黑马程序员——6.集合类(String/StringBuffer、List、Set、Map、Collections工具类、Arrays工具类 )
2015-10-05 15:34
731 查看
——Java培训、Android培训、iOS培训、.Net培训、期待与您交流! ——-
String:
String类的特点:
字符串对象一旦被初始化就不会被改变。
String类部分方法
获取
获取字符串中字符的个数(长度)
int length();
根据位置获取字符
char charAt(int index);
根据字符获取在字符串中的位置
int indexOf(int ch);
indexO方法参数f类型为int是为了既可以支持字符,也可以支持字符在ASCII码中对应的数字。
从指定位置开始查找ch第一次出现的位置。
int indexOf(int ch,int fromIndex);
int indexOf(String str);
int indexOf(String str,int fromIndex);
根据字符串获取在字符串中第一次出现的位置。
int lastIndexOf(int ch);
int lastIndexOf(int ch,int fromIndex);
int lastIndexOf(String str);
int lastIndexOf(String str,int fromIndex);
获取字符串中的一部分字符串,也叫子串。
String substring(int beginIndex,int endIndex);
String substring(int beginIndex);
转换
将字符串变成字符串数组(字符串的切割)
String[] split(String regex);涉及到正则表达式。
将字符串变成字符数组
char[] toCharArray();
将字符串变成字节数组
char[] getBytes();
将字符串中的字母转成大小写
String toUpperCase();大写
String toLowerCase();小写
将字符串中的内容进行替换
String replace(char oldCh,char newCh);
String replace(String s1,String s2);
去除字符串两端空格
String trim();
将字符串进行连接
String concat(String str);
将其他类型数据转换成字符串
String.valueOf(boolean/char/double/float/int/long/Object);
判断
两个字符串内容是否相同呢?
boolean equals(Object obj);
boolean equalsIgnoreCase(String str);忽略大小写比较字符串内容。
字符串中是否包含指定字符串
boolean contains(String str);
字符串是否以指定字符串开头,是否以指定字符串结尾
boolean startsWith(String str);
boolean endsWith(String str);
比较
int compareTo(String str);
如果参数字符串等于此字符串,则返回值0;如果此字符串按字典顺序小于字符串参数,则返回一个小于0的值;如果此字符串按字典顺序大于字符串参数,则返回一个大于0的值。
返回字符串对象的规范化表示形式
String intern();
当调用intern方法时,如果池已经包含一个等于此String对象的字符串(用equals(Object)方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并返回此String对象的引用。
StringBuffer:
就是字符串缓冲区,用于存储数据的容器。
特点:
长度是可变的。
可以存储不同类型数据。
最终要转成字符串进行使用。
P.S.
StringBuffer的字符串缓冲区初始容量为16个字符,其实质还是数组。
添加
StringBuffer append(data);
S
4000
tringBuffer insert(index,data);
删除
StringBuffer delete(int start,int end);包含头,不包含尾。
StringBuffer deleteCharAt(int index):删除指定位置的元素。
查找
char charAt(int index);
int indexO(String str);
int lastIndexOf(String str);
修改
StringBuffer replace(int start,int end,String str);
void setCharAt(int index,char ch);
其他方法
void setLength(int newLength);设置字符序列的长度
public StringBuffer reverse();将字符序列用其反转形式取代
P.S.
