tornado 学习笔记5 构建Tornado网站应用
2015-10-29 11:47
639 查看
一个Tornado 网站应用通常由一个或多个RequestHanlde的子类、一个负责将请求路由至handlers的Application以及一个启动服务器的main()函数等组成。
一个最小的“hello world”示例:
路由表URLSpec对象集合(或者元组),包含一个正则表达式和Handler类。如果正则表达式中包含捕获组,这些组将会是路径参数(path arguments),而且这些捕获的组的值会传递hanlder的Http方法的参数中。如果将字典对象作为第三个参数传递的话,这个参数的值将会传递给RequestHandler的initialize的参数。最后,URLSpec可以有个名称,可以通过Request.reverse_url得到。
示例:
根路径被映射至MainHanlder.而“/story/数字”格式的请求则被映射成StoryHandler.这个数字会当成是字符串传递给StoryHanlder的get方法。
在游览器中输入http://localhost:8888/
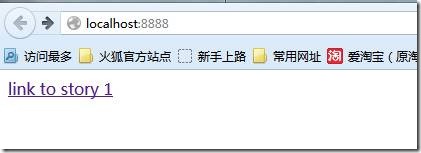
单击“link to story 1”之后,
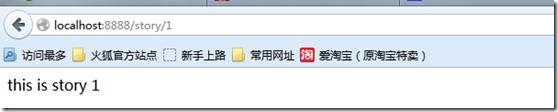
Application 构造函数有很多关键字参数,用来自定义应用程序的行为。具体请参考Application.settings查看完整的设置参数列表。
在hanlder中,调用RequestHanlder.render或者RequestHanlder.write等方法来产生响应。render() 方法通过名称加载一个模板,并渲染模板。write() 方法而是针对针对非模板的输出,接收字符串、字节和字典(字典必须编码成JSON格式)等参数。
在RequestHandler类中,定义了很多可以被子类重载的方法。所以在开发自身的应用程序时,通常会定义一个BaseHanlder类去重写write_error 和 get_current_user等方法,然后子类继承BaseHanlder而非RequeseHanlder。
示例
用HTML表单格式的请求数据会被解析,而且通过调用方法可以获取,比如get_query_argument和get_body_argument方法。
而如果表单中字段有多个值,可以调用get_query_arguments和get_body_argumens方法。
表单的上传的文件可以通过self.request.files获取。每个每件对象是一个字典,格式为{“filename”:..,”content_type”:..,”body”:…}.只有当文件通过form wrapper方式(比如Content-type的类型为multipart/form)上传时,files属性值才存在。如采用form wrapper格式的话,上传的数据可以通过self.request.body属性获取。默认情况下,上传的文件会缓存在内存中。如果你处理的文件太大以至于不能很好地保存在内存中时,请查看stream_request_body类装饰器。
由于HTML表单编码的怪异性,Tornado不会将不同类型的输入参数组合一起。在特定情况下,我们不会去解析JSON请求体。应用如果喜欢用JSON去替代表单编码(form-encoding)的话,可以去重写prepare方法去解析请求。如下:
