lucene索引
2015-08-03 09:59
323 查看
一、lucene索引
1、文档层次结构
索引(Index):一个索引放在一个文件夹中;
段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段;
文档(Document):文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档;
域(Field):一个文档包含不同类型的信息,可以拆分开索引;
词(Term):词是索引的最小单位,是经过词法分析和语言处理后的数据;
文档是Lucene索引和搜索的原子单位,文档为包含一个或多个域的容器,而域则依次包含“真正的”被搜索内容,域值通过分词技术处理,得到多个词元。如一篇小说信息可以称为一个文档;小说信息又包含多个域,比如标题,作者、简介、最后更新时间等;对标题这一个域采用分词技术,又可以等到一个或多个词元。
2、正向索引与反向索引
正向索引:文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。正向信息就是按层次保存了索引一直到词的包含关系: 索引 -> 段-> 文档 -> 域 -> 词
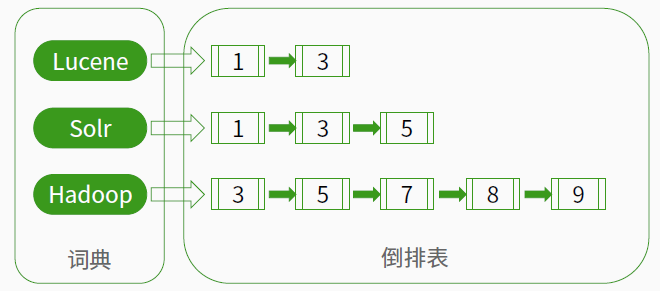
反向索引:一种以索引项为中心来组织文档的方式,每个索引项指向一个文档序列,这个序列中的文档都包含该索引项。反向信息保存了词典的倒排表映射:词 -> 文档
lucene使用到的就是反向索引。如下图所示:
二、索引操作
相关示例如下:
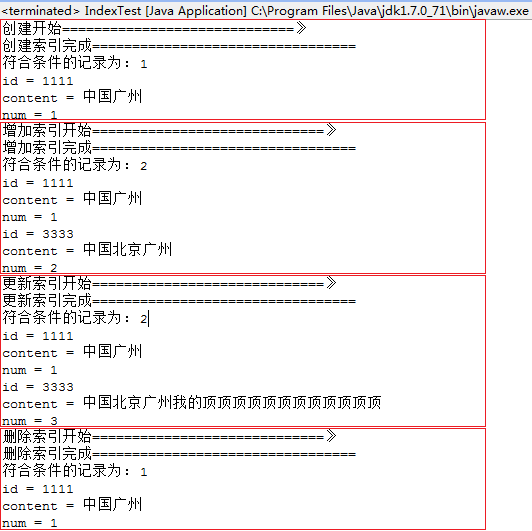
运行结果如下:
1、文档层次结构
索引(Index):一个索引放在一个文件夹中;
段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段;
文档(Document):文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档;
域(Field):一个文档包含不同类型的信息,可以拆分开索引;
词(Term):词是索引的最小单位,是经过词法分析和语言处理后的数据;
文档是Lucene索引和搜索的原子单位,文档为包含一个或多个域的容器,而域则依次包含“真正的”被搜索内容,域值通过分词技术处理,得到多个词元。如一篇小说信息可以称为一个文档;小说信息又包含多个域,比如标题,作者、简介、最后更新时间等;对标题这一个域采用分词技术,又可以等到一个或多个词元。
2、正向索引与反向索引
正向索引:文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。正向信息就是按层次保存了索引一直到词的包含关系: 索引 -> 段-> 文档 -> 域 -> 词
反向索引:一种以索引项为中心来组织文档的方式,每个索引项指向一个文档序列,这个序列中的文档都包含该索引项。反向信息保存了词典的倒排表映射:词 -> 文档
lucene使用到的就是反向索引。如下图所示:
二、索引操作
相关示例如下:
package com.test.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 索引增删改查
*/
public class IndexTest {
/**
* 创建索引
*
* @param path
* 索引存放路径
*/
public static void create(String path) {
System.out.println("创建开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开
Directory directory = null;
IndexWriter indexWriter = null;
// 文档一
Document doc1 = new Document();
doc1.add(new StringField("id", "1111", Store.YES));
doc1.add(new TextField("content", "中国广州", Store.YES));
doc1.add(new IntField("num", 1, Store.YES));
// 文档二
Document doc2 = new Document();
doc2.add(new StringField("id", "2222", Store.YES));
doc2.add(new TextField("content", "中国上海", Store.YES));
doc2.add(new IntField("num", 2, Store.YES));
try {
directory = FSDirectory.open(Paths.get(path));// 索引在硬盘上的存储路径
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2);
// 将indexWrite操作提交,如果不提交,之前的操作将不会保存到硬盘
// 但是这一步很消耗系统资源,索引执行该操作需要有一定的策略
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("创建索引完成=================================");
}
/**
* 添加索引
*
* @param path
* 索引存放路径
* @param document
* 添加的文档
*/
public static void add(String path, Document document) {
System.out.println("增加索引开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开
Directory directory = null;
IndexWriter indexWriter = null;
try {
directory = FSDirectory.open(Paths.get(path));// 索引在硬盘上的存储路径
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.addDocument(document);
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("增加索引完成=================================");
}
/**
* 删除索引
*
* @param indexpath
* 索引存放路径
* @param id
* 文档id
*/
public static void delete(String indexpath, String id) {
System.out.println("删除索引开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开