使用setLength设置StringBuffer中字符序列的长度。
如果小于已有字符序列的长度,相当于清除缓冲区中的一部分内容。
如果大于已有字符序列的长度,相当于扩充缓冲区,扩充部门内容用空格字符填充。
当创建的StringBuffer内容长度大于16,将会新创建一个新数组,长度比旧数组要长。然后把就数组的内容拷贝到新的数组,超出旧数组长度范围的内容将会放在新数组现在内容的后面,也可以通过StringBuffer(int capacity);构造函数自己设置StringBuffer缓冲区长度。
StringBuilder
jdk1.5以后出现了功能和StringBuffer一模一样的对象,就是StringBuilder。
不同的是:
StringBuffer是线程同步的,通常用于多线程。
StringBuilder是线程不同步的,通常用于单线程,它的出现能够提高程序效率。
故StringBuilder用于多个线程是不安全的,如果需要这样的同步,则建议使用StringBuffer。
集合类
是一个容器,用来存储对象的,
集合容器因为内部的数据结构不同,有多种具体容器。
不断的向上抽取,就形成了集合框架。
跟数组的不同:
数组长度是固定的,集合长度可变;数组可以存储基本数据类型,而集合存储只能存储对象
集合框架的构成及分类:
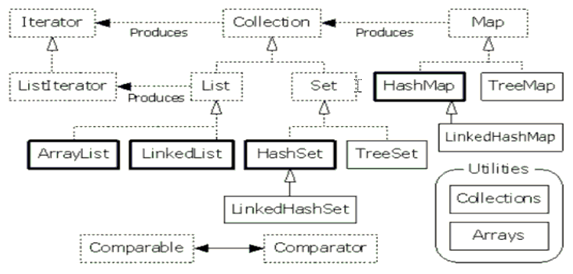
框架的顶层Collection接口的共性方法:
Collection的常见方法:
添加:
boolean add(Object obj); //添加元素
boolean addAll(Collection coll); //添加另一个集合中的所有元素过来
删除:
boolean remove(Object obj); //删除元素
boolean removeAll(Collection coll); //从集合中去除掉两集合的交集
void clear(); //清空集合
判断:
boolean contains(Object obj); //判断是否包含该元素
boolean containsAll(Collection coll); //判断是否包含某集合的所有元素
boolean isEmpty(); //判断集合是否为空
获取:
int size(); //获取集合的元素个数
Iterator iterator(); //获取集合的迭代器
取出元素的方式:迭代器
Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
其他:
boolean retainAll(Collection coll); //取交集
Object toArray(); //将集合转成数组
集合类的数据结构:
List:元素是有序的,元素可以重复,因为List里有索引
Set:元素是无序的,元素不可以重复,因为Set里没有索引
集合类构成:

List:特有的常见方法。
有一个共性特点就是都可以操作角标。
添加
void add(index,element); //在index角标位添加元素
void addAll(index,collection); //在角标位添加整个集合的元素
删除
Object remove(index); //删除并返回index角标位上的元素
修改
Object set(index,element); //修改并返回index角标位处的元素
获取:
Object get(index); //获取index角标位的元素
int indexOf(object); //获取object元素出现的第一个角标位
int lastIndexOf(object); //获取object元素出现的最后一个角标位
List subList(from,to); //获取子集合
List集合可以完成对元素的增删改查。
在迭代器过程中,不要使用集合操作元素,容易出现异常:java.util.ConcurrentModificationException。
可以使用Iterator接口的子接口ListIterator来完成在迭代中对元素进行更多的操作。
注意:在使用迭代器操作集合时要只使用迭代器的方法,不要在迭代途中使用集合操作。
ArrayList:
ArrayList中的方法与上面List接口的方法一致
LinkedList方法:
LinkList除了有List的共性方法外,还有特有方法
addFirst();//添加元素到头部
addLast();
jdk1.6版本后新方法:
offerFirst(); //与addFirst方法没有区别。
offerLast(); //与addLast方法没有区别。
getFirst();//获取但不移除,如果链表为空,抛出NoSuchElementException。
getLast();
jdk1.6版本后新方法:
peekFirst();//获取但不移除,如果链表为空,返回null。
peekLast();
removeFirst();//获取并移除,如果链表为空,抛出NoSuchElementException。
removeLast();
jdk1.6版本后新方法:
pollFirst();//获取并移除,如果链表为空,返回null;
pollLast();
Set:元素不可以重复,是无序的。
Set接口中的方法和Collection一致。
|–HashSet:内部数据结构是哈希表,是不同步的
|–TreeSet:内部数据结构是二叉树,可以对Set集合中的元素进行排序,是不同步的
HashSet:
哈希表确定元素是否相同
判断的是两个元素的哈希值是否相同。如果相同,再判断两个对象的内容是否相同。
判断哈希值相同,其实判断的是对象的HashCode方法。判断内容相同,用的是equals方法。
存储元素时为了防止哈希值重复,一般会重写HashCode方法,需要时,也要重写equals方法。
无序变有序,使用LinkHashSet。
TreeSet:
TreeSet判断元素唯一性的方式:就是根据比较方法的返回结果是否是0,是0,就是相同元素,不存。
二叉树存元素时
元素自身需要具备比较性,不具备比较性的元素需要实现comparable接口,实现compareTo(元素)(返回0相等,-1小于,1大于)方法,否则没办法排序,会出错(比较时,如果主要元素相同,要再比较次要元素)。
让集合自身具备比较功能,当元素不具备比较性,或者具有的比较性不是我们需要的时候,可以让容器在创建时就传入一个比较器,该比较器应该实现Comparator接口,覆盖compare()方法。
当两种方式都存在时,以比较器为主。
传入比较器:
泛型:
Map:
Map< key,value>:键值对,一次添加一对元素,一个键对映一个值,不能有重复的键
Map也称为双列集合,Collection集合称为单列集合。
在有映射关系时可以优先考虑使用Map,在查表法中的应用较为多见。
常用方法:
添加。
put(key,value) //添加一对键值对
putAll(Map) //添加一个Map集合的所有键值对
删除。
clear() //清空集合
remove(key) //删除该键对应的键值对
判断。
containsValue(value) //判断是否含有该值
containsKey(key) //判断是否含有该键
isEmpty() //判断集合是否为空
获取。
get(key) //通过键获取元素对象
size() //获取集合元素个数
