一张图说明访问网站的流程
2015-11-21 11:53
561 查看
一张图说明访问网站的流程
最近看了一些关于Web请求资源方面的知识,自己总结了一个流程图,描述了打开浏览器访问一个网站到网站被渲染出来的流程,希望对大家的学习有所帮助~另外,给大家推荐一款画图很好用的Chrome插件 Gliffy ,我博客里的图大部分都是用它画的,非常的好用,而且是离线的,大家可以试试。
因为是流程图的原因,大体的流程是OK的,但是其实里面还有一些细节没有涉及到,还请大神多多补充~
网站访问流程
浏览器不管是访问JSP、PHP还是ASP.NET,整体流程几乎是一样的。1.解析主机名
浏览器拿到网址之后首先会将主机名解析出来,如http://www.example.com/hello.html则会将主机名www.example.com解析出来。2.查找ip
根据主机名,会首先查找IP,首先查询hosts文件,成功则返回其对应ip地址,如果没有查询到,则去查询DNS服务器,成功就会返回ip,否则会报告连接错误。在host中有这么几句
# localhost name resolution is handled within DNS itself. # 127.0.0.1 localhost
所以访问localhost是本机ip,如果这里改掉ip,localhost就会访问其他的ip
比较有意思的是,如果把localhost改成百度,那么访问百度的时候就会访问本机ip
这里是有一些安全机制的,浏览器是会提醒host文件异常的。
3.发送http请求
浏览器会把自身相关信息与请求相关信息封装成HTTP请求消息改送给服务器。GET / HTTP/1.1 Host: www.csdn.net Connection: keep-alive Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.99 Safari/537.36 Accept-Encoding: gzip, deflate, sdch Accept-Language: zh-CN,zh;q=0.8 If-None-Match: W/"5617e6e2-1947a" If-Modified-Since: Fri, 09 Oct 2015 16:10:10 GMT Cookie: uuid_tt_dd=-2336166380439124030_20150919; .......
4.服务器处理请求
