CUDA 中解决 critical section 的一些策略
2015-07-29 20:03
162 查看
1. 问题陈述
原子操作是多线程编程中经常遇到的问题,对此 CUDA 中也提供了一些基本的函数,例如 atomicAdd() 可以完成对一个元素的原子操作,例如常见的累加,比如统计直方图中对每一个灰度值的累加,如下所示,CPU 端执行的统计直方图,array 是一个图像数组,max 是图像中像素个数,bin 是一个 256 个元素的数组,分别统计灰度值为 0-255 的元素个数。for (unsigned int i = 0; i< max; i++)
{
bin[array[i]]++;
}上述
bin[array[i]]++的具体过程如下所示:
从 array[i] 读取一个像素放入寄存器
计算 bin 中对应的基地址和偏移地址
提取 bin 中该位置的元素
对该值进行加 1
将该新值写入刚才 bin 中提取的位置
如果是单线程,上述代码不会有问题,但是如果多个线程要对同一个位置进行累加,比如有两个线程要完成 bin[100] 的加 1,假设此时 bin[100] = 200,那么很可能出现两个线程都从 bin[100] 中取得值 200,加1 得 201,然后依次写入 bin[100],导致此时 bin[100] 的值为 201 而不是 202。而通过原子操作,只有线程 1 执行完上述操作之后线程2才会执行,避免冲突。
针对简单的累加问题可以通过原子操作来完成,但是如果更多的操作呢,比如将数据合并,如下所示,bin 用来统计个数,binIdx 的每行用来记录相同值对应的索引,也就是说:bin[key] 对应 array 中值为 key 的个数,binIdx 的第 key 行对应这些值为 key 的索引,此时简单的原子操作将无法解决下述问题。
for (unsigned int i = 0; i < max; i++)
{
bin[array[i]]++;
binIdx[array[i]][bin[array[i]]] = i;
}还有一种情况,不同统计个数,只是想要将同一类别的连续存放,比如聚类之后的数据都会有类别标签,比如 1,2,3,… ,K,如何把同一类的标签的数据放在一起,这个问题与上述问题类似,在后面的部份会介绍。
上述的问题可以叫做
critical section,可以通过自己写锁的方式解决,但是此处没有这样做,是考虑几个问题:
过多的原子操作可能导致算法的串行化,严重影响效率,不让说直方图中相同值比较多的时候。
操作不当可能导致死锁
写锁比较麻烦
2. 合并同类数据
如下图所示,为聚类之后的数据,每一行表示一个样本,左侧表示的是在内存中的位置索引,右侧表示的是标签,也就是属于哪一类;右图表示合并之后的数据,同一类的放在内存中的连续区域。
针对上述问题的一种算法思路为:
统计每种标签的样本个数,与统计直方图类似
对统计出的结果进行累加求和,也就是前缀和,得到每个类别的起始位置
重新统计每种标签的个数,但是在统计的时候标记样本属于第几个,以便合并的时候放到正确的位置。
将数据放到正确的位置
上述过程的 1,2,4 步都没有问题,但是第 3 步就与 第 1 部份陈述的问题类似了,如果在累加的同时又记录索引。
对此可以有一种曲线救国的方式,借助排序来避免原子操作。具体来说就是借助 thrust 库的并行排序算法:
thrust::sort_by_key(),针对上图来说就是对标签进行排序,同时标签对应的位置与标签一一对应,也就是对标签进行排序的同时位置索引也响应的排序。
排序之前为:
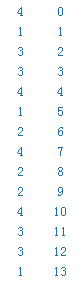
排序之后为:

此时我们也就得到了如下的映射关系:

其中第一个坐标表示映射后的位置索引,第二个表示映射之前的位置索引,为一一映射关系,并行性很高。另外,由于标签的范围有限,可以使用并行的计数排序或者基数排序,进而快速建立映射关系。
3. 并行目标识别问题
如下图所示,红色的表示检测到的目标,如何在 CUDA 中保存目标的位置信息呢,与数据合并类似,不能通过简单的原子操作来解决。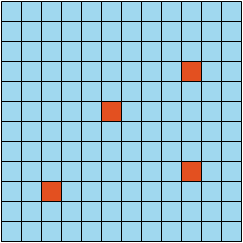
针对上述问题,可以将要处理的问题转到 CPU 端处理,但是这样的效率太低,对此我们可以使用一种折中的策略,

通过一个行向量表示改行有几个目标,一个列向量表示该列有几个目标,然后将这两个向量也拷贝出内存,进而有效的提高检测效率,针对上述 12 x 12 的矩阵,检测效率可以提高 10 倍以上。
当然,依旧可以将上述问题转换为第 2 部份所述的问题,有目标为 0,无目标为 1,然后进行排序,合并,但是此时的效率可能不高(针对少数目标的情况,存在很多无用计算)。
4. 参考
《CUDA Programming A Developer–‘s Guide to Parallel Computing with GPUs》A PRACTICAL EXAMPLE HISTOGRAMS《计数排序及并行实现》

相关文章推荐
- 基于oracle中锁的深入理解
- C#多线程编程中的锁系统(三)
- Redis数据库中实现分布式锁的方法
- C#多线程编程中的锁系统基本用法
- PHP通过插入mysql数据来实现多机互锁实例
- Java锁之阻塞锁介绍和代码实例
- Mysql数据库锁定机制详细介绍
- python多线程threading.Lock锁用法实例
- python开启多个子进程并行运行的方法
- 单核,多核CPU的原子操作
- 自旋锁学习系列(3):指数后退技术
- 用python做GPU计算(1)——安装以及配置
- 一篇不错的对于乐观锁和悲观锁的解释帖子
- Android 锁屏和黑屏的广播消息
- 行记录被锁
- Iphone 音频总结
- GPU(CUDA)学习日记(三)------ CUDA基本架构介绍以及编程入门!
- ORACLE 的锁
- 读写锁(Read-Write Lock)的一种实现