嘉云数据电话面试详解
2015-07-30 19:25
615 查看
1.java中arraylist和linkedlist的区别和联系。
ArrayList和LinkedList在性能上各 有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
2.在ArrayList的 中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
3.LinkedList不 支持高效的随机元素访问。
4.ArrayList的空 间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
2.java中hashmap和treemap的区别。
3.java中static,final的作用
1、static 关键字:可以用于修饰属性,也可以用于修饰方法,还可以用于修饰类。
2、static 修饰属性:无论一个类生成了多少个对象,所有这些对象共同使用唯一一份静态的成员变量;一个对象对该静态成员变量进行了修改,其他对象的该静态成员变量的值也会随之发生变化。如果一个成员变量是static 的,那么我们可以通过 类名 .成员变量名 成员变量名
成员变量名 的方式来使用它 的方式来使用它 (推荐使用这种方式) 。
3、static修饰方法: static 修饰的方法叫做静态。 对于静态方法来说,可以 使用 类名 .方法名的方式来访问。
4、静态方法只能继承,不重写(Override)
5、不能在静态方法中访问非静态成员变量;
6、不能在静态方法中使用this关键字。
final的作用随着所修饰的类型而不同
1、final修饰类中的属性或者变量
无论属性是基本类型还是引用类型,final所起的作用都是变量里面存放的“值”不能变。
这个值,对于基本类型来说,变量里面放的就是实实在在的值,如1,“abc”等。
而引用类型变量里面放的是个地址,所以用final修饰引用类型变量指的是它里面的地址不能变,并不是说这个地址所指向的对象或数组的内容不可以变,这个一定要注意。
例如:类中有一个属性是final Person p=new Person("name"); 那么你不能对p进行重新赋值,但是可以改变p里面属性的值,p.setName('newName');
final修饰属性,声明变量时可以不赋值,而且一旦赋值就不能被修改了。对final属性可以在三个地方赋值:声明时、初始化块中、构造方法中。总之一定要赋值。
2、final修饰类中的方法
作用:可以被继承,但继承后不能被重写。
3、final修饰类
作用:类不可以被继承。
思考一个有趣的现象:
byte b1=1;
byte b2=3;
byte b3=b1+b2;//当程序执行到这一行的时候会出错,因为b1、b2可以自动转换成int类型的变量,运算时java虚拟机对它进行了转换,结果导致把一个int赋值给byte-----出错
如果对b1 b2加上final就不会出错
final byte b1=1;
final byte b2=3;
byte b3=b1+b2;//不会出错,相信你看了上面的解释就知道原因了。
4.java中volitale的作用
volatile让变量每次在使用的时候,都从主存中取。而不是从各个线程的“工作内存”。
volatile具有synchronized关键字的“可见性”,但是没有synchronized关键字的“并发正确性”,也就是说不保证线程执行的有序性。
也就是说,volatile变量对于每次使用,线程都能得到当前volatile变量的最新值。但是volatile变量并不保证并发的正确性。
5.git的使用
git是一个分布式版本控制系统,不同类型的版本控制软件还有svn,mercurial,vss,SourceAnywhere等。而Github是一个集成了git的服务。它可以以网页或者客户端的形式,帮助用户把git本地的数据提交到远程的服务器里。同样的服务还有git
oschina,git 京东,git csdn。这些服务都是免费的。
Github
is a host which stores many repos, people using git can put their projects on it. Git is a software. You can use it for version control. You can also use it without Github and just store your code locally.
6.一副扑克54张牌,现在分成3份,每份18张,问大小王出现在同一份中的概率是多少?
7.有一个函数fun能返回0和1两个值,返回0和1的概率都是1/2,问怎么利用这个函数得到另一个函数fun2,使fun2也只能返回0和1,且返回0的概率为0.3,返回1的概率为0.7。
分析:
Nathan 16:42:59
随机生成长度为4的01串
0000~1111每个串出现的概率都为1/16
Nathan 16:44:28
如果生成的串为0000 0001 0010之一,则返回0
Nathan 16:45:45
如果生成的串为0011 0100 0101 0110 0111 1000 1001则返回1(共七个串)
否则,递归,重新来过
代码:
[cpp] view
plaincopy
int func2()
{
int n = 0;
int v0 = fun();
int v1 = fun();
int v2 = fun();
int v3 = fun();
n |= v0;
n |= (v1<<1);
n |= (v2<<2);
n |= (v3<<3);
if(n <= 2) return 0;//0, 1, 2
else if(n <= 9) return 1;//3, 4, 5, 6, 7, 8, 9
return func2();
}
8.k-means算法的过程。
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:
(1)第一步是为待聚类的点寻找聚类中心
(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去
(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止
9.svm算法的过程
支持向量机(SVM)算法
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
具体原理:
1. 在n维空间中找到一个分类超平面,将空间上的点分类。如下图是线性分类的例子。
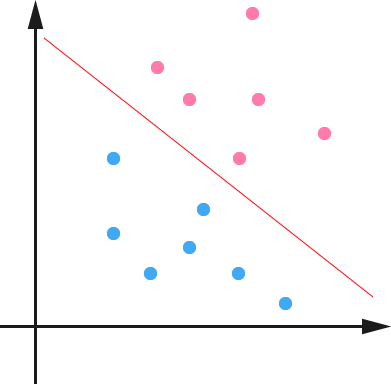
2. 一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。SVM就是要最大化这个间隔值。而在虚线上的点便叫做支持向量Supprot Verctor。