values() //获取值的Set集合
keySet() //获取键的Set集合
entrySet() //获取该集合的映射关系Set集合
获取Map集合元素并打印:
Map常用的子类:
|–Hashtable:内部结构是哈希表,是同步的。不允许null作为键,null作为值。
—- |–Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|–HashMap:内部结构式哈希表,不是同步的。允许null作为键,null作为值。
—- |–LinkedHashMap:跟原来存入的顺序是一致的
|–TreeMap:内部结构式二叉树,不是同步的。可以对Map结合中的键进行排序。
HashMap:
传入比较器:
Collections工具类:
Arrays工具类 :
String:
String类的特点:
字符串对象一旦被初始化就不会被改变。
public class StringDemo{
public static void main(String[] args){
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2); //结果为true
/*
字符串创建的时候,有一个字符串常量池,s1创建后,"abc"放入其中。s2创建的时候,"abc"已经存在于字符串常量池中,故引用变量s2直接指向了已经存在的"abc"字符串对象,故s1==s2。
*/
}
}public class StringDemo{
public static void main(String[] args){
String s1 = "abc";
String s2 = new String("abc" );
System.out.println(s1 == s2); //结果为false
/*
s1创建后,是在字符串常量池中创建了一个"abc"字符串对象。而s2是在堆内存中创建了另外一个"abc"字符串对象。所以,两个对象不是同一个对象。
*/
System.out.println(s1.equals(s2)); //结果为true
/*
String类复写了Object中的equals方法,建立了String类自己的判断字符串对象是否相同的依据。只比较字符串内容,不比较地址。
*/
}
}public class StringConstructorDemo {
public static void main(String[] args){
StringConstructorDemo1();
}
public static void StringConstructorDemo1(){
String s = new String();//等效于String s = "";不等效于String s = null;
byte[] arr = {65,66,67,68};
//通过字节数组创建字符串
String s1 = new String(arr);
System.out.println("s1 = " + s1); //结果为“ABCD”
}
public static void StringConstructorDemo2(){
char[] arr = {'w' ,'a' ,'p' ,'q' ,'x' };
//通过char数组创建字符串
String s = new String(arr);
System.out.println( "s = " + s); //结果为“wapqx”
}
public static void StringConstructorDemo3(){
char[] arr = {'w' ,'a' ,'p' ,'q' ,'x' };
//通过char数组段创建字符串
String s = new String(arr,1,3);
System.out.println( "s = " + s); //结果为“apq”
}
}String类部分方法
获取
获取字符串中字符的个数(长度)
int length();
根据位置获取字符
char charAt(int index);
根据字符获取在字符串中的位置
int indexOf(int ch);
indexO方法参数f类型为int是为了既可以支持字符,也可以支持字符在ASCII码中对应的数字。
从指定位置开始查找ch第一次出现的位置。
int indexOf(int ch,int fromIndex);
int indexOf(String str);
int indexOf(String str,int fromIndex);
根据字符串获取在字符串中第一次出现的位置。
int lastIndexOf(int ch);
int lastIndexOf(int ch,int fromIndex);
int lastIndexOf(String str);
int lastIndexOf(String str,int fromIndex);
获取字符串中的一部分字符串,也叫子串。
String substring(int beginIndex,int endIndex);
String substring(int beginIndex);
转换
将字符串变成字符串数组(字符串的切割)
String[] split(String regex);涉及到正则表达式。
将字符串变成字符数组
char[] toCharArray();
将字符串变成字节数组
char[] getBytes();
将字符串中的字母转成大小写
String toUpperCase();大写
String toLowerCase();小写
将字符串中的内容进行替换
String replace(char oldCh,char newCh);
String replace(String s1,String s2);
去除字符串两端空格
String trim();
将字符串进行连接
String concat(String str);
将其他类型数据转换成字符串
String.valueOf(boolean/char/double/float/int/long/Object);
判断
两个字符串内容是否相同呢?
boolean equals(Object obj);
boolean equalsIgnoreCase(String str);忽略大小写比较字符串内容。
字符串中是否包含指定字符串
boolean contains(String str);
字符串是否以指定字符串开头,是否以指定字符串结尾
boolean startsWith(String str);
boolean endsWith(String str);
比较
int compareTo(String str);
如果参数字符串等于此字符串,则返回值0;如果此字符串按字典顺序小于字符串参数,则返回一个小于0的值;如果此字符串按字典顺序大于字符串参数,则返回一个大于0的值。
返回字符串对象的规范化表示形式
String intern();
当调用intern方法时,如果池已经包含一个等于此String对象的字符串(用equals(Object)方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并返回此String对象的引用。
StringBuffer:
就是字符串缓冲区,用于存储数据的容器。
特点:
长度是可变的。
可以存储不同类型数据。
最终要转成字符串进行使用。
P.S.
