特征选择与特征抽取的区别(总结)
2015-08-08 16:33
225 查看
本篇博客的目的不是深刻的讲解特征提取和特征选择的方法,而是区分清楚他们之间的关系和区别,让大家对特征抽取 特征选择 PCA LDA有个概念框架上的了解,为大家的下一步的深入理解打好基础。 如果我的理解有问题,请大家提出意见,互相交流。本文来自csdn
1.特征抽取 V.S 特征选择
特征抽取和特征选择是DimensionalityReduction(降维)的两种方法,针对于the curse of dimensionality(维灾难),都可以达到降维的目的。但是这两个有所不同。
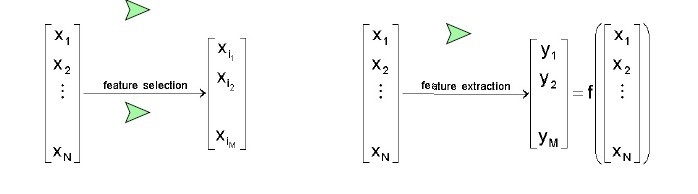
特征抽取(Feature Extraction):Creatting a subset of new features by combinations of the exsiting features.也就是说,特征抽取后的新特征是原来特征的一个映射。
特征选择(Feature Selection):choosing a subset of all the features(the ones more informative)。也就是说,特征选择后的特征是原来特征的一个子集。
2. PCA V.S LDA
主成分分析(Principle Components Analysis ,PCA)和线性评判分析(Linear Discriminant Analysis,LDA)是特征抽取的两种主要经典方法。
对于特征抽取,有两种类别:
(1)Signal representation(信号表示): The goal of the feature extraction mapping is to
represent the samples accurately in a low-dimensional space. 也就是说,特征抽取后的特征要能够精确地表示样本信息,使得信息丢失很小。对应的方法是PCA.
(2)Signal classification(信号分类): The goal of the feature extraction mapping is toenhance the class-discriminatory information in a low-dimensional space. 也就是说,特征抽取后的特征,要使得分类后的准确率很高,不能比原来特征进行分类的准确率低。对与线性来说,对应的方法是LDA
. 非线性这里暂时不考虑。
可见,
PCA和LDA两种方法的目标不一样,因此导致他们的方法也不一样。PCA得到的投影空间是协方差矩阵的特征向量,而LDA则是通过求得一个变换W,使得
变换之后的新均值之差最大、方差最大(也就是最大化类间距离和最小化类内距离),变换W就是特征的投影方向。
如果想进一步了解PCA,请见 http://blog.csdn.net/j123kaishichufa/article/details/7614234 点击打开链接
1.特征抽取 V.S 特征选择
特征抽取和特征选择是DimensionalityReduction(降维)的两种方法,针对于the curse of dimensionality(维灾难),都可以达到降维的目的。但是这两个有所不同。
特征抽取(Feature Extraction):Creatting a subset of new features by combinations of the exsiting features.也就是说,特征抽取后的新特征是原来特征的一个映射。
特征选择(Feature Selection):choosing a subset of all the features(the ones more informative)。也就是说,特征选择后的特征是原来特征的一个子集。
2. PCA V.S LDA
主成分分析(Principle Components Analysis ,PCA)和线性评判分析(Linear Discriminant Analysis,LDA)是特征抽取的两种主要经典方法。
对于特征抽取,有两种类别:
(1)Signal representation(信号表示): The goal of the feature extraction mapping is to
represent the samples accurately in a low-dimensional space. 也就是说,特征抽取后的特征要能够精确地表示样本信息,使得信息丢失很小。对应的方法是PCA.
(2)Signal classification(信号分类): The goal of the feature extraction mapping is toenhance the class-discriminatory information in a low-dimensional space. 也就是说,特征抽取后的特征,要使得分类后的准确率很高,不能比原来特征进行分类的准确率低。对与线性来说,对应的方法是LDA
. 非线性这里暂时不考虑。
可见,
PCA和LDA两种方法的目标不一样,因此导致他们的方法也不一样。PCA得到的投影空间是协方差矩阵的特征向量,而LDA则是通过求得一个变换W,使得
变换之后的新均值之差最大、方差最大(也就是最大化类间距离和最小化类内距离),变换W就是特征的投影方向。
如果想进一步了解PCA,请见 http://blog.csdn.net/j123kaishichufa/article/details/7614234 点击打开链接

相关文章推荐
- MySQL性能调优与架构设计——第4章 MySQL安全管理
- Java:谈谈protected访问权限
- 策略模式
- Vim学习之一
- 学习爬虫过程中遇到的问题总结
- Notification实现状态通知栏
- hdu 4006 The kth great number
- Binary Tree Inorder Traversal
- 附两个自己认为比较重要的链接地址(移动端的position:fixed,flexbox实现垂直居中布局)
- 输入一组大于等于0的整数,根据从大到小的顺序排序后输出;如果排序后有连续数时,只输出连续输的最大和最小数。
- 【HDOJ 4968】 Improving the GPA
- (大数据工程师学习路径)第一步 Linux 基础入门----文件系统操作与磁盘管理
- 使用CSplitterWnd类分割窗体,拆分窗体
- HDU 4006 POJ 2828 线段树(排列/找有序位置)
- django下ajax请求403(FORBIDDEN)的解决办法
- Keil的片外RAM区支持设置
- int to str
- 活用mysql的binlog进行数据恢复
- 一个人的旅行
- 文件系统(3.6)------嵌入式系统软件及操作系统知识