NVIDIA下代Pascal GPU架构提升深度学习速度
2015-07-24 17:59
633 查看
在4月15日,NVDIA(英伟达)在北京举行了“视觉计算 无处不在”的媒体分享会,在此次会议上,NVDIA向媒体介绍了NVDIA在深度学习技术上的成就。

深度学习指的是计算机使用神经网络自主学习的过程,在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域。
TITAN X 是NVDIA全新推出的旗舰级游戏显卡,但也特别适合用于深度学习。

在 TITAN X 上能以 4K 的超高画质呈现最新 AAA 游戏大作的瑰丽画面,可以在开启 FXAA 高设定值的情况下,以每秒40帧(40fps)运行《中土世界:暗影魔多》(Middle-earth: Shadow of Mordor)游戏,而在九月发行的 GeForce GTX 980 上则是以 30fps 来运行。
采用 NVIDIA Maxwell GPU 架构的 TITAN X,结合 3,072 个处理核心、单精度峰值性能为 7 teraflops,加上板载的 12GB 显存,在性能和性能功耗比方面皆是前代产品的两倍。
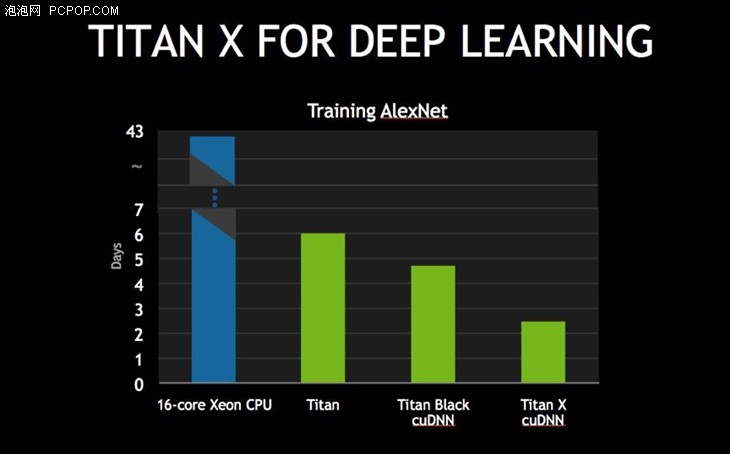
凭借强大的处理能力和 336.5GB/s 的带宽,让它能处理用于训练深度神经网络的数百万的数据。例如, TITAN X 在工业标准模型 AlexNet 上,花了不到三天的时间、使用 120万个 ImageNet 图像数据集去训练模型,而使用16核心的 CPU 得花上四十多天。
现已上市的GeForce GTX TITAN X 售价为 7999元人民币。
NVDIA预计于明年推出的 Pascal 架构 GPU 将使深度学习应用中的计算速度加快十倍。
Pascal 架构 GPU 的三大设计特色将大幅加快训练速度,精准地训练更丰富的深度神经网络,犹如人类大脑皮层的资料结构将成为深度学习研究的基础。
再加上 32GB 的显存(是NVIDIA 新发布的旗舰级产品 GeForce GTX TITAN X 的 2.7 倍),Pascal 架构可进行混合精度的计算任务。它将配备 3D 堆叠显存,提升深度学习应用程序的速度性能多达5倍;另搭配 NVIDIA 的高速互连技术 NVLink 来连接两个以上的 GPU,可将深度学习的速度提升达十倍。

混合精度计算 – 达到更精准的结果
混合精度计算让采用 Pascal 架构的 GPU 能够在 16 位浮点精度下拥有两倍于 32 位浮点精度下的速率的计算速度。
更出色的浮点计算性能特别提高了深度学习两大关键活动:分类和卷积的性能,同时又达到所需的精准度。
3D 堆叠显存 – 更快的传输速度和优秀的省电表现
显存带宽限制了数据向 GPU 传输的速度。采用 3D 堆叠显存将可提高比 Maxwell 架构高出三倍的带宽和近三倍的容量,让开发人员能建立更大的神经网络,大大提升深度学习训练中带宽密集型部分的速度。
Pascal 采用显存芯片逐个堆叠的技术,位置接近 GPU 而不是处理器板更往下的地方。如此就能把输出在显存与 GPU 间往返的距离从几英寸减缩到几毫米,大幅加快传输速度和拥有更好的省电表现。
NVLink – 更快的数据移动速度
Pascal 架构加入 NVLink 技术将使得 GPU 与 CPU 之间数据传输的速度,较现有的 PCI-Express
标准加快5到12倍,对于深度学习这些需要更高 GPU 间传递速度的应用程序来说是一大福音。
NVLink 可将系统里的 GPU 数量增加一倍,以共同用于深度学习计算任务上;还能以新的方式连接 CPU 与 GPU,在服务器设计方面提供较 PCI-E 更出色的灵活性和省电表现。
DIGITS:通往最佳深度神经网络的便捷之路
使用深度神经网络来训练电脑教自己如何分类和识别物体,是一件繁重又费时的事情。

