模糊kmeans聚类
2015-08-30 18:03
211 查看
首先介绍一个,FuzzyKMeans算法的主要思想:
模糊均值聚类(FCM),即众所周知的模糊ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。1973年,Bezdek提出了该算法,作为早期硬均值聚类(HCM)方法的一种改进。FCM把 n 个向量 xi(i=1,2,…,n)分为 c 个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM 使得每个给定数据点用值在 0,1 间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵 U 允许有取值在 0,1 间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于 1:
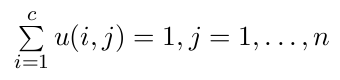
那么,FCM的价值函数(或目标函数)就是下式一般化形式:
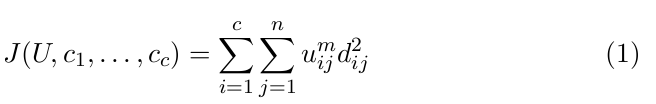
这里 uij 介于 0,1 间;ci 为模糊组 i 的聚类中心,dij=||ci-xj||为第 i 个聚类中心与第 j 个数据点间的欧几里德距离;且 m (属于1到无穷) 是一个加权指数。
构造如下新的目标函数,可求得使下式达到最小值的必要条件:其实就是拉格朗日乘子法:
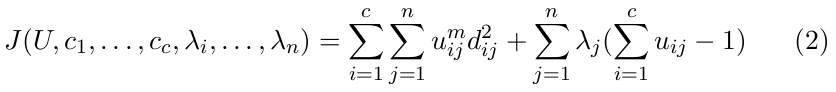
对上式所有输入参量求导,使上式达到最小的必要条件为:

和
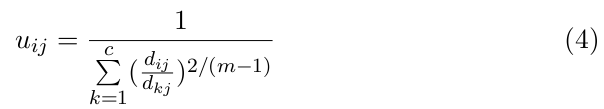
由上述两个必要条件,模糊 C 均值聚类算法是一个简单的迭代过程。在批处理方式运行时,
FCM 用下列步骤确定聚类中心 ci 和隶属矩阵 U[1]:
步骤 1:用值在 0,1 间的随机数初始化隶属矩阵 U
步骤 2:用式(3)计算 c 个聚类中心 ci,i=1,…,c。
步骤 3:根据式(1)计算价值函数。如果它小于某个确定的阀值,或它相对上次价
值函数值的改变量小于某个阀值,则算法停止。
步骤 4:用(4)计算新的 U 矩阵和。返回步骤 2。
上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保 FCM 收敛于一个最优解。算法的性能依赖于初始聚类中心。因此,我们要么用另外的快速算法确定初始
聚类中心,要么每次用不同的初始聚类中心启动该算法,多次运行 FCM。
notes: 上面讨论不难看出二个参数比较重要:1.聚类的数目,2.控制算法的柔软参数m,如果m过大,则聚类的效果很差,如果m过小,则算法接近Kmeans算法。
这里有该算法的mahout实现,本篇文章也是摘抄于此:
http://www.cnblogs.com/liqizhou/archive/2012/05/10/2473174.html
模糊均值聚类(FCM),即众所周知的模糊ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。1973年,Bezdek提出了该算法,作为早期硬均值聚类(HCM)方法的一种改进。FCM把 n 个向量 xi(i=1,2,…,n)分为 c 个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM 使得每个给定数据点用值在 0,1 间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵 U 允许有取值在 0,1 间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于 1:
那么,FCM的价值函数(或目标函数)就是下式一般化形式:
这里 uij 介于 0,1 间;ci 为模糊组 i 的聚类中心,dij=||ci-xj||为第 i 个聚类中心与第 j 个数据点间的欧几里德距离;且 m (属于1到无穷) 是一个加权指数。
构造如下新的目标函数,可求得使下式达到最小值的必要条件:其实就是拉格朗日乘子法:
对上式所有输入参量求导,使上式达到最小的必要条件为:
和
由上述两个必要条件,模糊 C 均值聚类算法是一个简单的迭代过程。在批处理方式运行时,
FCM 用下列步骤确定聚类中心 ci 和隶属矩阵 U[1]:
步骤 1:用值在 0,1 间的随机数初始化隶属矩阵 U
步骤 2:用式(3)计算 c 个聚类中心 ci,i=1,…,c。
步骤 3:根据式(1)计算价值函数。如果它小于某个确定的阀值,或它相对上次价
值函数值的改变量小于某个阀值,则算法停止。
步骤 4:用(4)计算新的 U 矩阵和。返回步骤 2。
上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保 FCM 收敛于一个最优解。算法的性能依赖于初始聚类中心。因此,我们要么用另外的快速算法确定初始
聚类中心,要么每次用不同的初始聚类中心启动该算法,多次运行 FCM。
notes: 上面讨论不难看出二个参数比较重要:1.聚类的数目,2.控制算法的柔软参数m,如果m过大,则聚类的效果很差,如果m过小,则算法接近Kmeans算法。
这里有该算法的mahout实现,本篇文章也是摘抄于此:
http://www.cnblogs.com/liqizhou/archive/2012/05/10/2473174.html

相关文章推荐
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析
- C++实现汉诺塔算法经典实例
- PHP实现克鲁斯卡尔算法实例解析
- C#获取关键字附近文字算法实例