机器学习 之 LDA主题模型
2015-07-06 23:24
260 查看
今天终于开始啃LDA了,同时恶补一下概率分布方面的东西。
先放上来大神学习LDA的五个步骤:
1. 一个函数:gamma函数
2. 四个分布:二项分布、多项分布、beta分布、Dirichlet分布
3. 一个概念和一个理念:共轭先验和贝叶斯框架
4. 两个模型:pLSA、LDA
5. 一个采样:Gibbs采样
一种主题模型
将文档集中每篇文档的主题以概率的形式给出
可以用于主题聚类或分本分类
一种典型的词袋模型(一个文档有很多词,词是无序的)
一篇文档可以含有很多主题
文档的每个词都由一个主题生成
在LDA中,一篇文档是这样生成的:

β分布是二项式分布的共轭先验分布:观测到的数据符合二项分布,参数的先验分布和后验分布属于β分布的情况,就是Beta-Binomial共轭。换言之,Beta分布是二项式分布的共轭先验概率分布。
狄利克雷分布式多项式分布的共轭先验分布:观测到的数据符合多项式分布,参数的先验分布和后验分布属于狄利克雷分布的情况,就是Dirichlet-Multinomial共轭。换言之,狄利克雷分布式多项式分布的共轭先验分布。


Wn是文本中第n个词,p(Wn)表示这个词的先验概率。
这个模型假设文本中的词服从多项式分布,所以p是服从多项式分布的参数,而狄利克雷分布是多项式分布的先验分布,因此α服从狄利克雷分布。

具体如下:

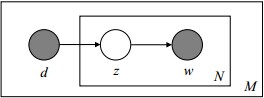
在pLSA中,文档d和词w是我们得到的样本,要推断未知的主题。(样本随机,参数未知但固定,频率派的思想)

求解的过程实在太复杂了,总结下来基本是这样:




先放上来大神学习LDA的五个步骤:
1. 一个函数:gamma函数
2. 四个分布:二项分布、多项分布、beta分布、Dirichlet分布
3. 一个概念和一个理念:共轭先验和贝叶斯框架
4. 两个模型:pLSA、LDA
5. 一个采样:Gibbs采样
LDA(Latent Dirichlet Allocation)
全称是隐含狄利克雷分布一种主题模型
将文档集中每篇文档的主题以概率的形式给出
可以用于主题聚类或分本分类
一种典型的词袋模型(一个文档有很多词,词是无序的)
一篇文档可以含有很多主题
文档的每个词都由一个主题生成
在LDA中,一篇文档是这样生成的:
四种概率分布
下面就分别介绍一下二项分布、多项式分布、β分布和狄利克雷分布。二项分布到多项式分布
二项分布是伯努利分布的扩展版本,多项式分布则又是二项分布的扩展版本。伯努利分布是一个离散型的随机分布,做一次实验,实验的结果只有两个,而二项分布则将实验次数扩展到了多个,而多项式分布则将实验的结果也扩展到了多个。β分布到狄利克雷分布
狄利克雷分布是β分布在高维度上的推广。共轭先验分布
在贝叶斯概率论中,如果后验概率P(θ|x)和先验概率p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。β分布是二项式分布的共轭先验分布:观测到的数据符合二项分布,参数的先验分布和后验分布属于β分布的情况,就是Beta-Binomial共轭。换言之,Beta分布是二项式分布的共轭先验概率分布。
狄利克雷分布式多项式分布的共轭先验分布:观测到的数据符合多项式分布,参数的先验分布和后验分布属于狄利克雷分布的情况,就是Dirichlet-Multinomial共轭。换言之,狄利克雷分布式多项式分布的共轭先验分布。
几个基础模型
一元文法统计模型(Unigram model)
Wn是文本中第n个词,p(Wn)表示这个词的先验概率。
这个模型假设文本中的词服从多项式分布,所以p是服从多项式分布的参数,而狄利克雷分布是多项式分布的先验分布,因此α服从狄利克雷分布。
Mixture of Unigram model
pLSA模型
pLSA的文档生成模型
pLSA生成文档的主要过程就是:先选定文档生成主题,再根据主题生成词。具体如下:
主题建模
利用看到的文档推断隐藏的主题的过程。在pLSA中,文档d和词w是我们得到的样本,要推断未知的主题。(样本随机,参数未知但固定,频率派的思想)
求解的过程实在太复杂了,总结下来基本是这样:
LDA
之前说到pLSA是频率派的思想,那么LDA就是贝叶斯派的思想。它认为主题分布和词分布也是不确定了,为了得到他们,需要用他们的先验分布(Dirichlet)来进行估计。所以,LDA的过程是这样的:pLSA与LDA的对比
概率图
参数估计方法

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 关于机器学习的学习笔记(二):决策树算法
- 关于机器学习的学习笔记(三):k近邻算法
- 长期招聘:自然语言处理工程师
- 长期招聘:个性化推荐
- 为什么需要一个推荐引擎平台
- 机器学习之决策树整理
- Kernel PCA