1. 一个新的RequestHandler对象被创建
2. Initialize()被调用,参数的值从Application对象的配置中获取。Initialize一般只保存这些参数至成员变量中,不会产生任何输出或者调用方法比如send_error.
3. prepare() 被调用。这个的实现最好共享放置在基础类中,供其他子类继承,因为不管任何的HTTP方法被使用,prepare方法都会被调用;prepare可以会产生输出,如果调用了finish(或者redirect等)方法,请求处理过程结束。
4. get(),post(),put()等任一一个方法被调用,如果URL正则表达式包含了捕获组,这些捕获的组的值都会传递给这些方法的参数;
5. 当请求处理结束后,on_finish()方法被调用。对于同步的handler,当get()(举个例子)方法返回后,被立即调用on_finish方法。
通常情况下,重写最多的方法包括:
l write_error . 给用户输出错误页面的HTML;
l On_connection_close 当用户客户端断开连接是调用。应用可以选择去监听断开,然后去停止一些处理过程。、
l get_current_user. 获得当前用户。
l get_user_locale .针对当前用户,返回Locale对象
l set_default_headers .在响应中添加额外的头部。(比如自定义的服务头部)
在调试模式下,默认的错误页面包括堆栈跟踪(stack trace),在其他情况下返回一行错误的描述(比如:“500:Internal Server Error”)。为了产生自定义的错误页面,重写request.write_error方法(可能放在供其他handlers继承的基类中)。当被异常导致错误时,exc_info 被作为关键字参数传递(注意,这个异常不能保证是当前在sys.exc_info的异常,所以write_error必须使用比如traceback.format_exception 替代traceback.format_exc)。
另外一种产生错误页面的方式为调用set_status方法,而不是write_error,然后写响应以及返回。特殊的tornado.web.Finish异常被触发会终止hanlder,而不 会调用write_error。
针对404错误,使用在Application setting的default_handler_class来处理。这个handler必须重写prepare方法。根据上面的描述,这将会产生一个错误页面,要么触发HTTPError(404)错误以及重写write_error,要么调用self.set_status(404)然后在prepare中直接产生响应。
在实现的hanlder中使用self.redirect方法可以重定向到任何地方。这个方法还有一个参数permanent,用来指示这个重定向是否是永久的。这个参数的默认值为False,会产生302 Found状态编号的响应,而且特别适合像POST()请求处理成功后的重定向。如果permanent这个参数值为True, 301 Moved Permanetly状态编码会返回给用户。
RedirectHandler ,允许用户可以在Application路由表中配置重定向的链接。比如下面一个例子,配置了单个静态重定向。
RedirectHanlder 同样支持正则表达式的情形。下面的规则定义,可以使以/pictures/开头的请求重定向至以/photos/为前缀的请求。
不像RequestHanlder.redirect方法,RedirectHandler默认采用永久的重定向,即permanent属性为True.这是应为路由表在运行时不能改变,而在hanlder中使用的重定向地址在逻辑上可以会改变。如果要用RedirectHandler发送一个临时的重定向,在RedirectHandler初始化参数中将permanent设置成False.
使hanlder成为异步的最简单的方式就是使用coroutine装饰器。使用yield关键字可以执行非阻塞的I/O操作,直到coroutine已经返回后,才能将响应返回给用户端。
在有些情况下,coroutines没有采用回调的方式方便,这种回调方式是采用tornado.web.asynchrounous装饰器。当使用这个装饰器时,响应不会自动发送,请求会保持打开的状态直到回调函数调用了RequestHandler.finish方法。应用必须保证这个方法被调用,不然用户的游览器将会简单地暂停。
下面是个例子,使用内置的 AsyncHttpClient调用FriendFeed Api。
当get()方法返回时,这个请求没有结束。当最后调用on_response 方法之前,这个请求一直都是打开的,当调用了self.finish方法后,响应最后才会发送给客户端。
为了对比,下面用coroutine实现的方式。
一个最小的“hello world”示例:
from tornado.ioloop import IOLoop
from tornado.web import RequestHandler, Application, url
class HelloHandler(RequestHandler):
def get(self):
self.write("Hello, world")
def make_app():
return Application([
url(r"/", HelloHandler),
])
def main():
app = make_app()
app.listen(8888)
IOLoop.current().start()Application对象
Application这个对象负责全局的配置,包括把请求映射到Handlers的路由表(Route Table)。路由表URLSpec对象集合(或者元组),包含一个正则表达式和Handler类。如果正则表达式中包含捕获组,这些组将会是路径参数(path arguments),而且这些捕获的组的值会传递hanlder的Http方法的参数中。如果将字典对象作为第三个参数传递的话,这个参数的值将会传递给RequestHandler的initialize的参数。最后,URLSpec可以有个名称,可以通过Request.reverse_url得到。
示例:
# -*- coding: utf-8 -*-
from tornado.ioloop import IOLoop
from tornado.web import Application, url, RequestHandler
__author__ = 'Administrator'
class MainHanlder(RequestHandler):
def get(self):
self.write('<a href="%s">link to story 1</a>' %
self.reverse_url("story", "1"))
class StoryHanlder(RequestHandler):
def initialize(self, db):