3. 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如下图);
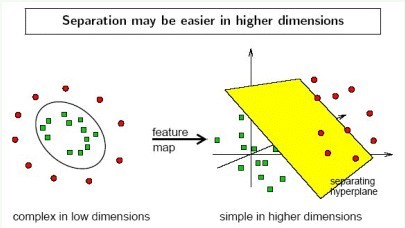
3. 线性不可分映射到高维空间,可能会导致维度大小高到可怕的(19维乃至无穷维的例子),导致计算复杂。核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
4.使用松弛变量处理数据噪音

SVM的优点:
1. SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
2. 假设现在你是一个农场主,圈养了一批羊群,但为预防狼群袭击羊群,你需要搭建一个篱笆来把羊群围起来。但是篱笆应该建在哪里呢?你很可能需要依据牛群和狼群的位置建立一个“分类器”,比较下图这几种不同的分类器,我们可以看到SVM完成了一个很完美的解决方案。

这个例子从侧面简单说明了SVM使用非线性分类器的优势,而逻辑模式以及决策树模式都是使用了直线方法。
10.决策树理论及其剪枝
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑(声明:此决策树纯属为了写文章而YY的产物,没有任何根据,也不代表任何女孩的择偶倾向,请各位女同胞莫质问我^_^):

上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,橙色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
有了上面直观的认识,我们可以正式定义决策树了:
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。知道了决策树的定义以及其应用方法,下面介绍决策树的构造算法。
不同于贝叶斯算法,决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍ID3和C4.5两种常用算法。
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
=-\sum%20^m_{i=1}p_ilog_2(p_i))
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
=\sum%20^v_{j=1}\frac{|D_j|}{|D|}info(D_j))
而信息增益即为两者的差值:
=info(D)-info_A(D))
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:

其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
=-0.7log_20.7-0.3log_20.3=0.7*0.51+0.3*1.74=0.879)
=0.3*(-\frac{0}{3}log_2\frac{0}{3}-\frac{3}{3}log_2\frac{3}{3})+0.4*(-\frac{1}{4}log_2\frac{1}{4}-\frac{3}{4}log_2\frac{3}{4})+0.3*(-\frac{1}{3}log_2\frac{1}{3}-\frac{2}{3}log_2\frac{2}{3})=0+0.326+0.277=0.603)
=0.879-0.603=0.276)
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:

