KMP算法--c语言实现
2015-12-03 11:02
435 查看
KMP算法
字符串不回溯搜索词不断移位
搜索词移位时查看是否有重复子串
KMP算法过程
1.
首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符(不断向前移动),与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,按照暴力解法(穷举法),将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把”搜索位置”移到已经比较过的位置,重比一遍。
7.

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。KMP算法的思想是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置(不回溯),继续把它向后移,这样就提高了效率。
8.
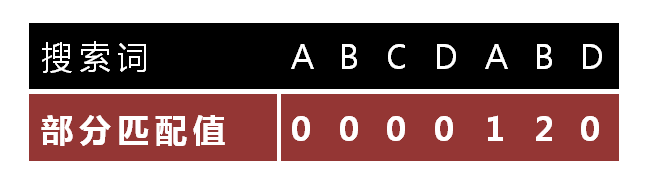
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍。
9.

已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符B对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
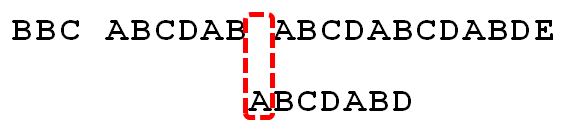
因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:”前缀”和”后缀”。 “前缀”指除了最后一个字符以外,一个字符串的全部头部组合;”后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
15.
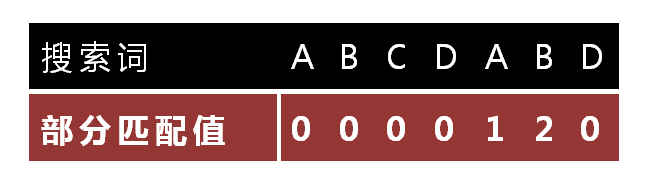
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
- “A”的前缀和后缀都为空集,共有元素的长度为0;
- “AB”的前缀为[A],后缀为,共有元素的长度为0;
- “ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- “ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- “ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
- “ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
- “ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
“部分匹配”就是([b]判断子串是否有重复)字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。
简易实现代码(不喜勿喷):
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#define ERROR 0;
#define TRUE 1;
//初始化数据
int InitData(char **source,char **target,int **value){
char ch;
int i = 0;
(*source) = (char *)malloc(sizeof(char) *100);
(*target) = (char *)malloc(sizeof(char) *100);
(*value) = (int *)malloc(sizeof(int) *100);
if(!(*source) || !(*target) || !(*value))return ERROR;
printf("请输入要输入源字符串,以#结束:\n");
while((ch = getchar())!='#'){
(*source)[i++] = ch;
(*source)[i] = '\0';
}
getchar(); //抵消缓冲
i = 0; //重置
printf("请输入要匹配的字符串,以#结束:\n");
while((ch = getchar())!='#'){
(*target)[i++] = ch;
(*target)[i] = '\0';
}
//初始化value数组
for(i = 0; i < 100;i++){
(*value)[i] = 0;
}
return TRUE;
}
//得出target中的匹配值
int GetValue(char * target, int *value){
char *head,*tail;
int temp;
//ABCDABD
//ABCDAB
int i = 1,j = 0;
head = (char *)malloc(sizeof(char) *100);
tail = (char *)malloc(sizeof(char) *100);
if(!head || !tail)return ERROR;
for(i = 1;i<strlen(target);i++){ //从头到尾
j = 0;
while(target[j]!='\0'){ //复制到临时数组
head[j] = target[j];
tail[j] = target[j];
j++;
head[j]='\0';
tail[j] = '\0';
}
head[i] = '\0';
tail[i+1] = '\0';
for(j = 0;j<i;j++){
if(strcmp(head,tail+1+j)==0){ //比较
value[i] = strlen(head);
break;
}
temp = strlen(head) - 1;
head[temp] = '\0';
}
}
}
//KMP处理过程
int KMP(char *source,char *target,int *value){
int i = 0,j = 0;
while(i < strlen(source)){ //不回溯,source走到尾
if(source[i] == target[j] && j<strlen(target)){
i++;
j++;
}else if(j>=strlen(target)){
printf("找到...");
return TRUE;
}else if(source[i]!=target[j]){
if(j==0){
j=0;
i++;
}else{
j = value[j-1];
}
}
}
if(i >=strlen(source) && j>=strlen(target))printf("找到...");
else printf("未找到...");
return ERROR;
}
int main(){
char *source,*target; //source源字符串,target要匹配的字符串
int *value; //存放匹配值
int i = 0;
InitData(&source,&target,&value); //初始化字符串
GetValue(target,value);
KMP(source,target,value);
}

相关文章推荐
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析
- C++实现汉诺塔算法经典实例
- PHP实现克鲁斯卡尔算法实例解析
- C#获取关键字附近文字算法实例