【编程珠玑】陪着奶猫看看书--《编程珠玑》第一章
2015-07-31 03:44
309 查看
陪着奶猫看看书–《编程珠玑》第一章
首先说说小奶猫我为什么要读《编程珠玑》这本神作,当年小奶猫刚刚进入大学时候是个纯洁的少年,啥都不懂,要是哪个女生下午在外面问我带身份证没有,我指定告诉她我不想去网吧。除了纯洁,小奶猫当时一直以为自己是学计算机的料,天天拿着“谁能告诉我,为什么我不能成为下一个马云?”的口号到处吓唬人,于是一去学校就到处抱大神的大腿,主动到实验室去找大神“取经”,当时大神们玩的是Linux系统,直接看不懂(当时并不知道系统的意思是啥),觉得这NM果然是大神。大神们争先恐后的向我灌输“计算机是个好专业”“程序等于数据结构加算法”“算法最难”……等等思想。那好,都这么说,推荐几本书呗,于是乎拿到了书单《算法导论》《数据结构与算法》……,记忆深刻啊,回去就买了《算法导论》开撸,越撸越觉得不对劲,都讲的啥啊,第一章都没看完就彻底疯了,于是下定决心——再不读《算法导论》了,虐心。
被《算法导论》虐了之后,一直不敢选关于算法的课,怂!直到后来看到了大神lucida的博客,哎呀我去,吓死宝宝了。大神一人撸遍所有牛逼IT公司,大神的书单必须得读啊。那为啥要选《编程珠玑》呢?因为看了博客1小时后小奶猫我只记得这个名字了!!!
好吧,扯多了!入正题吧!
编程珠玑第一章——开篇
编程珠玑第一章只写了10面5页纸,看得认真的20分钟就可以看完,不认真的,直接跳到第6页了。小奶猫第一遍看的时候的感觉是:这作者太啰嗦了!
就讲了一个问题:
输入:一个最多包含n个正整数的文件,每个数都小于n,其中n=。如果在输入文件中有任何整数重复出现就是致命错误。没有其他数据与该整数相关联。
输出:按升序排列的输入整数的列表。
约束:最多有(大约)1MB的内存空间可用,有充足的磁盘存储空间可用。运行时间最多几分钟,运行时间为10秒就不需要进一步优化。
第一种解决方案——八大排序
小奶猫第一反应是,要排序啊,后面肯定要讲八大排序之一的某个,果不其然出现了归并排序,可是由于1MB的内存限制,不得不多次利用工作文件,既然这么说,那这个算法绝对就不是这个问题的最佳解了,不然这本书就没意思了!
第二种解决方案——问题分解为多趟排序
好吧,不会做了怎么办?返回来再看题目!1MB是多大?1MB是个字节,约等于个字节(),以一个int型数据占4字节算,就能存放25万个整数,而输入数据有1000万个整数,就是得分40次读入数据,然后排序。好,到这里,问题来了,就算分了40次读入,怎么排序呢?书上就给了一幅图,又没看懂,这40次读入,是每次读入的数据呢?还是每次把输入文件从头到尾读1遍,然后读40遍呢?假设每次读入的数据,这数据又是乱序的,读入的是局部乱序数据,范围也不清楚,发呆半小时还是不知道怎么办。换另一个思维,假设每次把输入文件从头到尾读1遍,而不是只读了的数据,内存中有1到25万个位置,当输入中出现在1到25万范围内的数据时,在内存中对应位置写上这个数,从头到尾读输入1次后,把所有数据中在范围1到25万中的数据全部找出来,此时输出的话,肯定就是1到25万范围内的有序数列,并且输入中在此范围内的数据一个不漏。后续重复这个步骤检测25万到50万……,最后输出有序文件。
第三种解决方案——巧妙的数据存储单元“位”
书中开篇的第二个排序思想就这样了,可是还没结束,后面还有一个算法,也是让小奶猫脑洞大开的算法(见过的可能觉得没啥,没见过的就觉得有点意思了),是怎么样的呢?我们有输入数据,并且知道输入数据在1000万以内,还都只出现了一次,那根本问题就是确定某个数出现了还是没出现,就只有这两种状态,用计算机表示2种状态怎么表示?True和false。此时还有内存限制,怎么样用最小的数据类型表示true和false?位!!!直接去new一个位数组,数组下标正好是1到1000万,哪个数出现就将数组的哪个下标元素内的值改为1,否则为0,;将文件从头至尾读一遍,出现的标1,其他标0,最后循环一遍数组,输出元素值为1的数组下标,输出就是输入的有序排列了。大功告成!那内存呢,1MB=B=8*b,即800万个位,1000万位的内存消耗为1.25MB,不严格控制就近似用了1MB内存,时间消耗肯定是O(n)级别了。
总结
1、一定得熟悉基本的数据类型和数据结构。读完第一章最大的感慨是居然可以用位存储来进行排序,要是不在这里见一次,杀了我,我可能都想不出来。有时候就觉得,程序的算法不是你自己不会设计,而是你视野控制了你的设计思路,见都没见过,你能研究出来的话,你可能就是某个绝佳算法的设计者了。见得多,水平也就起来了,即使不做研究,熟悉绝大部分算法也够你牛逼一阵了!
