一步步开发自己的博客 .NET版(5、Lucenne.Net 和 必应站内搜索)
2015-09-14 13:08
441 查看
前言
这次开发的博客主要功能或特点:
第一:可以兼容各终端,特别是手机端。
第二:到时会用到大量html5,炫啊。
第三:导入博客园的精华文章,并做分类。(不要封我)
第四:做个插件,任何网站上的技术文章都可以转发收藏 到本博客。
所以打算写个系类:《一步步搭建自己的博客》
一步步开发自己的博客 .NET版(1、页面布局、blog迁移、数据加载)
一步步开发自己的博客 .NET版(2、评论功能)
一步步开发自己的博客 .NET版(3、注册登录功能)
一步步开发自己的博客 .NET版(4、文章发布功能)
一步步开发自己的博客 .NET版(5、搜索功能)
一步步开发自己的博客 .NET版(6、手机端的兼容)
演示地址:http://haojima.net/ 群内共享源码:469075305
public class SearchResult
{
public SearchResult() { }
public SearchResult(string title, string content, string url, string blogTag, int id, int clickQuantity, int flag)
{
this.blogTag = blogTag;
this.clickQuantity = clickQuantity;
this.content = content;
this.id = id;
this.url = url;
this.title = title;
this.flag = flag;
}
/// <summary>
/// 标题
/// </summary>
public string title { get; set; }
/// <summary>
/// 正文内容
/// </summary>
public string content { get; set; }
/// <summary>
/// url地址
/// </summary>
public string url { get; set; }
/// <summary>
/// tag标签
/// </summary>
public string blogTag { get; set; }
/// <summary>
/// 唯一id
/// </summary>
public int id { get; set; }
/// <summary>
/// 点击量
/// </summary>
public int clickQuantity { get; set; }
/// <summary>
/// 标记(用户)
/// </summary>
public int flag { get; set; }
}View Code
必应站内搜索
1.为什么要用必应搜索?因为我们现在做的主要功能是博客系统,搜索只是其中的一小块环节。而 我对这搜索并不了解,所以就用第三方搜索,省事嘛。
2.为什么不用别的三方收索呢?
百度?不用说了,咱们程序员都懂的。谷歌?我倒是想用,可生在天朝,也是没得办法。选来选去 还是选了必应。
3.怎么来使用第三方的站内搜索?
格式如下:http://cn.bing.com/search?q=关键字+site:网站地址
例如:http://cn.bing.com/search?q=博客+site:blog.haojima.net
效果图:
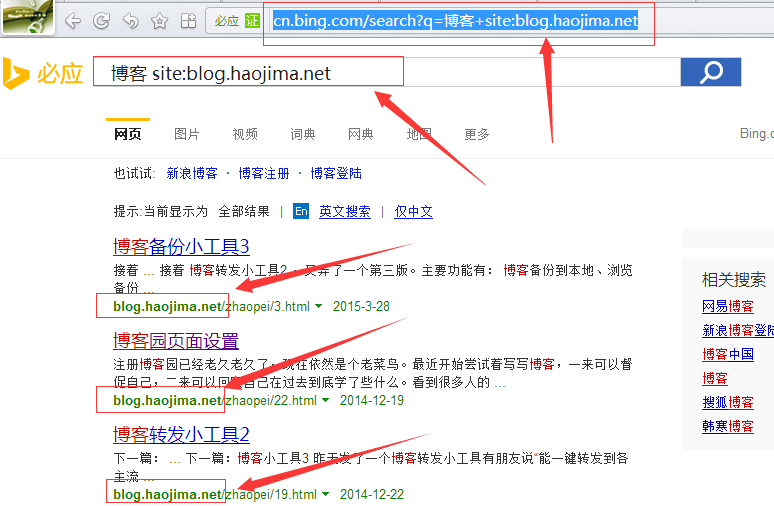
嘿嘿,如此之简单。既然都已经看到效果了,那么 我们可以干些什么呢?