StringBuffer的字符串缓冲区初始容量为16个字符,其实质还是数组。
添加
StringBuffer append(data);
S
4000
tringBuffer insert(index,data);
删除
StringBuffer delete(int start,int end);包含头,不包含尾。
StringBuffer deleteCharAt(int index):删除指定位置的元素。
查找
char charAt(int index);
int indexO(String str);
int lastIndexOf(String str);
修改
StringBuffer replace(int start,int end,String str);
void setCharAt(int index,char ch);
其他方法
void setLength(int newLength);设置字符序列的长度
public StringBuffer reverse();将字符序列用其反转形式取代
P.S.
使用setLength设置StringBuffer中字符序列的长度。
如果小于已有字符序列的长度,相当于清除缓冲区中的一部分内容。
如果大于已有字符序列的长度,相当于扩充缓冲区,扩充部门内容用空格字符填充。
当创建的StringBuffer内容长度大于16,将会新创建一个新数组,长度比旧数组要长。然后把就数组的内容拷贝到新的数组,超出旧数组长度范围的内容将会放在新数组现在内容的后面,也可以通过StringBuffer(int capacity);构造函数自己设置StringBuffer缓冲区长度。
StringBuilder
jdk1.5以后出现了功能和StringBuffer一模一样的对象,就是StringBuilder。
不同的是:
StringBuffer是线程同步的,通常用于多线程。
StringBuilder是线程不同步的,通常用于单线程,它的出现能够提高程序效率。
故StringBuilder用于多个线程是不安全的,如果需要这样的同步,则建议使用StringBuffer。
集合类
是一个容器,用来存储对象的,
集合容器因为内部的数据结构不同,有多种具体容器。
不断的向上抽取,就形成了集合框架。
跟数组的不同:
数组长度是固定的,集合长度可变;数组可以存储基本数据类型,而集合存储只能存储对象
集合框架的构成及分类:
框架的顶层Collection接口的共性方法:
Collection的常见方法:
添加:
boolean add(Object obj); //添加元素
boolean addAll(Collection coll); //添加另一个集合中的所有元素过来
删除:
boolean remove(Object obj); //删除元素
boolean removeAll(Collection coll); //从集合中去除掉两集合的交集
void clear(); //清空集合
判断:
boolean contains(Object obj); //判断是否包含该元素
boolean containsAll(Collection coll); //判断是否包含某集合的所有元素
boolean isEmpty(); //判断集合是否为空
获取:
int size(); //获取集合的元素个数
Iterator iterator(); //获取集合的迭代器
取出元素的方式:迭代器
Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
其他:
boolean retainAll(Collection coll); //取交集
Object toArray(); //将集合转成数组
集合类的数据结构:
List:元素是有序的,元素可以重复,因为List里有索引
Set:元素是无序的,元素不可以重复,因为Set里没有索引
集合类构成:
List:特有的常见方法。
有一个共性特点就是都可以操作角标。
添加
void add(index,element); //在index角标位添加元素
void addAll(index,collection); //在角标位添加整个集合的元素
删除
Object remove(index); //删除并返回index角标位上的元素
修改
Object set(index,element); //修改并返回index角标位处的元素
获取:
Object get(index); //获取index角标位的元素
int indexOf(object); //获取object元素出现的第一个角标位
int lastIndexOf(object); //获取object元素出现的最后一个角标位
List subList(from,to); //获取子集合
List集合可以完成对元素的增删改查。
import java.util.*;
public class ListDemo{
public static void main(String[] args){
List list = new ArrayList();
show(list);
}
public static void show(List list){
//添加元素
list.add( "abc1" );
list.add( "abc2" );
list.add( "abc3" );
System.out.println(list);
//插入元素
list.add(1, "abc2" );
//删除元素
System.out.println( "remove:" + list.remove(2));
//修改元素
System.out.println( "set:" + list.set(1,"abc8" ));
//获取元素:
System.out.println( "get:" + list.get(0));
//获取子列表
System.out.println( "sublist:" + list.subList(1,2));
System.out.println(list);
//使用迭代器取出元素
Iterator it = list.iterator();
while(it.hasNext()){
System.out.println( "next:" + it.next());
}
//list特有的取出元素的方式之一
for(int x = 0; x < list.size(); x++){
System.out.println( "get:" + list.get(x));
}
}在迭代器过程中,不要使用集合操作元素,容易出现异常:java.util.ConcurrentModificationException。
可以使用Iterator接口的子接口ListIterator来完成在迭代中对元素进行更多的操作。
import java.util.*;
public class ListDemo{
public static void main(String[] args){
List list = new ArrayList();
list.add( "abc1");
list.add( "abc2");
list.add( "abc3");
System.out.println( "list:" + list);
//获取列表迭代器对象
//它可以实现在迭代过程中完成对元素的增删改查
//注意:只有list集合具备该迭代功能
ListIterator it = list.listIterator();
while(it.hasNext()){
Object obj = it.next();
//只有ListIterator才可以在迭代中对元素进行添加删除等操作