2、数据本身特征分析会给程序结构带来很大的改进。书中说了,这个例子太特殊,满足了3个不常见的属性:输入数据限制在相对较小的范围内;数据没有重复;而且对于每条记录而言,除单一整数外,没有任何其他关联数据。数据本身的特征才决定了特定算法的产生。以后得注意了!
3、排序在有对比标识的时候可将复杂度降为O(n)。最后这种算法之所以能成功,还有一个重要特点,就是数组存的时候,数组是带有下标。这样就直接给了排序一个参考,输出时候直接输出下标就成!选标识也就变得很重要了!
习题
第二题:如何使用位逻辑运算(如与、或、移位)来实现位向量?
答案:小奶猫看了题目3遍硬是没看懂是啥意思,只好看答案了。后来根据答案推他题目中的意思是这样的:有一个整数数组,现在希望把指定下标的整数的某一个位方便的置0或者1,而这某一个位是指所有整数数组换算成位后,从右往左计数的第i个位。比如整数数组是{1,2,3},要把2这个整数中的右起第3个位置1或者清零,因为数组中2在3的左边,3这个整数是32位的,所有i=32+3=35位。题目就变成,把这个数组的35位清零,怎么办?反过来看,那就先分块,每个整数看成一个块,计算好i是某个整数中的第几个位,然后置1或者清零。
如何确定在哪个整数中?想想是不是用i除以32取得的商就是这个整数的下标?是的。那用位操作怎么实现?我们知道一个数乘以2的n次方是把这个数在位上左移n位即可。那除以32呢?对,右移动5位(2的5次方是32),即i>>5。
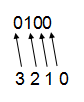
如何确定整数中的哪个位?想想是不是用i除以32取得的余数就是整数中的那个位?是的。举个例子,5用位表示为0101,4用位表示为0100,那5除以4的余数是多少?从右往左从0开始计算(见下图),4的第2位为1,那么把5的从第2位(从右往左)向左全部置0即可,得到的结果就是余数。怎么把从第2位开始向左全部
4000
置0?与0011相与。那这样推算,要除以32取余数,就是与00011111相与,00011111记成16进制为0x1F。
如何置1?指定位与1做或操作,基本功!
如何清零?指定位与0做与操作,又是基本功吧!
1《《n的意思很明确,就是把第n位置1,其他位都是0,然后和其他需要第n位改变的数进行置1或者清零操作。
下面再看答案给的代码,相信你能明白!
#define BITSPERWORD 32 //表示一个整型含有32个bit
#define SHIFT 5 //单位位移量
#define MASK 0x1F //掩码
#define N 10000000 //表示有1000万个数
int a[1+N/BITSPERWORD] //使用整型数组模拟定义1000万个位的数组
//i>>SHIFT指的是右移5位,也就是除以32,指的是该位存在于那个数组中
//i&MASK指的是i%32,剩下的数字为多少,1<<(i&MASK))表示1左移i&MASK位
void set(int i){a[i>>SHIFT]|=(1<<(i&MASK));}
void clr(int i){a[i>>SHIFT]&=~(1<<(i&MASK));}
int test(int i){return a[i>>SHIFT]&(1<<(i&MASK));}第四题:面对生成小于n且没有重复的k个整数的问题,最简单的方法就是使用前k个正整数。这个极端的数据集合将不会明显地改变位图方法的运行时间,但是可能会歪曲系统排序的运行时间。如何生成位于0至n-1之间的k个不同的随机顺序的随机整数?尽量使你的程序简短而高效。
答案:小奶猫觉得这个问题出的比较BT,因为随机采样单独就是一章,在第一章就出这样的习题确实让人找不到比较好的算法思路。后来小奶猫看了《编程珠玑》的第十二章,直接把这个问题解决了。有兴趣的可以直接跳到第十二章,总结一下了再回来看这个题目。还可以搜索“蓄水池抽样”。
第五题:那个程序员说他有1MB的可能存储空间,但是我们概要描述的代码需要1.25MB的空间。他可以不费力气地索取到额外的控件。如果1MB控件是严格的边界,你会推荐如何处理呢?你的算法的运行时间又是多少?
答案:就是书中所说的多趟排序,三种解决方案的第二种!关键点在于用时间换空间。
趣味题
本书第一章令小奶猫想起研究生面试时候的一道常出现题:你能不能把1到1000万内缺少的一个数找出来,越快越好!小奶猫当初看懂题目的时候给出的解决方案是这样的:还用想?直接把1到1000万全部加起来记作A,把给定的少一个数的输入加起来记作B,用A-B得到缺少的那个数。后来老师说这样做思维很好,但是没想过越界问题!那要是缺两个数呢?三个呢?更多呢?是不是还得列方程?恩!现在看来,答案很轻松就能想到了吧!


相关文章推荐
- 在语文湿地,潜伏着这样一个妈
- 动易2006序列号破解算法公布
- 常用生活小窍门
- 生活小常识(非常实用)
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析