IndexWriter indexWriter = null;
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(indexpath));// 索引在硬盘上的存储路径
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.deleteDocuments(new Term("id", id));// 删除索引操作
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("删除索引完成=================================");
}
/**
* Lucene没有真正的更新操作,通过某个fieldname,可以更新这个域对应的索引,但是实质上,它是先删除索引,再重新建立的。
*
* @param indexpath
* 索引存放路径
* @param newDoc
* 更新后的文档
* @param oldDoc
* 需要更新的目标文档
*/
public static void update(String indexpath, Document newDoc, Document oldDoc) {
System.out.println("更新索引开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter indexWriter = null;
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(indexpath));
indexWriter = new IndexWriter(directory, config);
indexWriter.updateDocument(new Term("id", oldDoc.get("id")), newDoc);
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("更新索引完成=================================");
}
/**
* 搜索
*
* @param keyword
* 关键字
* @param indexpath
* 索引存放路径
*/
public static void search(String keyword, String indexpath) {
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(indexpath));// 索引硬盘存储路径
DirectoryReader directoryReader = DirectoryReader.open(directory);// 读取索引
IndexSearcher searcher = new IndexSearcher(directoryReader);// 创建索引检索对象
Analyzer analyzer = new SmartChineseAnalyzer();// 分词技术
QueryParser parser = new QueryParser("content", analyzer);// 创建Query
Query query = parser.parse(keyword);// 查询content为广州的
// 检索索引,获取符合条件的前10条记录
TopDocs topDocs = searcher.search(query, 10);
if (topDocs != null) {
System.out.println("符合条件的记录为: " + topDocs.totalHits);
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
Document doc = searcher.doc(topDocs.scoreDocs[i].doc);
System.out.println("id = " + doc.get("id"));
System.out.println("content = " + doc.get("content"));
System.out.println("num = " + doc.get("num"));
}
}
directory.close();
directoryReader.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
/**
* 测试代码
* @param args
*/
public static void main(String[] args) {
String indexpath = "D://index/test";
create(indexpath);// 创建索引
search("广州", indexpath);
Document doc = new Document();
doc.add(new StringField("id", "3333", Store.YES));
doc.add(new TextField("content", "中国北京广州", Store.YES));
doc.add(new IntField("num", 2, Store.YES));
add(indexpath, doc);// 添加索引
search("广州", indexpath);
Document newDoc = new Document();
newDoc.add(new StringField("id", "3333", Store.YES));
newDoc.add(new TextField("content", "中国北京广州我的顶顶顶顶顶顶顶顶顶顶顶顶", Store.YES));
newDoc.add(new IntField("num", 3, Store.YES));
update(indexpath, newDoc, doc);// 更新索引
search("广州", indexpath);
delete(indexpath, "3333");// 删除索引
search("广州", indexpath);
}
}运行结果如下:

相关文章推荐
- 进程与线程的一个简单解释
- 南邮 OJ 1008 第几天
- 如何把PPT转成PDF格式保存
- android 微信支付直接跳转结果
- shell 变量和参数
- 红黑树
- C语言编程入门——动态内存分配
- mysql 备份与还原
- 关于栈、堆、静态变量区的访问效率
- 从优化到再优化,最长公共子串
- 南邮 OJ 1007 完美立方
- 对线性回归,logistic回归和一般回归的认识
- limit是mysql的语法
- MES的关键数据模型S95标准介绍
- IOS学习笔记3 - 关于Info.plist
- 员工借款及还款场景演练
- Linux学习-ps aux指令
- php 中的 short_open_tag 的作用
- Docker: Not Even a Linker
- 业务逻辑层:Model 层的分析