if(obj.equals("abc3" )){
it.add( "abc9");
}
}
System.out.println( "hasNext:" + it.hasNext());
System.out.println( "hasPrevious:" + it.hasPrevious());
//指针到达末尾后,逆向获取元素
while(it.hasPrevious()){
System.out.println( "previous:" + it.previous());
}
System.out.println( "list:" + list);
}
}注意:在使用迭代器操作集合时要只使用迭代器的方法,不要在迭代途中使用集合操作。
ArrayList:
ArrayList中的方法与上面List接口的方法一致
import java.util.*;
//创建Person类
class Person{
private String name;
private int age;
public Person(){
}
public Person(String name,int age){
this.name = name;
this.age = age;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return this .name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return this .age;
}
}
public class ArrayListTest{
public static void main(String[] args){
ArrayList al = new ArrayList();
//添加元素
al.add( new Person("lisi1" ,21));
al.add( new Person("lisi2" ,22));
al.add( new Person("lisi3" ,23));
al.add( new Person("lisi4" ,24));
//进行迭代
Iterator it = al.iterator();
while(it.hasNext()){
Person p = (Person)(it.next());
System.out.println(p.getName() + ":" + p.getAge());
}
}
}LinkedList方法:
LinkList除了有List的共性方法外,还有特有方法
addFirst();//添加元素到头部
addLast();
jdk1.6版本后新方法:
offerFirst(); //与addFirst方法没有区别。
offerLast(); //与addLast方法没有区别。
getFirst();//获取但不移除,如果链表为空,抛出NoSuchElementException。
getLast();
jdk1.6版本后新方法:
peekFirst();//获取但不移除,如果链表为空,返回null。
peekLast();
removeFirst();//获取并移除,如果链表为空,抛出NoSuchElementException。
removeLast();
jdk1.6版本后新方法:
pollFirst();//获取并移除,如果链表为空,返回null;
pollLast();
import java.util.*;
public class LinkedListDemo{
public static void main(String[] args){
LinkedList link = new LinkedList();
link.addFirst( "abc1");
link.addFirst( "abc2");
link.addFirst( "abc3");
link.addFirst( "abc4");
Iterator it = link.iterator();
while(it.hasNext()){
System.out.println( "next:" + it.next());
}
System.out.println(link);
//获取第一个,但是不删除。
System.out.println("getFirst:" + link.getFirst());
System.out.println("getLast:" + link.getLast());
//获取第一个,并删除
System.out.println("removeFirst:" + link.removeFirst());
System.out.println("removeLast:" + link.removeLast());
//删除所有元素的方法
while(!link.isEmpty()){
System.out.println(link.removeFirst());
}
}
}Set:元素不可以重复,是无序的。
Set接口中的方法和Collection一致。
|–HashSet:内部数据结构是哈希表,是不同步的
|–TreeSet:内部数据结构是二叉树,可以对Set集合中的元素进行排序,是不同步的
HashSet:
哈希表确定元素是否相同
判断的是两个元素的哈希值是否相同。如果相同,再判断两个对象的内容是否相同。
判断哈希值相同,其实判断的是对象的HashCode方法。判断内容相同,用的是equals方法。
存储元素时为了防止哈希值重复,一般会重写HashCode方法,需要时,也要重写equals方法。
import java.util.*;
class Person{
private String name;
private int age;
public Person(){
}
public Person(String name,int age){
this.name = name;
this.age = age;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return this .name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return this .age;
}
//重写hashCode方法,防止哈希值相同
public int hashCode(){
return name.hashCode() + age * 39;
}
//重写equals方法,自定义比较方法
public boolean equals(Object obj){
//同一个对象放两次,直接返回true
if(this == obj)
return true ;
if(!(obj instanceof Person))
throw new ClassCastException("类型错误");
//因为传进来的是Object对象,要强转
Person p = (Person)obj;
//name与age相同就视为同一个人
return this.name.equals(p.name) && this.age == p.age;
}
}
public class HashSetTest{
public static void main(String[] args){
HashSet hs = new HashSet();
hs.add( new Person("lisi4" ,24));
hs.add( new Person("lisi7" ,27));
hs.add( new Person("lisi1" ,21));
hs.add( new Person("lisi9" ,29));
hs.add( new Person("lisi7" ,27));
