Hadoop基本架构之HDFS和MapReduce(上)
2015-11-18 22:43
465 查看
可自由转载,转载请在文章开头处注明来源。格式: 用户名 + 文章链接。本篇文章为:TiuVe2 + http://blog.csdn.net/tiu_velenjdong/article/details/49914321
请支持原创,谢谢~
摘自《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》
Hadoop是一个由Apache基金会所支持的分布式基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群进行高速运算和存储。
Hadoop由两部分组成,分别是分布式文件系统和分布式计算框架MapReduce。其中,分布式文件系统主要用于大规模数据的分布式存储,而MapReduce则构建在分布式文件系统之上,对存储在分布式文件系统中的数据进行分布式计算。
在Hadoop中,MapReduce底层的分布式文件系统是独立模块,用户可按照约定的一套接口实现自己的分布式文件系统,然后经过简单配置后,存储在该文件系统上的数据便可以被MapReduce处理。Hadoop默认使用的文件系统是HDFS(Hadoop Distributed File System)。
一. HDFS架构
HDFS是一个具有高容错性的分布式文件系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS总体上采用了master/slave(主从)架构,主要由以下几个部件组成:Client、NameNode、Secondary NameNode和DataNode。其架构如下图所示:
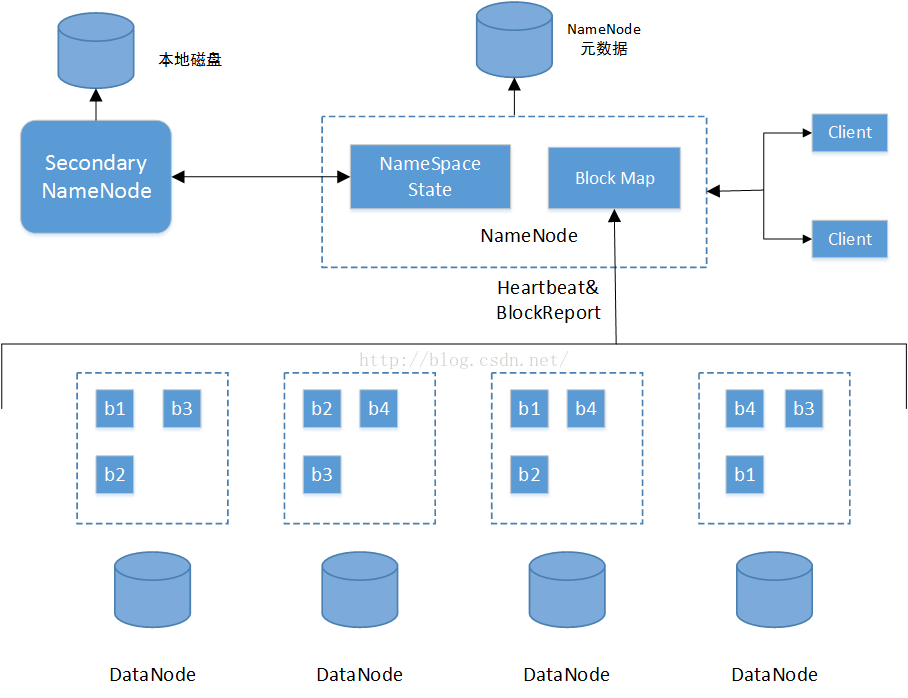
各部分组件功能如下:
(1)Client
Client通过与NameNode和DataNode交互从而访问HDFS中的文件。Client提供了类似POSIX的文件系统接口供用户使用。
(2)NameNode
整个Hadoop集群中只有一个NameNode。它是整个系统的总管,负责HDFS的目录树和相关的文件元数据信息。这些信息以“fsimage”(HDFS元数据镜像文件)和“editlog”(HDFS文件改动日志)两个文件形式存储在本地磁盘,当HDFS重启时重新构造出来的。此外,NameNode还负责监控各个DataNode的健康状态,一旦发现有DataNode宕掉,则将该DataNode移出HDFS并重新备份其上面的数据。
(3)Secondary NameNode
Secondary NameNode最重要的任务不是为NameNode元数据进行热备份,而是定期合并fismage和edits日志,并传输给NameNode。为了减小NameNode压力,NameNode自己不会合并fismage和edits,并将文件存储到磁盘上,而是由Secondary NameNode完成。
(4)DataNode
一般而言,每个Slave节点上安装一个DataNode,它负责实际的数据传输,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为64MB。当用户上传一个较大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode;同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认是3,该参数可配置)不同的DataNode上,这种文件切割后存储的过程是对用户透明的。
请支持原创,谢谢~
摘自《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》
Hadoop是一个由Apache基金会所支持的分布式基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群进行高速运算和存储。
Hadoop由两部分组成,分别是分布式文件系统和分布式计算框架MapReduce。其中,分布式文件系统主要用于大规模数据的分布式存储,而MapReduce则构建在分布式文件系统之上,对存储在分布式文件系统中的数据进行分布式计算。
在Hadoop中,MapReduce底层的分布式文件系统是独立模块,用户可按照约定的一套接口实现自己的分布式文件系统,然后经过简单配置后,存储在该文件系统上的数据便可以被MapReduce处理。Hadoop默认使用的文件系统是HDFS(Hadoop Distributed File System)。
一. HDFS架构
HDFS是一个具有高容错性的分布式文件系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS总体上采用了master/slave(主从)架构,主要由以下几个部件组成:Client、NameNode、Secondary NameNode和DataNode。其架构如下图所示:
各部分组件功能如下:
(1)Client
Client通过与NameNode和DataNode交互从而访问HDFS中的文件。Client提供了类似POSIX的文件系统接口供用户使用。
(2)NameNode
整个Hadoop集群中只有一个NameNode。它是整个系统的总管,负责HDFS的目录树和相关的文件元数据信息。这些信息以“fsimage”(HDFS元数据镜像文件)和“editlog”(HDFS文件改动日志)两个文件形式存储在本地磁盘,当HDFS重启时重新构造出来的。此外,NameNode还负责监控各个DataNode的健康状态,一旦发现有DataNode宕掉,则将该DataNode移出HDFS并重新备份其上面的数据。
(3)Secondary NameNode
Secondary NameNode最重要的任务不是为NameNode元数据进行热备份,而是定期合并fismage和edits日志,并传输给NameNode。为了减小NameNode压力,NameNode自己不会合并fismage和edits,并将文件存储到磁盘上,而是由Secondary NameNode完成。
(4)DataNode
一般而言,每个Slave节点上安装一个DataNode,它负责实际的数据传输,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为64MB。当用户上传一个较大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode;同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认是3,该参数可配置)不同的DataNode上,这种文件切割后存储的过程是对用户透明的。

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- 单机版搭建Hadoop环境图文教程详解
- 插件管理框架 for Delphi(一)
- C#分布式事务的超时处理实例分析
- 使用CSS框架布局的缺点和优点小结
- Erlang分布式节点中的注册进程使用实例
- hadoop常见错误以及处理方法详解
- 列举PHP的Yii 2框架的开发优势
- Windows窗体的.Net框架绘图技术实现方法
- 浅谈JavaScript 框架分类
- 轻量级javascript 框架Backbone使用指南
- javascript实现框架高度随内容改变的方法
- JS刷新框架外页面七种实现代码
- 超赞的动手创建JavaScript框架的详细教程
- 简单介绍不用库(框架)自己写ajax
- asp.net4.0框架下验证机制失效的原因及处理办法