服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败就会返回大名鼎鼎的404,在服务器监测到请求不存在的资源后,可以按照程序员设置的跳转到别的页面。所以有各种各样的404错误页面。在服务器请求资源的过程中,如php文件会在服务器运行之后再返回。所以php等后台脚本是在服务器运行的。
5.服务器返回HTTP响应
服务器会将请求的资源封装成http响应浏览器得到返回数据后可以会提取数据,然后调用解析内核进行翻译,最后显示出页面。
之后浏览器会对其引用的文件比如图片,CSS,JS等文件不断进行上述过程,直到所有文件都被下载下来之后,网页就会显示出来。
网站访问流程图
为了让大家看得更清楚,就加了一个标签,图片可能会横向出去,但是也比看不清强。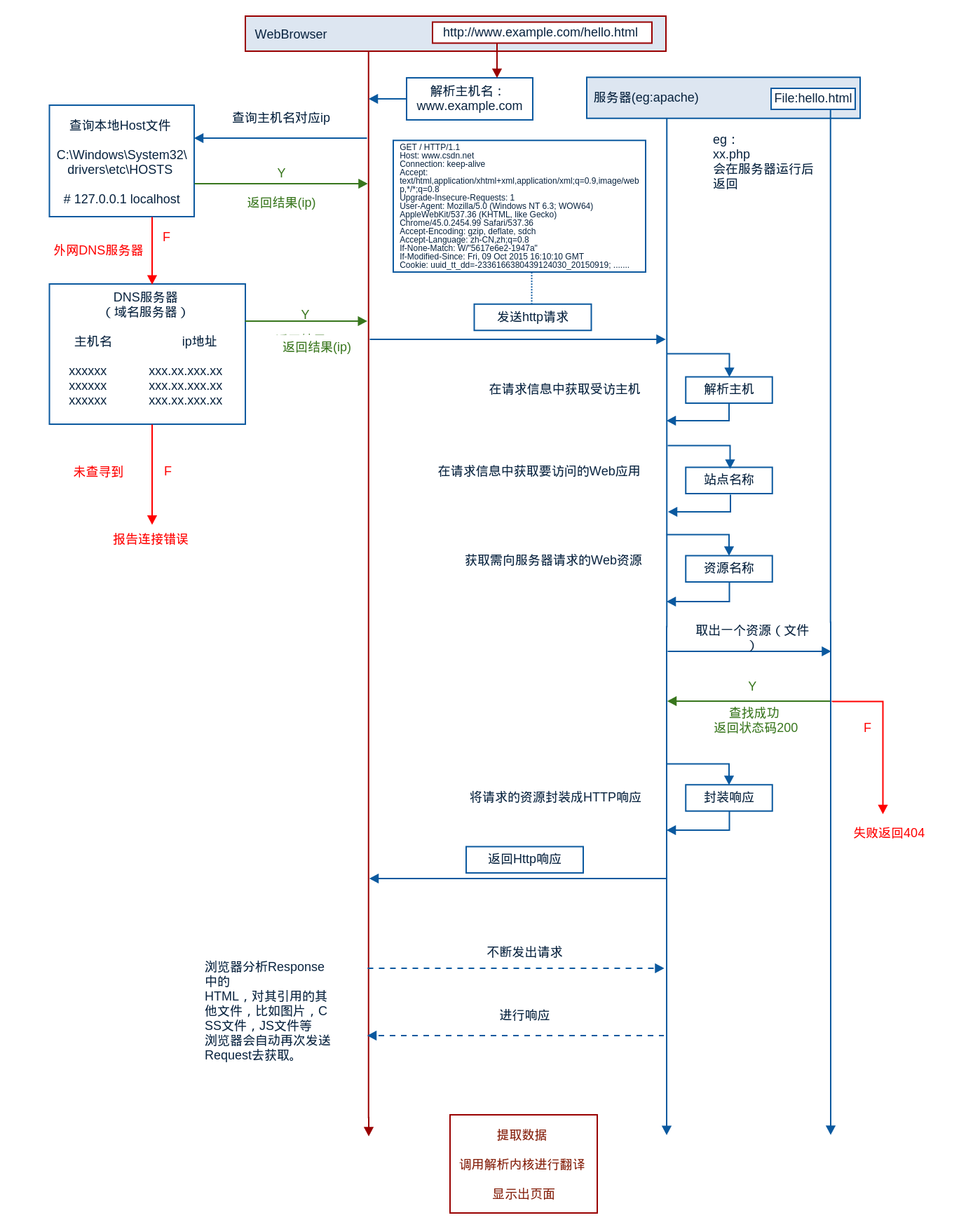
" title="">
这里附上原图以及Gliffy 原文件的下载地址:
http://download.csdn.net/detail/sunmc1204953974/9287599
Gliffy文件需要使用Chrome插件Gliffy打开
希望对大家的学习有所帮助~

相关文章推荐
- Android清洁架构(一)
- 网站部署之~阿里云系列汇总
- MVC与三层架构区别
- 浅析三层架构与MVC模式的区别
- 服务器架构图
- [Django架构流程分析]请求处理机制其三:view层与模板解析
- [Django架构流程分析]请求处理机制其二:Django中间件的解析
- [Django架构流程分析]请求处理机制其一:进入Django前的准备
- [笔记-架构探险]框架优化与功能扩展3.2.安全框架shiro、提供安全控制特性
- HEVC算法和体系结构:编码结构之编码时的分层处理架构
- HEVC算法和体系结构:编码结构之编码时的分层处理架构
- 编译器架构的王者LLVM——(10)变量的存储与读取
- 网站开发进阶(十六)错误提示:Multiple annotations found at this line:- basePath cannot be resolved to a variable
- 网站开发进阶(十六)错误提示:Multiple annotations found at this line:- basePath cannot be resolved to a variable
- 网站开发进阶(十五)JS基础知识充电站
- 网站开发进阶(十五)JS基础知识充电站
- Yet Another Computer Vision Index To Datasets (YACVID)图像库索引网站
- 网站开发进阶(十四)JS实现二维码生成
- 网站开发进阶(十四)JS实现二维码生成
- 架构探险——Android MVP模式浅析