我打算 直接把结果 显示在我的 站内搜索结果。为什么 不直接跳转到这个页面显示 搜索结果?因为 这个页面有广告什么的,不能按照我自己的方式显示。我直接把结果放我的搜索页面 可以和 我上面用Lucene.net的搜索结果一起显示,这样岂不是 显得更专业。

,不知道的 还以为 是我自己怎么弄出来的。那么 我们怎么解析 搜到的结果呢?我这里推荐下 Jumony 之前我一直是用 HtmlAgilityPack ,现在为什么不用了,因为有了更好的。HtmlAgilityPack 缺点是 要去xpath,然 如果页面存在js动态改变文档结构的话,我们直接F12 复制出来的 xpath是不准的。那么有人 会说 HtmlAgilityPack 我已经用习惯了,不想 重新学习Jumony 。这里我告诉你错了,根本就需要重新学习,如果你会jquery 的话。常用功能语法基本一样,还支持拉姆达表达式,爽的一逼。
我们来看看 怎么使用Jumony 解析 解锁结果吧。
var document = jumony.LoadDocument(url);
var list = document.Find("#b_results .b_algo").ToList().Select(t => t.ToString()).ToList();两行代码搞定,还直接转成了list集合。在页面循环加载就ok了。
站内下的某个用户内搜索
我个人觉得 这是个蛮实用的功能,我们有时候 写了博客(很多时候我们写博客就是把自己怕会忘记的知识点 整理记录),而后期找不到。那么通过这个功能 可以很好的解决我们的问题。我们不想全站搜索,只搜索自己的内容就可以了。页面还是用全站的搜索页面,我们直接在搜索关键词上做手脚就可以了。比如,我们想搜索 zhaopei 用户下的内容,那么我们可以要搜索的关键字前面加上 blog:zhaopei 那么完整的搜索关键字就成了 blog:zhaopei 关键字
那么 我们要做的就是 在用户页面 搜索 就在关键字 前面加上 blog:用户名 我们在搜索 页面解析的时候 需要做的就是 分解关键字 blog:用户名 关键字 先用空格 分割 然后如果中间有 空格的话 ,然后判断 前面五个字符是不是 blog: 然后截取 到用户名和 关键字。
我们下面具体看看 在Lucene.net 和 必应搜索里面是怎么做的。
1.Lucene.net
#region 加载 Lucene.net 的搜索结果
/// <summary>
/// 加载 Lucene.net 的搜索结果
/// </summary>
/// <returns></returns>
public ActionResult ShowLuceneResult()
{
if (!Request.QueryString.AllKeys.Contains("key"))
return null;
string key = Request.QueryString["key"];
var zhankey = key.Split(' ');//分割关键字
var blogName = string.Empty;
if (zhankey.Length >= 2)
{
var str = zhankey[0].Trim();
if (str.Length > 6 && str.Substring(0, 5) == "blog:")
blogName = str.Substring(5);//取得用户名
}
string userid = Request.QueryString.AllKeys.Contains("userid") ? Request.QueryString["userid"] : "";
//这里判断是否 用户名不为空 然后取得用户对应的 用户ID (因为 我在做Lucene 是用用户id 来标记的)
if (!string.IsNullOrEmpty(blogName))
{
key = key.Substring(key.IndexOf(' '));
var userinfo = CacheData.GetAllUserInfo().Where(t => t.UserName == blogName).FirstOrDefault();
if (null != userinfo)
userid = userinfo.Id.ToString();
}
string pIndex = Request.QueryString.AllKeys.Contains("p") ? Request.QueryString["p"] : "";
int PageIndex = 1;
int.TryParse(pIndex, out PageIndex);
int PageSize = 10;
var searchlist = PanGuLuceneHelper.instance.Search(userid, key, PageIndex, PageSize);
return PartialView(searchlist);
}
#endregion2. 必应搜索
#region 加载 bing 的搜索结果
/// <summary>
/// 加载 bing 的搜索结果
/// </summary>
/// <returns></returns>
public ActionResult ShowBingResult()
{
if (!Request.QueryString.AllKeys.Contains("key"))
return null;
string key = Request.QueryString["key"];//搜索关键字
JumonyParser jumony = new JumonyParser();
//http://cn.bing.com/search?q=AJAX+site%3ablog.haojima.net&first=11&FORM=PERE
string pIndex = Request.QueryString.AllKeys.Contains("p") ? Request.QueryString["p"] : "";
int PageIndex = 1;
int.TryParse(pIndex, out PageIndex);
PageIndex--;
//如:blog:JeffreyZhao 博客
var zhankey = key.Split(' ');//先用空格分割
var blogName = string.Empty;
if (zhankey.Length >= 2)
{
var str = zhankey[0].Trim();
if (str.Length > 6 && str.Substring(0, 5) == "blog:")
blogName = "/" + str.Substring(5);//这里取得 用户名
}
if (!string.IsNullOrEmpty(blogName))
key = key.Substring(key.IndexOf(' '));
//如:
var url = "http://cn.bing.com/search?q=" + key + "+site:" + siteUrl + blogName + "&first=" + PageIndex + "1&FORM=PERE";
var document = jumony.LoadDocument(url); var list = document.Find("#b_results .b_algo").ToList().Select(t => t.ToString()).ToList();
var listli = document.Find("li.b_pag nav ul li");
if (PageIndex > 0 && listli.Count() == 0)
return null;
if (listli.Count() > 1)
{
var text = document.Find("li.b_pag nav ul li").Last().InnerText();
int npage = -1;
if (text == "下一页")
{
if (listli.Count() > 1)
{
var num = listli.ToList()[listli.Count() - 2].InnerText();
int.TryParse(num, out npage);
}
}
else
int.TryParse(text, out npage);
if (npage <= PageIndex)
list = null;
}
return PartialView(list);
}
#endregion
看看 我们的搜索结果的效果图吧。