self.db = db
def get(self, story_id):
self.write("this is story %s" % story_id)
db = 1
app = Application([
url(r"/", MainHanlder),
url(r"/story/([0-9]+)", StoryHanlder, dict(db=db), name="story")
])
def main():
app.listen(8888)
IOLoop.current().start()
if __name__ == "__main__":
main()根路径被映射至MainHanlder.而“/story/数字”格式的请求则被映射成StoryHandler.这个数字会当成是字符串传递给StoryHanlder的get方法。
在游览器中输入http://localhost:8888/
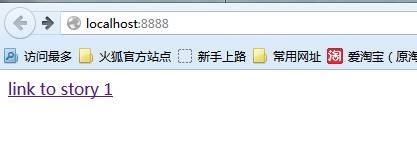
单击“link to story 1”之后,

Application 构造函数有很多关键字参数,用来自定义应用程序的行为。具体请参考Application.settings查看完整的设置参数列表。
RequestHanlder的子类
Tornado web应用程序大部分工作都是由RequestHandler的子类来完成。主要由这个类的方法来处理,比如get(),post()等。每个handler都是定义一个或者多个这样的方法来处理不同的HTTP请求。正如上面所说,这些方法参数的值,会根据路由正则表达式匹配后的值传递进来。在hanlder中,调用RequestHanlder.render或者RequestHanlder.write等方法来产生响应。render() 方法通过名称加载一个模板,并渲染模板。write() 方法而是针对针对非模板的输出,接收字符串、字节和字典(字典必须编码成JSON格式)等参数。
在RequestHandler类中,定义了很多可以被子类重载的方法。所以在开发自身的应用程序时,通常会定义一个BaseHanlder类去重写write_error 和 get_current_user等方法,然后子类继承BaseHanlder而非RequeseHanlder。
处理请求输入
请求的hanlder能够通过调用self.request属性访问代表当前请求的对象。请查看HttpServerRequest类的详细属性定义。示例
class MyFormHandler(RequestHandler):
def get(self):
self.write('<html><body><form action="/myform" method="POST">'
'<input type="text" name="message">'
'<input type="submit" value="Submit">'
'</form></body></html>')
def post(self):
self.set_header("Content-Type", "text/plain")
self.write("You wrote " + self.get_body_argument("message"))用HTML表单格式的请求数据会被解析,而且通过调用方法可以获取,比如get_query_argument和get_body_argument方法。
而如果表单中字段有多个值,可以调用get_query_arguments和get_body_argumens方法。
表单的上传的文件可以通过self.request.files获取。每个每件对象是一个字典,格式为{“filename”:..,”content_type”:..,”body”:…}.只有当文件通过form wrapper方式(比如Content-type的类型为multipart/form)上传时,files属性值才存在。如采用form wrapper格式的话,上传的数据可以通过self.request.body属性获取。默认情况下,上传的文件会缓存在内存中。如果你处理的文件太大以至于不能很好地保存在内存中时,请查看stream_request_body类装饰器。
由于HTML表单编码的怪异性,Tornado不会将不同类型的输入参数组合一起。在特定情况下,我们不会去解析JSON请求体。应用如果喜欢用JSON去替代表单编码(form-encoding)的话,可以去重写prepare方法去解析请求。如下:
def prepare(self):
if self.request.headers["Content-Type"].startswith("application/json"):
self.json_args = json.loads(self.request.body)
else:
self.json_args = None重写RequestHanlder方法
除了get()/post()等方法外,在必要的时候,其他方法也可以被子类重写。在每一个请求中,会执行以下的调用顺序:1. 一个新的RequestHandler对象被创建
2. Initialize()被调用,参数的值从Application对象的配置中获取。Initialize一般只保存这些参数至成员变量中,不会产生任何输出或者调用方法比如send_error.
3. prepare() 被调用。这个的实现最好共享放置在基础类中,供其他子类继承,因为不管任何的HTTP方法被使用,prepare方法都会被调用;prepare可以会产生输出,如果调用了finish(或者redirect等)方法,请求处理过程结束。
4. get(),post(),put()等任一一个方法被调用,如果URL正则表达式包含了捕获组,这些捕获的组的值都会传递给这些方法的参数;
5. 当请求处理结束后,on_finish()方法被调用。对于同步的handler,当get()(举个例子)方法返回后,被立即调用on_finish方法。
通常情况下,重写最多的方法包括:
l write_error . 给用户输出错误页面的HTML;
l On_connection_close 当用户客户端断开连接是调用。应用可以选择去监听断开,然后去停止一些处理过程。、
l get_current_user. 获得当前用户。
l get_user_locale .针对当前用户,返回Locale对象
l set_default_headers .在响应中添加额外的头部。(比如自定义的服务头部)
错误处理
如果hanlder发生了异常,Tornado将会调用Request.write_error去生成错误页面。tornado.web.HTTPError 可以用来产生一个具体的错误状态码,所有的其他异常返回500的状态码。在调试模式下,默认的错误页面包括堆栈跟踪(stack trace),在其他情况下返回一行错误的描述(比如:“500:Internal Server Error”)。为了产生自定义的错误页面,重写request.write_error方法(可能放在供其他handlers继承的基类中)。当被异常导致错误时,exc_info 被作为关键字参数传递(注意,这个异常不能保证是当前在sys.exc_info的异常,所以write_error必须使用比如traceback.format_exception 替代traceback.format_exc)。