Iterator it = hs.iterator();
while(it.hasNext()){
Person p = (Person)it.next();
System.out.println(p.getName() + "..." + p.getAge());
}
}
}无序变有序,使用LinkHashSet。
import java.util.*;
public class LinkedHashSetDemo{
public static void main(String[] args){
HashSet hs = new LinkedHashSet();
hs.add( "hahaa");
hs.add( "hehe");
hs.add( "heihei");
hs.add( "xixii");
Iterator it = hs.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}TreeSet:
TreeSet判断元素唯一性的方式:就是根据比较方法的返回结果是否是0,是0,就是相同元素,不存。
二叉树存元素时
元素自身需要具备比较性,不具备比较性的元素需要实现comparable接口,实现compareTo(元素)(返回0相等,-1小于,1大于)方法,否则没办法排序,会出错(比较时,如果主要元素相同,要再比较次要元素)。
让集合自身具备比较功能,当元素不具备比较性,或者具有的比较性不是我们需要的时候,可以让容器在创建时就传入一个比较器,该比较器应该实现Comparator接口,覆盖compare()方法。
当两种方式都存在时,以比较器为主。
import java.util.*;
//不具备比较性的类要实现Comparable接口
class Person implements Comparable{
private String name;
private int age;
public Person(){
}
public Person(String name,int age){
this.name = name;
this.age = age;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return this .name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return this .age;
}
public int hashCode(){
return name.hashCode() + age * 39;
}
public boolean equals(Object obj){
if(this == obj)
return true ;
if(!(obj instanceof Person))
throw new ClassCastException("类型错误");
Person p = (Person)obj;
return this .name.equals(p.name) && this.age == p.age;
}
//重写比较方法
public int compareTo(Object o){
Person p = (Person)o;
//先按照年龄排序,再按照年龄排序,以免年龄相同的人,没有存进去。
int temp = this.age - p.age;
return temp == 0?this.name.compareTo(p.name):temp;
}
}
public class TreeSetDemo{
public static void main(String[] args){
TreeSet ts = new TreeSet();
//以Person对象年龄进行从小到大的排序
ts.add( new Person("zhangsan" ,28));
ts.add( new Person("wangwu" ,23));
ts.add( new Person("lisi" ,21));
ts.add( new Person("zhouqi" ,29));
ts.add( new Person("zhaoliu" ,25));
Iterator it = ts.iterator();
while(it.hasNext()){
Person p = (Person)it.next();
System.out.println(p.getName() + ":" + p.getAge());
}
}
}传入比较器:
import java.util.*;
//创建了一个根据Person类的name进行排序的比较器。
//该比较器要实现Comparator接口
class ComparatorByName implements Comparator{
//覆盖compare方法
public int compare(Object o1,Object o2){
Person p1 = (Person)o1;
Person p2 = (Person)o2;
//先比较姓名,再比较年龄
int temp = p1.getName().compareTo(p2.getName());
return temp == 0?p1.getAge()-p2.getAge() : temp;
}
}
public class TreeSetDemo{
public static void main(String[] args){
//创建集合时把比较器对象作为参数传递进去
TreeSet ts = new TreeSet(new ComparatorByName());
//以Person对象年龄进行从小到大的排序
ts.add( new Person("zhangsan" ,28));
ts.add( new Person("wangwu" ,23));
ts.add( new Person("lisi" ,21));
ts.add( new Person("zhouqi" ,29));
ts.add( new Person("zhaoliu" ,25));
Iterator it = ts.iterator();
while(it.hasNext()){
Person p = (Person)it.next();
System.out.println(p.getName() + ":" + p.getAge());
}
}
}泛型:
在新建和声明对象的类时,在类的后边加上类型,那么就只有声明的类型的元素能加进该对象里面。 例如:ArrayList<String> a1 = new ArrayList<String>(); 具体参见泛型类。
Map:
Map< key,value>:键值对,一次添加一对元素,一个键对映一个值,不能有重复的键
Map也称为双列集合,Collection集合称为单列集合。
在有映射关系时可以优先考虑使用Map,在查表法中的应用较为多见。
常用方法:
添加。
put(key,value) //添加一对键值对
putAll(Map) //添加一个Map集合的所有键值对
删除。
clear() //清空集合
remove(key) //删除该键对应的键值对
判断。
containsValue(value) //判断是否含有该值
containsKey(key) //判断是否含有该键
isEmpty() //判断集合是否为空
获取。
get(key) //通过键获取元素对象
size() //获取集合元素个数
values() //获取值的Set集合
keySet() //获取键的Set集合
entrySet() //获取该集合的映射关系Set集合
import java.util.*;