总结
首先 搜索是必不可少的功能,但又不是主要功能。那么我们可以直接用lucene.net 来做搜索,然后用必应搜索做备用。但是 用必应 有个弊端。就是 如果我们 的文章页面 被用户自己删除了,而 必应已经收录了,那么 我们在搜索结果页面 点击 可能就是404 或 500 了。当然 我们自己的 lucene.net 也会有这个 问题,我们可以在用户删除 文章的时候 也删除 对应的那天搜索索引就好了。演示地址:http://blog.haojima.net/Search/Index?key=blog:zhaopei 博客&p=1
如果您对本篇文章感兴趣,那就麻烦您点个赞,您的鼓励将是我的动力。 当然您还可以加入QQ群:

讨论。
如果您有更好的处理方式,希望不要吝啬赐教。
一步步开发自己的博客 .NET版系列:http://www.cnblogs.com/zhaopei/tag/Hi-Blogs/
本文链接:/article/5218493.html

相关文章推荐
- 关于向上造型的思考
- ssh不能远程登录问题解决 & hosts.allow/howts.deny书写规则
- OpenCV300 CMake生成project在项目过程中的问题
- hdu5442 Favorite Donut 后缀数组 长春网赛
- Topcoder SRM 663 DIV 1
- mysql 显示行号,以及分组排序
- Linux驱动之input输入子系统
- Win8.1预订升级Win10失败的解决方法
- 华哥倒酒(二分答案)
- Codeforces 577B
- WPF 和 Win32 互操作
- oc 字符串长度,两个英文占一个长度
- mongodb分片集群实战搭建
- 超级课程表原理解析(如何获取网页内容)
- flask 如何传参数到 js中,避免& # 39等转义
- C++STL
- 采用dlopen、dlsym、dlclose dlopen dlerror加载动态链接库【总结】
- 为客户打造RAC-DG一些遇到的问题汇总
- memcached 在windows下的安装和使用
- node.js在windows下的安装与配置(附sublime-text的配置)