DIGITS 深度学习 GPU 训练系统软件自始至终都将为用户提供所需数据,帮助用户建立最优的深度神经网络,改变上述的局面。
DIGITS 可在安装、配置和训练深度神经网络过程中为用户提供指导 – 处理复杂的工作好让科学家能专心在研究活动和结果上。
得益于其直观的用户界面和强大的工作流程管理能力,不论是在本地系统还是在网络上使用 DIGITS,准备和加载训练数据集都相当简单。
这是同类系统中首个提供实时监控和可视化功能的系统,用户可以对工作进行微调。它还支持 GPU 加速版本 Caffe,目前,这一框架在众多数据科学家和研究人员中都得到了广泛使用,用于构建神经网络。■
深度学习指的是计算机使用神经网络自主学习的过程,在人工智能领域快速成长的深度学习技术是一项创新的计算引擎,可应用在从先进医药研究到全自动驾驶汽车的多元领域。
TITAN X 是NVDIA全新推出的旗舰级游戏显卡,但也特别适合用于深度学习。
在 TITAN X 上能以 4K 的超高画质呈现最新 AAA 游戏大作的瑰丽画面,可以在开启 FXAA 高设定值的情况下,以每秒40帧(40fps)运行《中土世界:暗影魔多》(Middle-earth: Shadow of Mordor)游戏,而在九月发行的 GeForce GTX 980 上则是以 30fps 来运行。
采用 NVIDIA Maxwell GPU 架构的 TITAN X,结合 3,072 个处理核心、单精度峰值性能为 7 teraflops,加上板载的 12GB 显存,在性能和性能功耗比方面皆是前代产品的两倍。
凭借强大的处理能力和 336.5GB/s 的带宽,让它能处理用于训练深度神经网络的数百万的数据。例如, TITAN X 在工业标准模型 AlexNet 上,花了不到三天的时间、使用 120万个 ImageNet 图像数据集去训练模型,而使用16核心的 CPU 得花上四十多天。
现已上市的GeForce GTX TITAN X 售价为 7999元人民币。
NVDIA预计于明年推出的 Pascal 架构 GPU 将使深度学习应用中的计算速度加快十倍。
Pascal 架构 GPU 的三大设计特色将大幅加快训练速度,精准地训练更丰富的深度神经网络,犹如人类大脑皮层的资料结构将成为深度学习研究的基础。
再加上 32GB 的显存(是NVIDIA 新发布的旗舰级产品 GeForce GTX TITAN X 的 2.7 倍),Pascal 架构可进行混合精度的计算任务。它将配备 3D 堆叠显存,提升深度学习应用程序的速度性能多达5倍;另搭配 NVIDIA 的高速互连技术 NVLink 来连接两个以上的 GPU,可将深度学习的速度提升达十倍。
混合精度计算 – 达到更精准的结果
混合精度计算让采用 Pascal 架构的 GPU 能够在 16 位浮点精度下拥有两倍于 32 位浮点精度下的速率的计算速度。
更出色的浮点计算性能特别提高了深度学习两大关键活动:分类和卷积的性能,同时又达到所需的精准度。
3D 堆叠显存 – 更快的传输速度和优秀的省电表现
显存带宽限制了数据向 GPU 传输的速度。采用 3D 堆叠显存将可提高比 Maxwell 架构高出三倍的带宽和近三倍的容量,让开发人员能建立更大的神经网络,大大提升深度学习训练中带宽密集型部分的速度。
Pascal 采用显存芯片逐个堆叠的技术,位置接近 GPU 而不是处理器板更往下的地方。如此就能把输出在显存与 GPU 间往返的距离从几英寸减缩到几毫米,大幅加快传输速度和拥有更好的省电表现。
NVLink – 更快的数据移动速度
Pascal 架构加入 NVLink 技术将使得 GPU 与 CPU 之间数据传输的速度,较现有的 PCI-Express
标准加快5到12倍,对于深度学习这些需要更高 GPU 间传递速度的应用程序来说是一大福音。
NVLink 可将系统里的 GPU 数量增加一倍,以共同用于深度学习计算任务上;还能以新的方式连接 CPU 与 GPU,在服务器设计方面提供较 PCI-E 更出色的灵活性和省电表现。
DIGITS:通往最佳深度神经网络的便捷之路
使用深度神经网络来训练电脑教自己如何分类和识别物体,是一件繁重又费时的事情。
DIGITS 深度学习 GPU 训练系统软件自始至终都将为用户提供所需数据,帮助用户建立最优的深度神经网络,改变上述的局面。
DIGITS 可在安装、配置和训练深度神经网络过程中为用户提供指导 – 处理复杂的工作好让科学家能专心在研究活动和结果上。
得益于其直观的用户界面和强大的工作流程管理能力,不论是在本地系统还是在网络上使用 DIGITS,准备和加载训练数据集都相当简单。
这是同类系统中首个提供实时监控和可视化功能的系统,用户可以对工作进行微调。它还支持 GPU 加速版本 Caffe,目前,这一框架在众多数据科学家和研究人员中都得到了广泛使用,用于构建神经网络。■

相关文章推荐
- 架构方法论
- 给网站添加一个config.js,js无法声明常量,封装js变量取值器
- [前端架构]性能优化
- MMORPG服务器架构
- Exchange2010配置-实现邮箱服务器高可用
- 【工作笔记0003】网站真假分页个人观点
- 专搜电子书网站
- C/S架构和B/S架构比较
- Windows Server 2012 DHCP安装及高可用
- 一个网站基本完工后测试的几个步骤
- JS(javascript) 将网站加入收藏夹
- 嵌入在网站上Flash播放机(2)
- 开源网站网罗
- KVM虚拟化——架构及安装
- 【wordpress】wordpress学习网站
- 系统架构设计应考虑的因素
- .net mvc 下实现移动架构display mode
- 高并发大流量网站架构简单思路
- 镜像网站
- nopCommerce的源代码结构和架构