神经网络-并行BP算法
2015-07-31 23:11
417 查看
1. 说明
如果对神经网络中的 BP 算法已经十分熟悉,可以直接阅读此文,否则可以参考之前的两篇文章:1. 神经网络(Neural Networks,NN)推导
2. 神经网络-文本识别
本文的主要工作是将上述两篇文章中的 BP (后向传播算法)并行化,以提高计算效率。
平台:
1. CPU:i7 4790k
2. GPU:Nvidia GTX980
3. Matlab 2014a
4. CUDA 6.5
2. BP 的并行化思路
首先应用 神经网络-文本识别 中的 BP 算法的一个迭代内循环。% 取一个样本 oneIn = inputn(:, n); oneOut = output_train(:, n); % 隐藏层输出 hOut = 1 ./ (1 + exp(- W10 * oneIn)); % 输出层输出 yOut = W21 * hOut; % 计算误差 eOut = oneOut - yOut; % 计算输出层误差项 delta2 delta2 = eOut; % 计算隐藏层误差项 delta1 FI = hOut .* (1 - hOut); delta1 = (FI .* (W21' * eOut)); % 更新权重 W21 = W21 + eta * delta2 * hOut'; W10 = W10 + eta * delta1 * oneIn';
从上述代码中可以看出 BP 算法中存在大量的矩阵乘法,点乘,以及对矩阵的点运算,这是非常适合并行处理的,另一方面,上述代码一次只取出了一个样本进行权重学习,实际上可以借鉴分布式的方案,多个样本同时进行权重学习,最后求平均,如下所示:
% 取多个样本 manyIn = inputn_train(:, n:n+step-1); manyOut = output_train(:, n:n+step-1); % 隐藏层输出 hOut = 1 ./ (1 + exp(- W10 * manyIn)); % 输出层输出 yOut = W21 * hOut; % 计算误差 eOut = manyOut - yOut; % 计算输出层误差项 delta2 delta2 = eOut; % 计算隐藏层误差项 delta1 FI = hOut .* (1 - hOut); delta1 = (FI .* (W21' * eOut)); % 更新权重 W21 = W21 + eta / step * delta2 * hOut'; W10 = W10 + eta / step * delta1 * manyIn';
上述过程中一次批处理样本的个数与计算时间和测试精度的关系如下所示(重每个batch重复 10 次实验,每次的初始权重随机产生):
| step | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|---|
| 时间 | 8.504s | 5.536s | 3.024s | 1.865s | 1.108s | 0.843s | 0.756s | 0.621s |
| 准确率 | 0.9086 | 0.9096 | 0.9123 | 0.9153 | 0.9255 | 0.9233 | 0.9152 | 0.9041 |
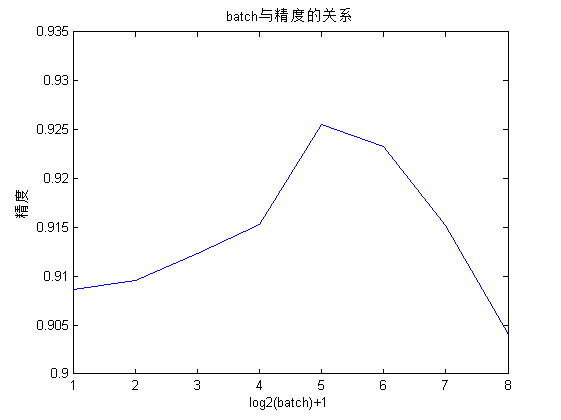
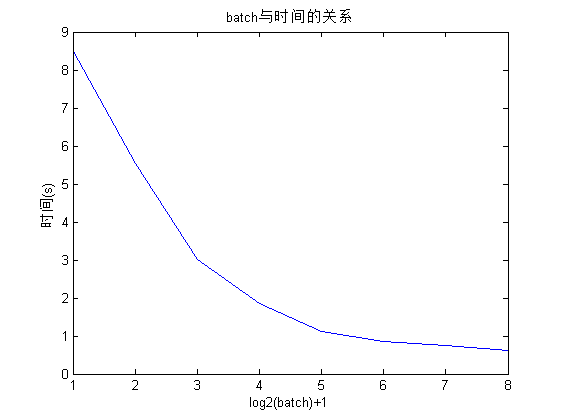
从上可以看出,随着批处理的样本数的增加,重构时间逐渐减小,但是减小的趋势也在逐渐变换;另外,精度先增高后降低。由此我们可以得出结论:
选择合适的批处理样本数即可以减小权重学习的时间,又可以适当的增加权重学习的精度。
