哈弗曼树讲解---c语言实现
2016-01-10 22:46
239 查看
哈夫曼树
哈弗曼树定义
赫夫曼树:又称为最优二叉树,它是一类带权路径长度最短的二叉树。路径:从一个结点到另一个结点之间的分支序列构成两个结点 之间的路径。
路径长度:连接两结点的路径上的分支数。
树的路径长度:从根结点到各结点的路径长度之和 (完全二叉树就是这种路径长度最短的二叉树)。
结点的带权路径长度:从根结点到该结点之间的路径长度与结点上权的乘积。
树的带权路径长度:树中所有叶子结点的带权路径长度之和。即树的各叶子结点(设为n个)所带的权值 wi 与从根到该叶子结点的路径长度 li 的乘积的和。
WPL = w1 * l1 + w2 * l2 +…+wn*ln(n = 1,2,…n)
假设有n 个权值 {w1, w2, …, wn},试构造一棵有n个叶子结点的二叉树,每个叶子结点带权为wi,则其中带权路径长度WPL最小的二叉树称作最优二叉树或赫夫曼树。
构造哈夫曼树算法步骤
1.根据给定的 n 个权值 {w1, w2, …, wn}, 构造 n 棵二叉树的集合F = {T1, T2, … , Tn},其中每棵二叉树中均只含一个带权值为 wi 的根结点,其左、右子树为空树;2. 在 F 中选取其根结点的权值为最小的两棵二叉树,分别作为左、右子树构造一棵新的二叉树,并置这棵新的二叉树根结点的权值为其左、右子树根结点的权值之和。
3. 从F中删去这两棵树,同时加入刚生成的新树;
4. 重复 (2) 和 (3) 两步,直至 F 中只含一棵树为止。
哈夫曼树应用
利用赫夫曼树可以构造一种不等长的二进制编码,并且构造所得的赫夫曼编码是一种最优前缀编码,即使所传电文的总长度最短。(如图所示传输电文过程)
例:传输电文ABAACCADACCD
等长编码与解码过程
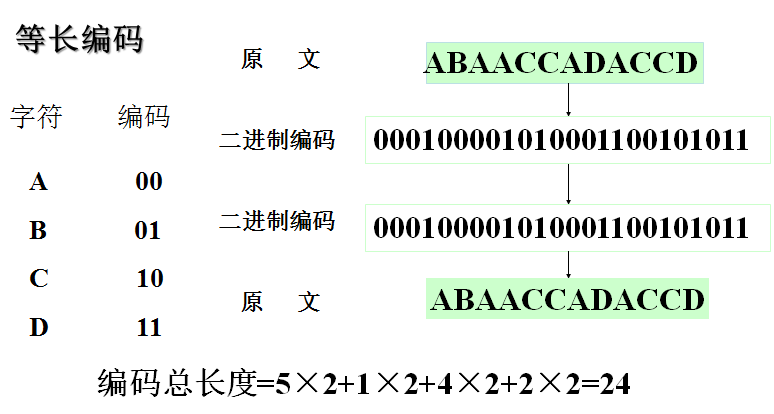
变长编码与解码过程

哈夫曼编码过程
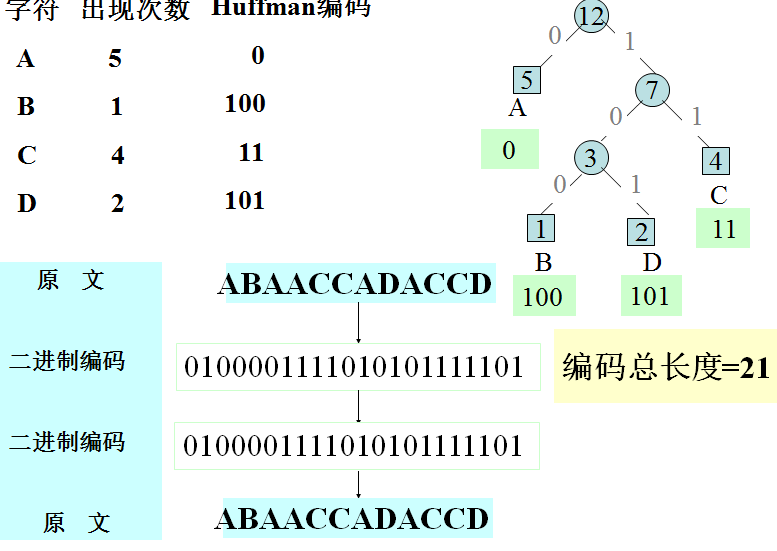
在上述三种编码中,等长编码占用长度太大,而变长编码又在解码中会出现歧义,导致解码不唯一。在Huffman树中,字符i的Huffman编码对应根到叶子结点i的路径。因为叶子结点是没有子孙结点的,故根到一个叶子结点的路径不可能是根到另一个叶子结点的路径的前一段,即一个叶子结点对应的字符的Huffman编码不是另一个叶子结点对应的字符的Huffman编码的前缀,从而没有一个字符的Huffman编码是另一个字符的Huffman编码的前缀,所以Huffman编码是前缀编码,即Huffman编码是正确的。
代码实现(C语言)
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#define MAXSIZE 256
#define ERROR 0
#define TRUE 1
typedef struct HfNode{
char data;
int weight;
int rchild,lchild,parent;
char *code;
}HfNode,*Hftree;
//选择两个最小的节点
void selectTwo(HfNode *hfArray, int count,int * pos1,int * pos2){
int i =0,min = 0,min2 = 0;
//选择第一最小
for(i = 1; i<=count;i++){
if(hfArray[i].parent == 0){
if(min == 0){ //初始化
min = hfArray[i].weight;
(*pos1) = i;
}
if(hfArray[i].weight < min){
min = hfArray[i].weight;
(*pos1) = i;
}
}
}
//min2 = min; (*pos2) = (*pos1);
for(i = 1;i<=count;i++){
if(hfArray[i].parent ==0 && i != (*pos1)){
if(min2==0){
min2 = hfArray[i].weight;
(*pos2) = i;
}
if(hfArray[i].weight < min2){
min2 = hfArray[i].weight;
(*pos2) = i;
}
}
}
}
Hftree BulidHuffman(char *sourceStr,int *hfcount){
int i = 0,s1 = 0,s2 = 0,j = 0; int k = 1,count = 0; //count叶子节点个数
int *pattern = (int *)malloc(sizeof(int) * MAXSIZE);
Hftree hfmArray = (Hftree)malloc(sizeof(HfNode) * (MAXSIZE *2)); //最大容量
for(i = 0;i<=2*MAXSIZE;i++){ //初始化
hfmArray[i].code = (char *)malloc(sizeof(char) *MAXSIZE);
hfmArray[i].lchild = 0;
hfmArray[i].parent = 0;
hfmArray[i].rchild = 0;
hfmArray[i].weight = 0;
}
for(i = 0;i<MAXSIZE;i++){ //初始化
pattern[i] = 0;
}
for(i = 0; i<strlen(sourceStr);i++){ //统计词频
pattern[(int)sourceStr[i]]++;
} /*for*/
for(i = 0;i<MAXSIZE;i++){ //叶子节点
if(pattern[i] !=0){
