BinaryType: 代表字节序列值。
Boolean类型
BooleanType: 代表布尔值。
Datetime类型
TimestampType: 代表包含的年、月、日、时、分和秒的时间值
DateType: 代表包含的年、月、日的日期值
复杂类型
ArrayType(elementType, containsNull): 代表包含一系列类型为elementType的元素。如果在一个将ArrayType值的元素可以为空值,containsNull指示是否允许为空。
MapType(keyType, valueType, valueContainsNull): 代表一系列键值对的集合。key不允许为空,valueContainsNull指示value是否允许为空
StructType(fields): 代表带有一个StructFields(列)描述结构数据。
StructField(name, dataType, nullable): 表示StructType中的一个字段。name表示列名、dataType表示数据类型、nullable指示是否允许为空。
Spark SQL所有的数据类型在
org.apache.spark.sql.types包内。不同语言访问或创建数据类型方法不一样:
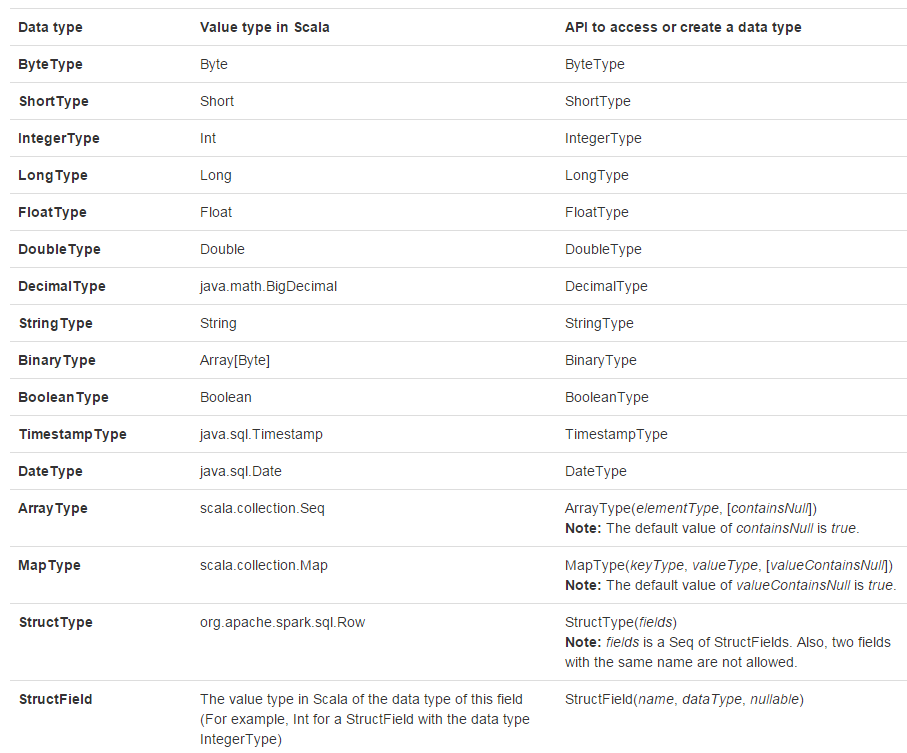
Scala
代码中添加
import org.apache.spark.sql.types._,再进行数据类型访问或创建操作。
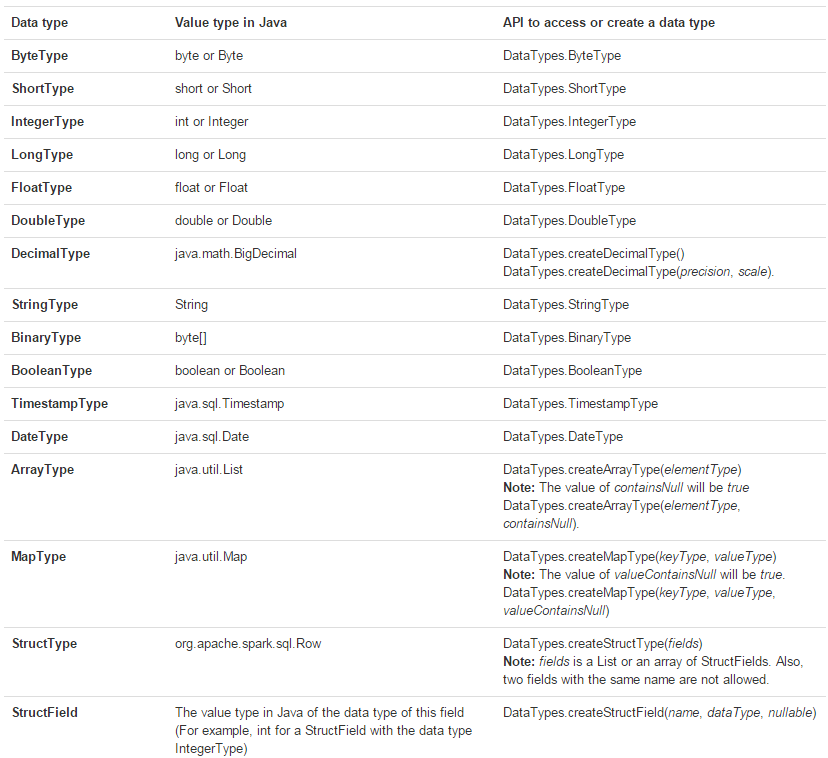
Java
可以使用
org.apache.spark.sql.types.DataTypes中的工厂方法,如下表:

相关文章推荐
- UIProgressView的使用
- iOS开发技巧(系列十八:扩展UIColor,支持十六进制颜色设置)
- [Elasticsearch] 控制相关度 (五) - function_score查询及field_value_factor,boost_mode,max_mode参数
- leetcode -- Unique Paths I &&II-- 典型DP 题目,简单要看
- 开源webUI自动测试工具利器Sahi
- UITableView学习笔记
- UUID随机字符串
- 折叠UITableView分组实现方法
- iOS学习之UICollectionVuew基本使用
- 我对UI自动化测试的理解[转]
- iOS控件——UITableView详解
- iOS开发~interface Builder(简称 IB) 界面构建器
- OpenWRT开发之——BuildPackage剖析
- Win7+VS2010环境下CEGUI 0.8.4编译过程详解
- Android UiAutomator编译与运行测试代码
- Educational Codeforces Round 2 B. Queries about less or equal elements
- Quicksort
- UIViewController的生命周期
- UINavigationBar Background Color
- 关于UI布局中的常见布局类型、控件、控件属性以及引入布局的说明