3. BP 的并行性分析
隐藏层的输出计算可以转换为一个矩阵的乘法WH×I∗XI×B 和一个矩阵的点运算。其中,H 表示隐藏层的神经元数,I 表示输入层的神经元数,B 表示一次批处理的个数。
输出层输出的计算
可以转换为一个矩阵的乘法WO×H∗HideH×B。其中 O 表示输出层的神经元个数。
计算误差或者说计算 delta2
可以看作一个矩阵的减法运算矩阵大小为 O x B
计算隐藏层误差项 delta1
可以看作一个矩阵的乘法WO×HT∗delta2O×B以及两个矩阵的点乘运算。
更新权重
两个权重的更新都可以看作一个矩阵的乘法,一个矩阵的尺度变换,一个矩阵的加法。
综上所示,上述过程的并行性很高,适合与并行优化。
按照上述思路,对 BP 算法进行了并行化处理,但是加速只有几倍,相较于 Kmeas 的 345 倍计算过于不理想,因此对其进行分析。
上述过程中的主要运算是矩阵乘法,但是神经网络神经元个数的影响,矩阵的维度都较小,例如第 1 步中的 W32×401∗X401×32,利用常规矩阵并行化的处理方式,开辟的线程数为 32x32=1024个,还不到 GTX 980 的一般线程,另外,由于使用的线程块的大小为 16x16=256,而一个线程块都在一个 SM 中,也就是说上述矩阵乘法只使用了 4 个 SM(总共16个,每个 SM 的线程数为 64),也就是说只使用了 1/8 的线程,计算效率必定不高;再看第 4 步中的W10×32T∗delta210×32,依旧是这样的问题。因此我们可以得出结论:
对于神经元个数较少,或者批处理个数较少时可能无法得出理想的加速比,当神经元个数较多,批处理个数较多时,可以渴望得到更高的加速比。
当然,批处理的样本数越多,并行化的加速效果越明显,对此进行了两个对比实验,一个是批处理数为 32 的并行加速,一个是批处理数为 64 的并行加速,时间如下所示:
32:418 ms 64:235 ms
这也进一步验证的我的想法。
4. 一种矩阵乘法的优化
常规的矩阵都借鉴于 CUDA 官方文档中的分块方式,导致使用的线程个数为最终输出元素的个数,如下图所示。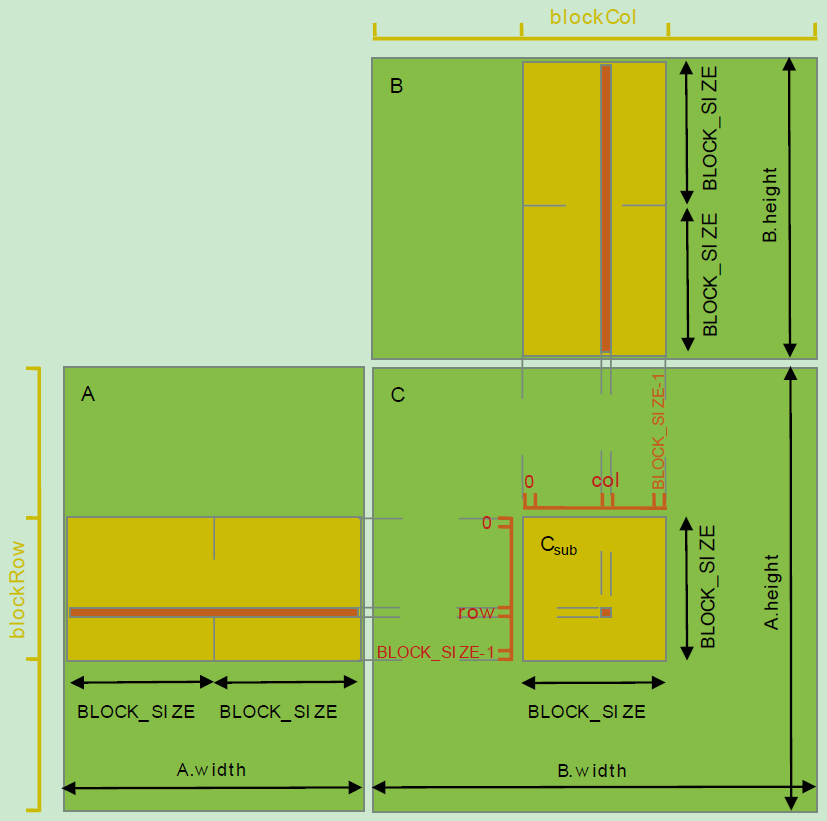
但是,对于 矩阵 A 的行数很小,而列数很大,B的矩阵行数很大,列数很小,会导致无法充分利用 GPU 资源,并且每个线程的计算量过大(A的一行和B的一列的内积),也就是说资源分配不均,正如第 3 部份出现的那样,如果按这种方式计算 32×401 的矩阵与 401×32 的矩阵的乘法,效率不高,因此此处对其进行优化。

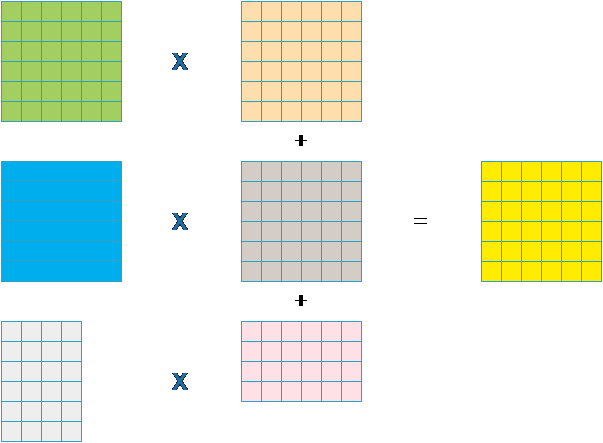
按照上述的方式分块,每个块完成 A 的一部分与 B 的一部分的乘法,然后进行累加。
经过上述修改,乘法的效率提高至少有三倍,整个代码的运行时间也大大减小:
优化前:418 ms 优化后:250 ms
5. 完整代码
我的 GitHub
相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- 也谈 机器学习到底有没有用 ?
- 用python做GPU计算(1)——安装以及配置
- 量子计算机编程原理简介 和 机器学习
- GPU(CUDA)学习日记(三)------ CUDA基本架构介绍以及编程入门!
- 基于神经网络的预测模型
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 关于机器学习的学习笔记(二):决策树算法
- 关于机器学习的学习笔记(三):k近邻算法
- 长期招聘:自然语言处理工程师
- 人工智能扫盲漫谈篇 & 2018年1月新课资源推荐