hfmArray[k].data = (char)i;
hfmArray[k].weight = pattern[i];
k++;
}
}
count = k - 1; //总数
j = count;
printf("总数:%d\n",count);
for(i = 0; i<j -1;i++){ //迭代次数
selectTwo(hfmArray,count,&s1,&s2);
hfmArray[k+i].weight = hfmArray[s1].weight + hfmArray[s2].weight;
hfmArray[k+i].lchild = s1; hfmArray[k+i].rchild = s2;
hfmArray[s1].parent = k+i;hfmArray[s2].parent = k+i;
count++;
}
(*hfcount) = count;
return hfmArray;
}
void traverse(Hftree hArray,int head,char *code,int pos){
if(hArray[head].lchild == 0 && hArray[head].rchild == 0){
code[pos] = '\0';
strcpy(hArray[head].code,code);
return;
}
if(hArray[head].lchild !=0){
code[pos] = '0';
code[pos+1] = '\0';
traverse(hArray,hArray[head].lchild,code,pos+1);
}
if(hArray[head].rchild != 0){
code[pos] = '1';
code[pos+1] = '\0';
traverse(hArray,hArray[head].rchild,code,pos+1);
}
}
//创建huffman编码
void BuildHffmanCode(Hftree hArray,int count){
int head1 = 0,i = 0;
char *code = malloc(sizeof(char) * MAXSIZE);
for(i = 1;i<=count;i++){
if(hArray[i].parent==0){
head1 = i;
break;
}
}
traverse(hArray,head1,code,0);
}
void encode(Hftree hfTree,char *str,int count){
int i =0,j = 0;
for(i = 0;i < strlen(str);i++){
for(j = 1;j<=count/2 +1;j++){
if(str[i] == hfTree[j].data){
//printf("%c:",str[i]);
printf("%s",hfTree[j].code);
}
}
}
}
void decode(Hftree hfArray,char *target,int count){
int i =0,head = 0,j = 0;
for(i = 1;i<=count;i++){
if(hfArray[i].parent==0){
head = i;
break;
}
}
printf("\n解码内容:");
j = head;
for(i = 0; i<strlen(target);i++){
if(target[i]=='0'){
j = hfArray[j].lchild;
if(hfArray[j].lchild == 0&& hfArray[j].rchild ==0 && j!=0){
printf("%c",hfArray[j].data);
j = head;
}
}
if(target[i] == '1'){
j = hfArray[j].rchild;
if(hfArray[j].lchild == 0&& hfArray[j].rchild ==0 && j!=0){
printf("%c",hfArray[j].data);
j = head;
}
}
}
printf("\n");
if(j!=head){
printf("要解码的字符串不符合要求....");
}
}
void main(){
int hfcount = 0;
int i = 0;
Hftree hfTree = BulidHuffman("zhang",&hfcount);
BuildHffmanCode(hfTree,hfcount);
encode(hfTree,"zhang",hfcount); //编码
decode(hfTree,"100011001111",hfcount); //解码
}

相关文章推荐
- AVL树-自平衡二叉查找树(Java实现)
- C语言二叉树的非递归遍历实例分析
- 使用C语言构建基本的二叉树数据结构
- C++非递归队列实现二叉树的广度优先遍历
- C#使用前序遍历、中序遍历和后序遍历打印二叉树的方法
- C#非递归先序遍历二叉树实例
- C++非递归建立二叉树实例
- C语言实现找出二叉树中某个值的所有路径的方法
- C++实现二叉树遍历序列的求解方法
- C语言实现二叉树遍历的迭代算法
- 用C语言判断一个二叉树是否为另一个的子结构
- C++实现二叉树非递归遍历方法实例总结
- C++二叉树结构的建立与基本操作
- 深入遍历二叉树的各种操作详解(非递归遍历)
- JavaScript数据结构和算法之二叉树详解
- java使用归并删除法删除二叉树中节点的方法
- Java中二叉树数据结构的实现示例
- Java的二叉树排序以及遍历文件展示文本格式的文件树
- python数据结构之二叉树的建立实例
- python数据结构树和二叉树简介