超大矩阵相乘(亿级别)的MapReduce实现思想详解
2015-12-08 14:55
260 查看
一、背景
在基于Simhash的样本同源性检测模型研究中,需要计算约444万样本simhash的两两hamming距离。简言之,难点在于完成444万样本的两两组合,约有9.8万亿种情况;其实,这个两两组合的情况可以抽象成矩阵相乘,即444万样本md5依次存入列向量A,然后取A*AT的结果矩阵的上三角/下三角即可。那么下面就讲解超大矩阵相乘的MapReduce实现思想。二、MapReduce实现思想详解
以下面矩阵相乘:A*B=C 为例。
2.1、矩阵元素解析
上述矩阵相乘,如果单机实现,算法复杂度为O(n2),当n为十万,甚至百万的时候,单机显然是无法实现的。那么用分布式的MapReduce怎么实现呢?从上面的矩阵运算可以看到,c11=a11*b11+a12*b21+a13*b31,也就是说,与c11的计算相关的元素只有矩阵A中的第一行和矩阵B中的第一列;反过来看,在矩阵运算过程中,元素b11为结果矩阵C中哪些元素的计算做过贡献呢?显然是C11,C21,C31。那么,如果我把元素b11存三份,第一份只参与C11的计算,第二份只参与C21的计算,第三份只参与C31的计算(矩阵A的同理,同一个元素也可存多份),那么可以看到,C11,C21,C31的计算过程就是相互独立的,即矩阵计算过程就可以分布实现了。
那么元素b11应该以什么形式保存,才能参与MapReduce的计算呢?
以元素C11的计算为例,如果Map阶段,以其下标为矩阵A,B中相关元素复制的key的话,那么经过Shuffle过程之后,参与C11计算的所有元素就会被聚合到同一个序列中输入到Reduce阶段,那么目的就达到了。元素解析实例如下:
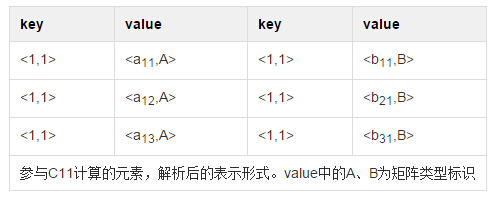
那么,矩阵A,B中的单个元素而言,应该解析成什么形式:
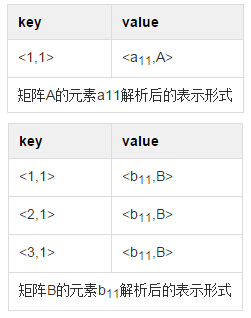
所以,一般性地,对于矩阵相乘:
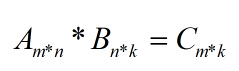
,矩阵A、B中的元素,应该解析为,该解析过程在Map端完成,经过Shuffle聚合后,元素相乘在Reduce端完成。

2.2、Map端数据分块
由上一节可知,矩阵元素解析在Map端完成,即矩阵A中的元素aij应该解析为key=(i,p) 其中p=(1,2,…,k),value=(aij,A),即时间复杂度为O(k)。但是,当矩阵超大的情况下,即k值超大,那么map仅对单一元素就要复制百万,千万甚至上亿遍,这样的话,一个Map执行的时间非常长,那么许多Map的块大小都将被填满,一个Map的执行时间就是无底洞了。因此,才有了本节。优化思想举例如下:对于key=(i,p) 其中p=(1,2,…,k),value=(aij,A),如果k=1000万,对于Maps设置一个统一的Block_Size=1000,即将1000万分成1000份,表示成如下的形式:
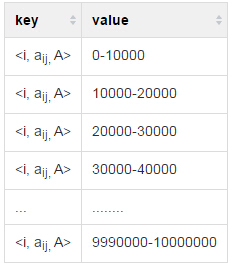
由上图可见,每一个分块(每一行)的数据步长为10000,仍然比较大,可以再次对每行数据进行分块,原理一样,不再赘述。
一般而言,百万级的矩阵相乘经过两次Map端数据分块便可。因为经过第一次分块后,输出的数据量会剧增,导致第二次分块速度较慢。所以并不是分块次数越多越好。几十万的矩阵相乘,一次数据分块即可。千万或亿级别的矩阵相乘,3-4次数据分块便可。Block_Size的一般取[1000,5000],视情况而定。
三、性能实测
集群节点35台,实测数据如下: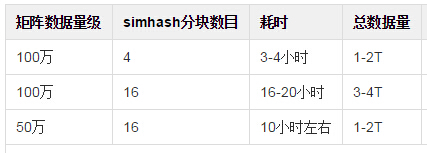
参考文献:
1.Detecting Near-Duplicates for Web Crawling

相关文章推荐
- Hadoop_2.1.0 MapReduce序列图
- MongoDB中的MapReduce简介
- MongoDB学习笔记之MapReduce使用示例
- MongoDB中MapReduce编程模型使用实例
- MapReduce中ArrayWritable 使用指南
- Java函数式编程(七):MapReduce
- java连接hdfs ha和调用mapreduce jar示例
- 用PHP和Shell写Hadoop的MapReduce程序
- JavaScript mapreduce工作原理简析
- mongodb mapredReduce 多个条件分组(group by)
- HBase基本原理
- HDFS DatanodeProtocol——sendHeartbeat
- HDFS DatanodeProtocol——register
- Hadoop集群提交作业问题总结
- Hadoop源码分析 HDFS ClientProtocol——addBlock
- Hadoop源码分析HDFS ClientProtocol——create
- Hadoop源码分析FSNamesystem几个重要的成员变量
- Hadoop源码分析HDFS ClientProtocol——getBlockLocations
- Hadoop源码分析HDFS Client向HDFS写入数据的过程解析
- ZooKeeper基本理解