Python: NLTK几个入门函数
2015-09-28 18:53
746 查看
安装了
从输出格式中可以看出来,
most monstrous size
the monstrous pictures
this monstrous cabinet
等等,
可以看看下面的例子:
这个可以看出的是,
不同的是,这个函数是用来搜索 共用 参数中的列表中的所有单词,的上下文.即: word1,word2 相同的上下文.看例子:
效果如下:
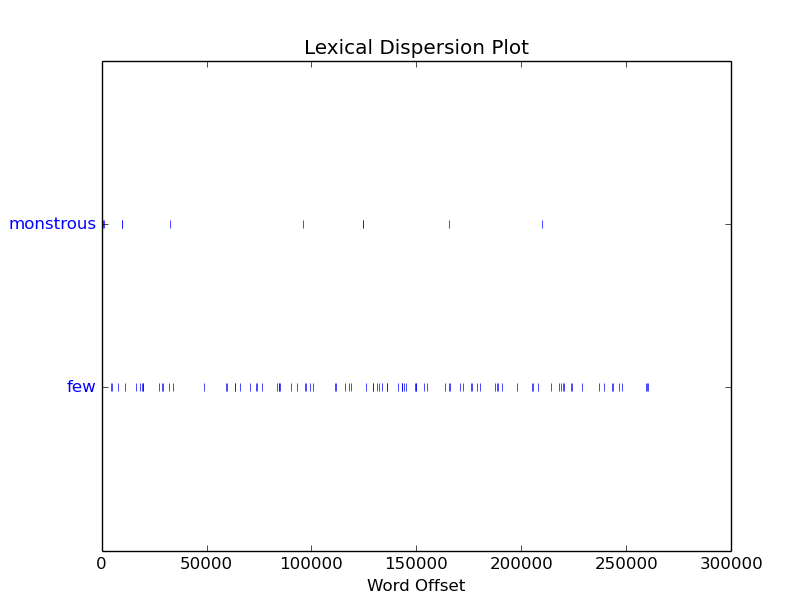
其中横坐标表示文本的单词位置.纵坐标表示查询的单词, 坐标里面的就是,单词出现的位置.就是 单词的分布情况
nltk以及对应的一些英文语料之后,开始按照
python自然语言处理学习来学习, 有几个入门级别的函数,记录如下:
text.concordance(word)
这个函数就是用来搜索单词word在
text中出现多的情况,包括出现的那一行,重点强调上下文,实例如下:
In [1]: from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
In [2]: text1.concordance('monstrous')
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u从输出格式中可以看出来,
concordance将要查询的单词,基本显示在一列,这样容易观察其上下文.
text.similar(word)
这个函数的作用则是根据word的上下文的单词的情况,来查找具有相似的上下文的单词. 比如monstrous 在上面可以看到,有这样的用法:
most monstrous size
the monstrous pictures
this monstrous cabinet
等等,
similar()函数会在文本中 搜索具有类似结构的其他单词, 不过貌似这个函数只会考虑一些简单的指标,来作为相似度,比如上下文的词性,更多的完整匹配, 不会涉及到语义.
可以看看下面的例子:
In [3]: text1.similar('monstrous')
imperial subtly impalpable pitiable curious abundant perilous
trustworthy untoward singular lamentable few determined maddens
horrible tyrannical lazy mystifying christian exasperate
In [4]: text2.similar('monstrous')
very exceedingly so heartily a great good amazingly as sweet
remarkably extremely vast
In [5]: text3.similar('monstrous')
No matches#表示无匹配这个可以看出的是,
text1和
text2对同一个单词
monstrous的不同使用风格.
text.common_contexts([word1,word2…])
这个函数跟simailar()有点类似,也是在根据上下文搜索的.
不同的是,这个函数是用来搜索 共用 参数中的列表中的所有单词,的上下文.即: word1,word2 相同的上下文.看例子:
In [8]: text1.similar('monstrous')
imperial subtly impalpable pitiable curious abundant perilous
trustworthy untoward singular lamentable few determined maddens
horrible tyrannical lazy mystifying christian exasperate
In [9]: text1.common_contexts(['monstrous','subtly'])
most_and
In [10]: text1.common_contexts(['monstrous','imperial'])
most_and
In [11]: text1.common_contexts(['monstrous','few'])
the_pictures#表示:the monstrous pictures, 和 the few pictures 都存在与text1中. 上面同理.text.dispersion_plot([word1, word2,])
这个函数是用离散图 表示 语料中word 出现的位置序列表示.text1.dispersion_plot(['monstrous','few'])
效果如下:
其中横坐标表示文本的单词位置.纵坐标表示查询的单词, 坐标里面的就是,单词出现的位置.就是 单词的分布情况
基本函数
In [8]: len(text9)#统计单词量:以单词和标点符号为单位
Out[8]: 69213
In [9]: text9.count('the')#统计频数
Out[9]: 3291

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法