在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain
ratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法首先定义了“分裂信息”,其定义可以表示成:
=-\sum%20^v_{j=1}\frac{|D_j|}{|D|}log_2(\frac{|D_j|}{|D|}))
其中各符号意义与ID3算法相同,然后,增益率被定义为:
=\frac{gain(A)}{split\_info(A)})
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
在决策树构造过程中可能会出现这种情况:所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:
先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。
ArrayList和LinkedList在性能上各 有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
2.在ArrayList的 中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
3.LinkedList不 支持高效的随机元素访问。
4.ArrayList的空 间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
2.java中hashmap和treemap的区别。
HashMap和TreeMap其实他们的父类都是Map接口。 HashMap底层数据结构是:Hash算法,输出顺序也是根据Hash算法来的。 TreeMap底层是二叉树,有自然顺序,也可进行实现Comparator接口进行排序。
3.java中static,final的作用
1、static 关键字:可以用于修饰属性,也可以用于修饰方法,还可以用于修饰类。
2、static 修饰属性:无论一个类生成了多少个对象,所有这些对象共同使用唯一一份静态的成员变量;一个对象对该静态成员变量进行了修改,其他对象的该静态成员变量的值也会随之发生变化。如果一个成员变量是static 的,那么我们可以通过 类名 .成员变量名 成员变量名
成员变量名 的方式来使用它 的方式来使用它 (推荐使用这种方式) 。
3、static修饰方法: static 修饰的方法叫做静态。 对于静态方法来说,可以 使用 类名 .方法名的方式来访问。
4、静态方法只能继承,不重写(Override)
5、不能在静态方法中访问非静态成员变量;
6、不能在静态方法中使用this关键字。
final的作用随着所修饰的类型而不同
1、final修饰类中的属性或者变量
无论属性是基本类型还是引用类型,final所起的作用都是变量里面存放的“值”不能变。
这个值,对于基本类型来说,变量里面放的就是实实在在的值,如1,“abc”等。
而引用类型变量里面放的是个地址,所以用final修饰引用类型变量指的是它里面的地址不能变,并不是说这个地址所指向的对象或数组的内容不可以变,这个一定要注意。
例如:类中有一个属性是final Person p=new Person("name"); 那么你不能对p进行重新赋值,但是可以改变p里面属性的值,p.setName('newName');
final修饰属性,声明变量时可以不赋值,而且一旦赋值就不能被修改了。对final属性可以在三个地方赋值:声明时、初始化块中、构造方法中。总之一定要赋值。
2、final修饰类中的方法
作用:可以被继承,但继承后不能被重写。
3、final修饰类
作用:类不可以被继承。
思考一个有趣的现象:
byte b1=1;
byte b2=3;
byte b3=b1+b2;//当程序执行到这一行的时候会出错,因为b1、b2可以自动转换成int类型的变量,运算时java虚拟机对它进行了转换,结果导致把一个int赋值给byte-----出错
如果对b1 b2加上final就不会出错
final byte b1=1;
final byte b2=3;
byte b3=b1+b2;//不会出错,相信你看了上面的解释就知道原因了。
4.java中volitale的作用
volatile让变量每次在使用的时候,都从主存中取。而不是从各个线程的“工作内存”。
volatile具有synchronized关键字的“可见性”,但是没有synchronized关键字的“并发正确性”,也就是说不保证线程执行的有序性。
也就是说,volatile变量对于每次使用,线程都能得到当前volatile变量的最新值。但是volatile变量并不保证并发的正确性。
5.git的使用
git是一个分布式版本控制系统,不同类型的版本控制软件还有svn,mercurial,vss,SourceAnywhere等。而Github是一个集成了git的服务。它可以以网页或者客户端的形式,帮助用户把git本地的数据提交到远程的服务器里。同样的服务还有git
oschina,git 京东,git csdn。这些服务都是免费的。
Github
is a host which stores many repos, people using git can put their projects on it. Git is a software. You can use it for version control. You can also use it without Github and just store your code locally.
6.一副扑克54张牌,现在分成3份,每份18张,问大小王出现在同一份中的概率是多少?
解答1:
54张牌分成3等份,共有M=(C54取18)*(C36取18)*(C18取18)种分法。
其中大小王在同一份的分法有N=(C3取1)*(C52取16)*(C36取18)*(C18取18)种。
因此所求概率为P=N /M=17/53。
解答2:
不妨记三份为A、B、C份。大小王之一肯定在某一份中,不妨假定在A份中,概率为1/3。然后A份只有17张牌中可能含有另一张王,而B份、C份则各有18张牌可能含有另一张王,因此A份中含有另一张王的概率是17/(17+18+18)=17/53。
也因此可知,A份中同时含有大小王的概率为1/3 * 17/53。
题目问的是出现在同一份中的概率,因此所求概率为3*(1/3 * 17/53)=17/53。
7.有一个函数fun能返回0和1两个值,返回0和1的概率都是1/2,问怎么利用这个函数得到另一个函数fun2,使fun2也只能返回0和1,且返回0的概率为0.3,返回1的概率为0.7。int func2()