public class MapDemo{
public static void main(String[] args){
Map<Integer,String> map = new HashMap<Integer,String>();
method(map);
}
public static void method(Map<Integer,String> map){ //学号和姓名
//添加元素
System. out.println(map.put(8,"旺财" ));
System. out.println(map.put(8,"小强" ));
System. out.println(map);
map.put(2, "张三");
map.put(7, "赵六");
System. out.println(map);
//删除
System. out.println("remove:" + map.remove(2));
//判断
System. out.println("containsKey:" + map.containsKey(7));
//获取
System. out.println("get:" + map.get(7));
}
}获取Map集合元素并打印:
import java.util.*;
public class MapDemo{
public static void main(String[] args){
Map<Integer,String> map = new HashMap<Integer,String>();
method(map);
}
public static void method(Map<Integer,String> map){
map.put(8, "王五");
map.put(2, "赵六");
map.put(7, "小强");
map.put(6, "旺财");
/*
原理,通过keySet方法获取map中所有的键所在的set集合,在通过set的迭代器获取到每一个键。
再对每一个键通过map集合的get方法获取其对应的值即可。
*/
Set<Integer> keySet = map.keySet();
Iterator<Integer> it = keySet.iterator();
while(it.hasNext()){
Integer key = it.next();
String value = map.get(key);
System.out.println(key + ":" + value);
}
/*
通过Map转成Set就可以迭代。
找到了另一个方法,entrySet。
该方法将键和值的映射关系作为对象存储到了Set集合中,而这个映射关系的类型就是Map.Entry类型
*/
Set<Map.Entry<Integer,String>> entrySet = map.entrySet();
Iterator<Map.Entry<Integer,String>> it = entrySet.iterator();
while(it.hasNext()){
Map.Entry<Integer,String> me = it.next();
Integer key = me.getKey();
String value = me.getValue();
System. out.println(key + ":" + value);
}
/*
直接通过values方法获取map中所有的值所在的set集合
*/
Collection<String> values = map.values();
Iterator<String> it = values.iterator();
while(it.hasNext()){
System. out.println(it.next());
}
}
}Map常用的子类:
|–Hashtable:内部结构是哈希表,是同步的。不允许null作为键,null作为值。
—- |–Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|–HashMap:内部结构式哈希表,不是同步的。允许null作为键,null作为值。
—- |–LinkedHashMap:跟原来存入的顺序是一致的
|–TreeMap:内部结构式二叉树,不是同步的。可以对Map结合中的键进行排序。
HashMap:
import java.util.*;
class Student {
private String name;
private int age;
public Student(){
}
public Student(String name,int age){
this.name = name;
this.age = age;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return this .name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return this .age;
}
//复写hashCode方法
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
//复写equals方法
public boolean equals(Object obj) {
if (this == obj)
return true ;
if (obj == null)
return false ;
if (getClass() != obj.getClass())
return false ;
Student other = (Student) obj;
if (age != other.age)
return false ;
if (name == null) {
if (other.name != null)
return false ;
} else if (!name.equals(other.name))
return false ;
return true ;
}
}
public class HashMapDemo{
public static void main(String[] args){
//将学生对象和学生的归属地通过键与值存储到map集合中
HashMap<Student,String> hm = new HashMap<Student,String>();
hm.put( new Student("lisi" ,38),"北京");
hm.put( new Student("zhaoliu" ,24),"上海");
hm.put( new Student("xiaoqiang" ,31),"沈阳");
hm.put( new Student("wangcai" ,28),"大连");
hm.put( new Student("zhaoliu" ,24),"铁岭");
//通过获取key集合的迭代器取出元素
Iterator<Student> it = hm.keySet().iterator();
while(it.hasNext()){
Student key = it.next();
String value = hm.get(key);
System.out.println(key.getName() + ":" + key.getAge() + "---" + value);
}
}
}传入比较器:
import java.util.*;
//实现Comparator接口
class ComparatorByName implements Comparator<Student>{
//实现比较方法
