oracle树形查询 start with connect by
2015-10-30 16:16
686 查看
一、简介
在oracle中start with connect by (prior) 用来对树形结构的数据进行查询。其中start with conditon 给出的是数据搜索范围, connect by后面给出了递归查询的条件,prior 关键字表示父数据,prior 条件表示子数据需要满足父数据的什么条件。如下
start with id= '10001' connect by prior parent_id= id and prior num = 5
表示查询id为10001,并且递归查询parent_id=id,为5的记录。
二、实例
1、构造数据
生成的菜单层次结构如下:
顶级菜单1
菜单11
菜单12
菜单13
菜单131
菜单132
菜单1321
菜单1322
菜单133
菜单14
顶级菜单2
菜单21
菜单22
菜单23
顶级菜单3
菜单31
2、SQL查询


三、性能问题
对于 start with connect by语句的执行,oracle会进行递归查询,当数据量大的时候会产生性能相关问题。
语句执行计划结果如下:
通过该执行计划得知,改语句执行了7步操作,才将结果集查询并返回。当需要查询条件进行过滤的时候,我们可以通过查看执行计划从而对sql进行优化。
在oracle中start with connect by (prior) 用来对树形结构的数据进行查询。其中start with conditon 给出的是数据搜索范围, connect by后面给出了递归查询的条件,prior 关键字表示父数据,prior 条件表示子数据需要满足父数据的什么条件。如下
start with id= '10001' connect by prior parent_id= id and prior num = 5
表示查询id为10001,并且递归查询parent_id=id,为5的记录。
二、实例
1、构造数据
-- 表结构
create table menu(
id varchar2(64) not null,
parent_id varchar2(64) not null,
name varchar2(100) not null,
depth number(2) not null,
primary key (id)
)
-- 初始化数据
-- 顶级菜单
insert into menu values ('100000', '0', '顶级菜单1', 1);
insert into menu values ('200000', '0', '顶级菜单2', 1);
insert into menu values ('300000', '0', '顶级菜单3', 1);
-- 父级菜单
-- 顶级菜单1 直接子菜单
insert into menu values ('110000', '100000', '菜单11', 2);
insert into menu values ('120000', '100000', '菜单12', 2);
insert into menu values ('130000', '100000', '菜单13', 2);
insert into menu values ('140000', '100000', '菜单14', 2);
-- 顶级菜单2 直接子菜单
insert into menu values ('210000', '200000', '菜单21', 2);
insert into menu values ('220000', '200000', '菜单22', 2);
insert into menu values ('230000', '200000', '菜单23', 2);
-- 顶级菜单3 直接子菜单
insert into menu values ('310000', '300000', '菜单31', 2);
-- 菜单13 直接子菜单
insert into menu values ('131000', '130000', '菜单131', 3);
insert into menu values ('132000', '130000', '菜单132', 3);
insert into menu values ('133000', '130000', '菜单133', 3);
-- 菜单132 直接子菜单
insert into menu values ('132100', '132000', '菜单1321', 4);
insert into menu values ('132200', '132000', '菜单1332', 4);生成的菜单层次结构如下:
顶级菜单1
菜单11
菜单12
菜单13
菜单131
菜单132
菜单1321
菜单1322
菜单133
菜单14
顶级菜单2
菜单21
菜单22
菜单23
顶级菜单3
菜单31
2、SQL查询
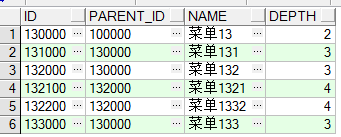
--prior放的左右位置决定了检索是自底向上还是自顶向下. 左边是自上而下(找子节点),右边是自下而上(找父节点) --找父节点 select * from menu start with id='130000' connect by id = prior parent_id;
--找子节点节点 -- (子节点)id为130000的菜单,以及130000菜单下的所有直接或间接子菜单(prior 在左边, prior、parent_id(等号右边)在右边) select * from menu start with id='130000' connect by prior id = parent_id ;
-- (父节点)id为1321的菜单,以及1321菜单下的所有直接或间接父菜单(prior、parent_id(等号左边) 都在左边) select * from menu start with id='132100' connect by prior parent_id = id; -- prior 后面跟的是(parent_id) 则是查找父节点,prior后面跟的是(id)则是查找子节点
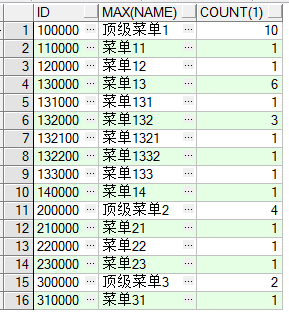
--根据菜单组分类统计每个菜单包含子菜单的个数 select id, max(name) name, count(1) from menu group by id connect by prior parent_id = id order by id
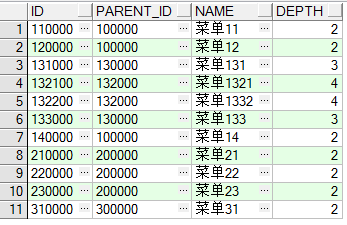
-- 查询所有的叶子节点 select t2.* from menu t2 where id not in(select t.parent_id from menu t) order by id;
三、性能问题
对于 start with connect by语句的执行,oracle会进行递归查询,当数据量大的时候会产生性能相关问题。
--生成执行计划 explain plan for select * from menu start with id='132100' connect by prior parent_id = id; -- 查询执行计划 select * from table( dbms_xplan.display);
语句执行计划结果如下:
Plan hash value: 3563250490
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 133 | 1 (0)| 00:00:01 |
|* 1 | CONNECT BY WITH FILTERING | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | MENU | 1 | 133 | 1 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | SYS_C0018586 | 1 | | 1 (0)| 00:00:01 |
| 4 | NESTED LOOPS | | | | | |
| 5 | CONNECT BY PUMP | | | | | |
| 6 | TABLE ACCESS BY INDEX ROWID| MENU | 1 | 133 | 1 (0)| 00:00:01 |
|* 7 | INDEX UNIQUE SCAN | SYS_C0018586 | 1 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"=PRIOR "PARENT_ID")
3 - access("ID"='132100')
7 - access("ID"=PRIOR "PARENT_ID")
Note
-----
- dynamic sampling used for this statement通过该执行计划得知,改语句执行了7步操作,才将结果集查询并返回。当需要查询条件进行过滤的时候,我们可以通过查看执行计划从而对sql进行优化。

相关文章推荐
- maven中引入oracle驱动报错Missing artifact com.oracle:ojdbc14:jar:10.2.0.4.0
- 连接oracle数据库
- oracle 过程函数,包的区别和联系
- oracle锁表
- 【参数】REMOTE_LOGIN_PASSWORDFILE参数三种取值及其行为特性分析
- oracle bitmap join index
- ORACLE查看存储过程
- Oracle 日志归档 自动清理
- ORACLE存储过程的创建(1)
- 甲骨文CEO马克·赫德预测十年后云产业五大趋势
- oracle全文检索
- Oracle—自定义function语法(转载)
- hp-pa安装oracle和bash
- oracle系统包——dbms job用法(oracle定时任务)
- Oracle默认初始化用户密码
- Oracle 存储过程
- EBS form日历可选范围设置(calendar.setup )介绍
- dataguard 中standby有大量gap解决方法
- Oracle 存储过程(procedure)和函数(Function)的区别(转载)
- Oracle序列