{
int n = 0;
int v0 = fun();
int v1 = fun();
n |= v0;
n |= (v1<<1);
if(n == 1) return 0;//0
else if(n == 2) return 1;//1
return func2();
}有一个函数fun能返回0和1两个值,返回0和1的概率都是1/2,问怎么利用这个函数得到另一个函数fun2,使fun2也只能返回0和1,且返回0的概率为0.3,返回1的概率为0.7。分析:
Nathan 16:42:59
随机生成长度为4的01串
0000~1111每个串出现的概率都为1/16
Nathan 16:44:28
如果生成的串为0000 0001 0010之一,则返回0
Nathan 16:45:45
如果生成的串为0011 0100 0101 0110 0111 1000 1001则返回1(共七个串)
否则,递归,重新来过
代码:
[cpp] view
plaincopy
int func2()
{
int n = 0;
int v0 = fun();
int v1 = fun();
int v2 = fun();
int v3 = fun();
n |= v0;
n |= (v1<<1);
n |= (v2<<2);
n |= (v3<<3);
if(n <= 2) return 0;//0, 1, 2
else if(n <= 9) return 1;//3, 4, 5, 6, 7, 8, 9
return func2();
}
8.k-means算法的过程。
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:
(1)第一步是为待聚类的点寻找聚类中心
(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去
(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止
9.svm算法的过程
支持向量机(SVM)算法
支持向量机(support vector machine)是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
具体原理:
1. 在n维空间中找到一个分类超平面,将空间上的点分类。如下图是线性分类的例子。
2. 一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。SVM就是要最大化这个间隔值。而在虚线上的点便叫做支持向量Supprot Verctor。
3. 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如下图);
3. 线性不可分映射到高维空间,可能会导致维度大小高到可怕的(19维乃至无穷维的例子),导致计算复杂。核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
4.使用松弛变量处理数据噪音
SVM的优点:
1. SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
2. 假设现在你是一个农场主,圈养了一批羊群,但为预防狼群袭击羊群,你需要搭建一个篱笆来把羊群围起来。但是篱笆应该建在哪里呢?你很可能需要依据牛群和狼群的位置建立一个“分类器”,比较下图这几种不同的分类器,我们可以看到SVM完成了一个很完美的解决方案。
这个例子从侧面简单说明了SVM使用非线性分类器的优势,而逻辑模式以及决策树模式都是使用了直线方法。
10.决策树理论及其剪枝
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑(声明:此决策树纯属为了写文章而YY的产物,没有任何根据,也不代表任何女孩的择偶倾向,请各位女同胞莫质问我^_^):
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,橙色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
有了上面直观的认识,我们可以正式定义决策树了:
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。知道了决策树的定义以及其应用方法,下面介绍决策树的构造算法。
3.3、决策树的构造
不同于贝叶斯算法,决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍ID3和C4.5两种常用算法。
3.3.1、ID3算法
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
而信息增益即为两者的差值:
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
3.3.2、C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gainratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法首先定义了“分裂信息”,其定义可以表示成:
其中各符号意义与ID3算法相同,然后,增益率被定义为:
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
3.4、关于决策树的几点补充说明
3.4.1、如果属性用完了怎么办
在决策树构造过程中可能会出现这种情况:所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
3.4.2、关于剪枝
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。

相关文章推荐
- 黑马程序员-----OC学习之类与对象
- 教你如何迅速秒杀掉:99%的海量数据处理面试题
- 程序员加入新团队的那些坑
- 黑马程序员------oc foundation结构框架
- 面试题:在字符串中找到第一个不相同的,并输出
- 面试题:空格替换字符
- 面试题—— 从尾到头打印链表
- 【剑指Offer面试题】 九度OJ1519:合并两个排序的链表
- 程序员的恋情
- 黑马程序员--应用:用指针变量作为函数的参数,求出10个数的最大值
- 程序员面试宝典知识点笔记
- 黑马程序员 日记(十)
- 黑马程序员 日记(九)
- 黑马程序员 日记(八)
- 单链表面试题
- 黑马程序员-面试题(一)-交通灯管理系统
- 面试中发现的不足点
- 面试官最想听哪些话?
- ios面试总结
- 程序员的出路在哪里