另外一种产生错误页面的方式为调用set_status方法,而不是write_error,然后写响应以及返回。特殊的tornado.web.Finish异常被触发会终止hanlder,而不 会调用write_error。
针对404错误,使用在Application setting的default_handler_class来处理。这个handler必须重写prepare方法。根据上面的描述,这将会产生一个错误页面,要么触发HTTPError(404)错误以及重写write_error,要么调用self.set_status(404)然后在prepare中直接产生响应。
重定向
Tornado存在两种主要的重定向请求的方式,一种是调用RequestHanlder.redirect方法,另外一种是直接使用RedirectHandler类。在实现的hanlder中使用self.redirect方法可以重定向到任何地方。这个方法还有一个参数permanent,用来指示这个重定向是否是永久的。这个参数的默认值为False,会产生302 Found状态编号的响应,而且特别适合像POST()请求处理成功后的重定向。如果permanent这个参数值为True, 301 Moved Permanetly状态编码会返回给用户。
RedirectHandler ,允许用户可以在Application路由表中配置重定向的链接。比如下面一个例子,配置了单个静态重定向。
app = tornado.web.Application([ url(r"/app", tornado.web.RedirectHandler, dict(url="http://itunes.apple.com/my-app-id")), ])
RedirectHanlder 同样支持正则表达式的情形。下面的规则定义,可以使以/pictures/开头的请求重定向至以/photos/为前缀的请求。
app = tornado.web.Application([ url(r"/photos/(.*)", MyPhotoHandler), url(r"/pictures/(.*)", tornado.web.RedirectHandler, dict(url=r"/photos/\1")), ])
不像RequestHanlder.redirect方法,RedirectHandler默认采用永久的重定向,即permanent属性为True.这是应为路由表在运行时不能改变,而在hanlder中使用的重定向地址在逻辑上可以会改变。如果要用RedirectHandler发送一个临时的重定向,在RedirectHandler初始化参数中将permanent设置成False.
异步Handler
默认情况下,hanlders是同步的。当get()/post()方法返回时,请求才认为结束,然后再发送响应。当handler正在运行时,其他请求将会被阻塞。任何一个长时间运行的hanlder必须设置为异步的,这样操作就不会阻塞。使hanlder成为异步的最简单的方式就是使用coroutine装饰器。使用yield关键字可以执行非阻塞的I/O操作,直到coroutine已经返回后,才能将响应返回给用户端。
在有些情况下,coroutines没有采用回调的方式方便,这种回调方式是采用tornado.web.asynchrounous装饰器。当使用这个装饰器时,响应不会自动发送,请求会保持打开的状态直到回调函数调用了RequestHandler.finish方法。应用必须保证这个方法被调用,不然用户的游览器将会简单地暂停。
下面是个例子,使用内置的 AsyncHttpClient调用FriendFeed Api。
class MainHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
http = tornado.httpclient.AsyncHTTPClient()
http.fetch("http://friendfeed-api.com/v2/feed/bret",
callback=self.on_response)
def on_response(self, response):
if response.error: raise tornado.web.HTTPError(500)
json = tornado.escape.json_decode(response.body)
self.write("Fetched " + str(len(json["entries"])) + " entries "
"from the FriendFeed API")
self.finish()当get()方法返回时,这个请求没有结束。当最后调用on_response 方法之前,这个请求一直都是打开的,当调用了self.finish方法后,响应最后才会发送给客户端。
为了对比,下面用coroutine实现的方式。
class MainHandler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self):
http = tornado.httpclient.AsyncHTTPClient()
response = yield http.fetch("http://friendfeed-api.com/v2/feed/bret")
json = tornado.escape.json_decode(response.body)
self.write("Fetched " + str(len(json["entries"])) + " entries "
"from the FriendFeed API")

相关文章推荐
- c#三层架构登陆实例
- 网站页面在浏览器中设置样式格式。
- 不为技术而技术:大型网站架构演化解析
- 58同城沈剑:好的架构不是设计出来的,而是演进出来的
- Hexagon SDK架构分析
- 网站广告收入反正要发动群众的力量,来创造利润--小黄人软件
- JSP网站
- hadoop2整体架构
- .net大型分布式电子商务架构说明
- 网站开发进阶(七)**网站访问综合问题分析
- 网站开发进阶(七)**网站访问综合问题分析
- 谈谈 watchOS 2:架构变化和开发注意事项
- 美国军方网站还在用老旧的 SHA-1 证书
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
- php抓取网站图片并保存的实现方法
- nutch2.3爬虫抓取电影网站
- 网站安全检测api网站健康状况查询
- 网站收集
- 58同城网站的一些想法
- 在ios中实现staggeringBeauty网站的效果