oneproxy中间件架构及注意事项
2015-08-17 10:12
477 查看
分布式数据库实现方案总体划分为两类:
一类是程序客户端实现,对一个已有的业务来说,会涉及过多的代码改动甚至是程序逻辑上的调整。
另一类是采用中间件proxy方案,前段代码改动小,通过proxy实现。
架构图如下:
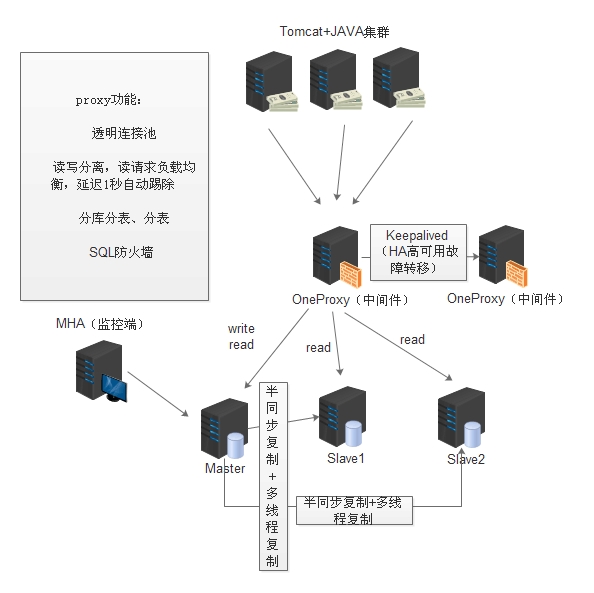
---------------------------------------------------------------------------------------
这里总结一下JAVA程序mybatis框架连接后的注意事项:
1、不支持 Server Side Cursor 接口,比如 MySQL C API 里的 Prepare、Bind、 Execute调用接口
2、不支持 use命令切换数据库
3、默认禁止 CALL, PREPARE, EXECUTE, DEALLOCATE 命令,也就是说不能用存储过程
3、单库(单实例)分表--insert/update/delete要加字段名,如insert into t1(id,name) values(1,'张三');
4、单库(单实例)分表--目前分了N张表,如果以自增id做关联查询,那么每张表的自增id都是从1开始,在与其他表join关联查询时,数据会不准确
5、单库(单实例)分表--当where条件有分区列时,值不能有函数转换,也不能有算术表达式,必须是原子值,否则结果不准确
6、分库分表(多实例)--不支持垮库join,例如user_0表在10.0.0.1机器里,现在要join关联查询10.0.0.2机器里的money_detail表,不支持
7、分库分表(多实例)--不支持分布式事务,例如user_0表在10.0.0.1机器里,user_1表在10.0.0.2机器里,现在想同时update更新两张表,不支持
---------------------------------------------------------------------------------------
8、读写分离 --默认读操作全部访问slave,如果想强制走主库,例如涉及金钱类的查询操作,SQL改为select /*master*/ from t1 where id=1;
9、分库分表/分表 --where条件带分区列时,直接命中该表,如果未带分区列,会逐一扫描所有分表(单线程),考虑性能问题,要加并行查询(多线程),SQL改为select /*parallel*/ from t1 where name='李四'; 并行查询会增加额外的CPU消耗
----------------------------------------------------------------------------------------
10、分表规则:支持range(范围),hash(取模),hash规则要提前规划好,具体分多少张表,如前期分64张表,1年后想扩容128张表,数据需要重新导出导入,成本非常高,目前二级分表还不支持。
本文出自 “贺春旸的技术专栏” 博客,请务必保留此出处http://hcymysql.blog.51cto.com/5223301/1685146
一类是程序客户端实现,对一个已有的业务来说,会涉及过多的代码改动甚至是程序逻辑上的调整。
另一类是采用中间件proxy方案,前段代码改动小,通过proxy实现。
架构图如下:
---------------------------------------------------------------------------------------
这里总结一下JAVA程序mybatis框架连接后的注意事项:
1、不支持 Server Side Cursor 接口,比如 MySQL C API 里的 Prepare、Bind、 Execute调用接口
2、不支持 use命令切换数据库
3、默认禁止 CALL, PREPARE, EXECUTE, DEALLOCATE 命令,也就是说不能用存储过程
3、单库(单实例)分表--insert/update/delete要加字段名,如insert into t1(id,name) values(1,'张三');
4、单库(单实例)分表--目前分了N张表,如果以自增id做关联查询,那么每张表的自增id都是从1开始,在与其他表join关联查询时,数据会不准确
5、单库(单实例)分表--当where条件有分区列时,值不能有函数转换,也不能有算术表达式,必须是原子值,否则结果不准确
6、分库分表(多实例)--不支持垮库join,例如user_0表在10.0.0.1机器里,现在要join关联查询10.0.0.2机器里的money_detail表,不支持
7、分库分表(多实例)--不支持分布式事务,例如user_0表在10.0.0.1机器里,user_1表在10.0.0.2机器里,现在想同时update更新两张表,不支持
---------------------------------------------------------------------------------------
8、读写分离 --默认读操作全部访问slave,如果想强制走主库,例如涉及金钱类的查询操作,SQL改为select /*master*/ from t1 where id=1;
9、分库分表/分表 --where条件带分区列时,直接命中该表,如果未带分区列,会逐一扫描所有分表(单线程),考虑性能问题,要加并行查询(多线程),SQL改为select /*parallel*/ from t1 where name='李四'; 并行查询会增加额外的CPU消耗
----------------------------------------------------------------------------------------
10、分表规则:支持range(范围),hash(取模),hash规则要提前规划好,具体分多少张表,如前期分64张表,1年后想扩容128张表,数据需要重新导出导入,成本非常高,目前二级分表还不支持。
本文出自 “贺春旸的技术专栏” 博客,请务必保留此出处http://hcymysql.blog.51cto.com/5223301/1685146

相关文章推荐
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案
- 推荐一个免费SSL证书申请网站
- repo命令无法从gooole的网站下载问题解决办法
- 给网站外链进行重定向跳转
- 网站设计
- 如何获取网站Icon
- 中国最大的25个网站采用技术选型方案
- 中国最大的25个网站采用技术选型方案
- 浅谈图片服务器的架构演进
- 浅谈图片服务器的架构演进
- 大型网站架构演变和知识体系
- 前端学习网站
- 在Ubuntu上配置django环境系统架构命令
- 编译安装lamp架构(基于fastcgi)
- 软件架构设计
- LVS + KEEPALIVED + WINDOWS SERVER 2008 R2 ------高可用负载均衡
- 雪球在股市风暴下的高可用架构改造分享 | 首席架构师亲述应对30倍峰值历程
- 股市风暴下的雪球架构改造经验分享
- 架构之路:前言目录
- 电子书下载网站整理