public int compare(Student s1,Student s2){
int temp = s1.getName().compareTo(s2.getName());
return temp == 0?s1.getAge() - s2.getAge():temp;
}
}
public class HashMapDemo{
public static void main(String[] args){
//将比较器作为参数传入构造函数
TreeMap<Student,String> tm = new TreeMap<Student,String>(new ComparatorByName());
tm.put( new Student("lisi" ,38),"北京");
tm.put( new Student("zhaoliu" ,24),"上海");
tm.put( new Student("xiaoqiang" ,31),"沈阳");
tm.put( new Student("wangcai" ,28),"大连");
tm.put( new Student("zhaoliu" ,24),"铁岭");
//通过Map.Entry集合取出元素
Iterator<Map.Entry<Student,String>> it = tm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Student,String> me = it.next();
Student key = me.getKey();
String value = me.getValue();
System.out.println(key.getName() + ":" + key.getAge() + "---" + value);
}
}
}Collections工具类:
import java.util.*;
public class CollectionsDemo{
public static void main(String[] args){
demo1();
}
public static void demo1(){
List<String> list = new ArrayList<String>();
list.add( "abcde");
list.add( "cba");
list.add( "aa");
list.add( "zzz");
list.add( "cba");
list.add( "nbaa");
//对list集合按照自然顺序的排序
Collections. sort(list);
System. out.println(list);
//对list集合进行指定顺序的排序
Collections. sort(list,new ComparatorByLength());
System. out.println(list);
//使用二分搜索法搜索列表,获得对象坐标(不存在则为:-插入点坐标-1)
int index = Collections.binarySearch(list,"aaa");
System.out.println( "index = " + index);
//获取最大值
String max = Collections.max(list, new ComparatorByLength());
System.out.println( "max = " + max);
//Collections.reverseOrder()返回强行逆转自然顺序的比较器
TreeSet<String> ts1 = new TreeSet<String>(Collections.reverseOrder());
//返回强行逆转了比较器顺序的比较器
ts1 = new TreeSet<String>(Collections.reverseOrder(new ComparatorByLength()));
ts1.add( "abc");
ts1.add( "hahaha");
ts1.add( "zzz");
ts1.add( "aa");
ts1.add( "cba");
System.out.println(ts1);
//全部替换
Collections. replaceAll(list,"cba", "nba");
System. out.println(list);
//随机打乱集合列表中元素顺序
Collections. shuffle(list);
System. out.println(list);
}
class ComparatorByLength implements Comparator<String>{
public int compare(String o1,String o2){
int temp = o1.length() - o2.length();
return temp == 0?o1.compareTo(o2):temp;
}
}Arrays工具类 :
import java.util.*;
class ArraysDemo{
public static void main(String[] args){
int[] arr = {3,1,5,6,4,7};
//返回数组的字符串表现形式
System.out.println(Arrays.toString(arr));
/*将数组转换成集合
好处:可以使用集合的方法操作数组
数组的长度是固定的,所以对于结合的增删方法是不可以使用的,否则,会发生异常
如果数组中的元素是对象,那么转成集合时,直接将数组中的元素作为集合中的元素进行集合存储。
如果数组中的元素是基本类型数值,那么会将该数组作为集合中的元素进行存储
*/
//把数组中元素存进集合
String[] arr1 = { "abc","haha" ,"xixi" };
List<String> list = Arrays. asList(arr1);
boolean b = list.contains("xixi" );
System. out.println(b);
//数组中元素是基本数据类型,把数组作为集合中元素存进集合
int[] arr1 = {31,11,51,61};
List< int[]> list1 = Arrays.asList(arr1);
System.out.println(list1);
//数组中元素不是基本数据类型,把数组中元素作为集合中的元素进行存储
Integer[] arr2 = {31,11,51,61};
List list2 = Arrays.asList(arr2);
System.out.println(list2);
/*
集合转数组
集合转成数组,可以对集合中的元素操作的方法进行限定,不允许对其进行增删。
toArray方法需要传入一个指定类型的数组。
长度该如何定义呢?
如果长度小于集合的size,那么该方法会创建一个同类型并和集合相同的size的数组。
如果长度大于集合的size,那么该方法就会使用指定的数组,存储集合中的元素,其他位置默认为null。
所以建议,最后长度就指定为,集合的size。
*/
List<String> list = new ArrayList<String>();
list.add( "abc1");
list.add( "abc2");
list.add( "abc3");
String[] arr = list.toArray(new String[2]);
System.out.println(Arrays.toString(arr));
}
}

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树
- [原创]java局域网聊天系统